
引言
所有数据科学教程都将异常值检测描述得十分简单:移除所有大于3个标准差的值,仅此而已。但当你开始处理分布偏态的真实数据集,且相关方追问“你为什么要移除这个数据点?”时,你会突然发现自己无法给出合理答案。
因此我们开展了一项实验:在真实数据集(6497个葡萄牙葡萄酒样本)上测试了5种最常用的异常值检测方法,旨在探究:这些方法是否能得出一致结果?
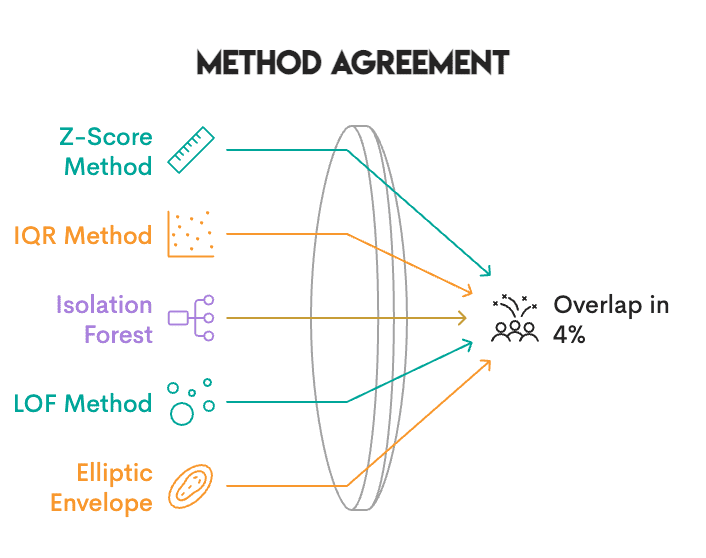
答案是否定的。而从这些分歧中我们学到的东西,比任何教科书上的知识都更有价值。
我们将这项分析制作成了交互式Strata笔记本,你可以利用StrataScratch上的数据项目,将该格式用于自己的实验。完整代码可点击此处查看和运行。
实验设置
我们的数据来自葡萄酒质量数据集,可通过加州大学欧文分校(UCI)机器学习仓库公开获取。该数据集包含6497个葡萄牙“维诺 verde”葡萄酒样本(1599个红葡萄酒样本,4898个白葡萄酒样本)的物理化学测量数据,以及品酒专家给出的质量评分。
我们选择该数据集的原因有三点:首先,它是真实生产数据,而非人工生成;其次,数据分布存在偏态(11个特征中有6个偏度大于1),不符合教科书假设;最后,质量评分可帮助我们验证检测出的“异常值”是否更多出现在评分异常的葡萄酒中。
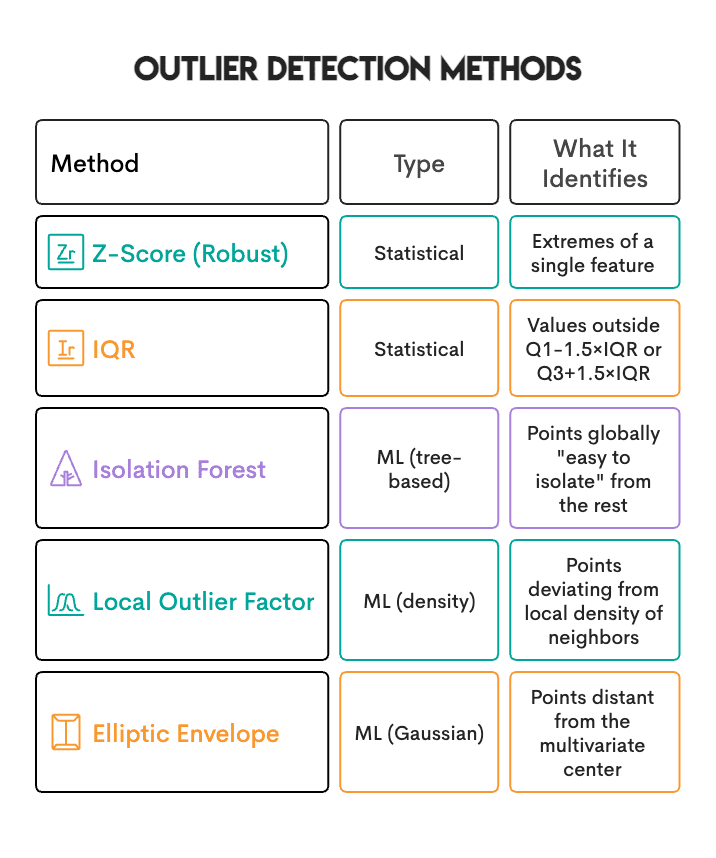
以下是我们测试的5种方法:
意外发现一:多重测试导致结果膨胀
在对比不同方法之前,我们遇到了一个难题。数据集包含11个特征,若采用简单方法(只要有一个特征出现极值就标记该样本为异常值),会导致结果严重膨胀。
四分位距(IQR)方法标记了约23%的葡萄酒为异常值,Z分数(Z-Score)方法标记了约26%。
当近四分之一的葡萄酒被标记为异常值时,显然存在问题——真实数据集不可能有25%的异常值。核心问题在于,我们对11个特征进行了独立测试,这导致结果被高估。
背后的数学逻辑很简单:如果每个特征出现“随机极值”的概率低于5%,那么对于11个独立特征,至少有一个特征出现极值的概率为:
通俗来说:即使每个特征都完全符合正态分布,仅因随机概率,你也会发现近一半的样本至少有一个特征出现极值。
为解决这一问题,我们修改了判定标准:仅当至少2个特征同时出现极值时,才将该样本标记为异常值。
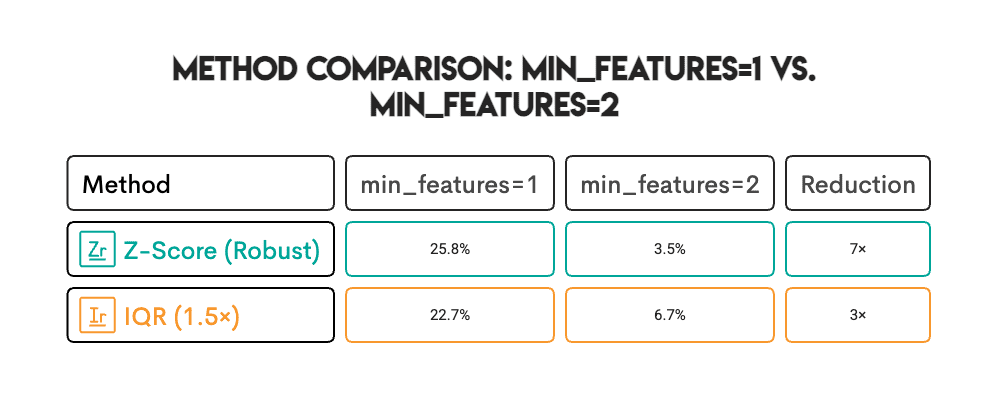
将“最小特征数”从1改为2,相当于将判定标准从“样本的任意一个特征为极值”调整为“样本在多个特征上均为极值”。
以下是修复该问题的代码:
outlier_counts = (np.abs(z_scores) > 3.5).sum(axis=1)
outliers = outlier_counts >= 2
5种方法在同一数据集上的对比
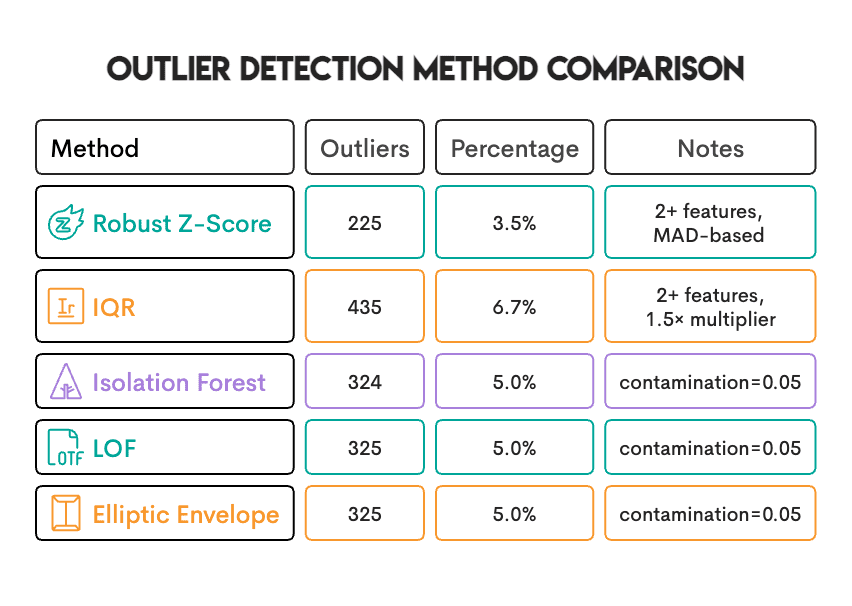
解决多重测试问题后,我们统计了每种方法标记的异常值样本数量:
以下是机器学习方法的设置代码:
from sklearn.ensemble import IsolationForest
from sklearn.neighbors import LocalOutlierFactor
iforest = IsolationForest(contamination=0.05, random_state=42)
lof = LocalOutlierFactor(n_neighbors=20, contamination=0.05)
为什么所有机器学习方法标记的异常值比例都恰好是5%?这是因为“污染度(contamination)”参数的作用——它要求方法必须标记固定比例的样本,这是一个“配额”,而非“阈值”。换句话说,无论你的数据中真实异常值比例是1%还是20%,孤立森林(Isolation Forest)都会标记5%的样本为异常值。
真正的差异:不同方法检测的是不同类型的异常
最让我们意外的是,当我们分析不同方法的一致性时发现,杰卡德相似度(Jaccard similarity)仅在0.10到0.30之间,一致性极差。
在6497个葡萄酒样本中:
仅32个样本(0.5%)被4种主要方法一致标记为异常值
143个样本(2.2%)被3种及以上方法标记为异常值
你可能会认为这是代码漏洞,但这正是问题的核心:每种方法对“异常”的定义都不同。
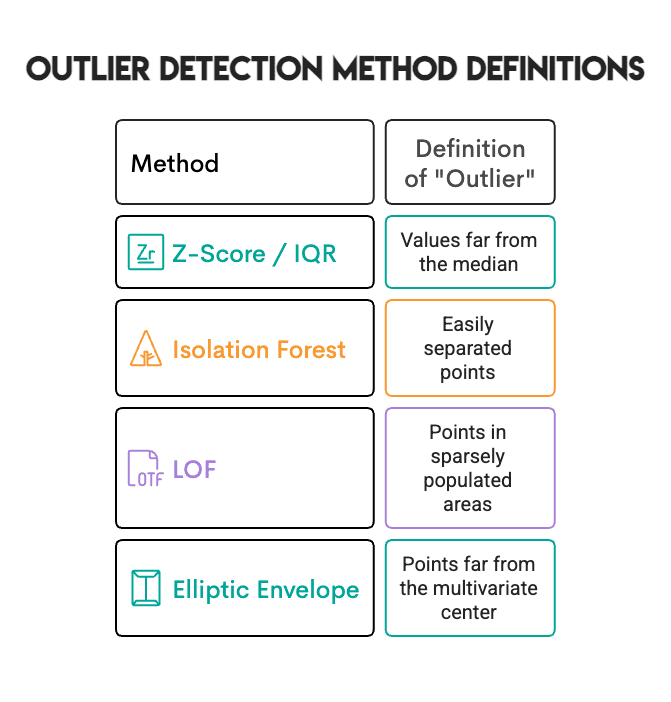
例如,若一款葡萄酒的残糖量显著高于平均值,它会被单变量异常值方法(Z分数/IQR)检测到;但如果它周围有许多残糖量相似的葡萄酒,局部异常因子(LOF)则不会标记它——因为在局部环境中,它是正常的。
因此,真正的问题不是“哪种方法最好?”,而是“我要寻找哪种类型的异常?”
合理性检验:异常值与葡萄酒质量是否相关?
该数据集包含专家给出的质量评分(3-9分)。我们想知道:检测出的异常值是否更频繁地出现在质量评分异常的葡萄酒中?

质量评分异常的葡萄酒,被所有方法一致标记为异常值的概率是普通葡萄酒的两倍。这是一个很好的合理性检验。在某些情况下,这种关联很明显:例如,挥发性酸度过高的葡萄酒会有醋味,评分较低,也会被标记为异常值——化学性质决定了这两种结果。但我们不能假设这能解释所有情况,可能存在我们未发现的模式,或未考虑到的混杂因素。
影响实验结果的三个关键决策
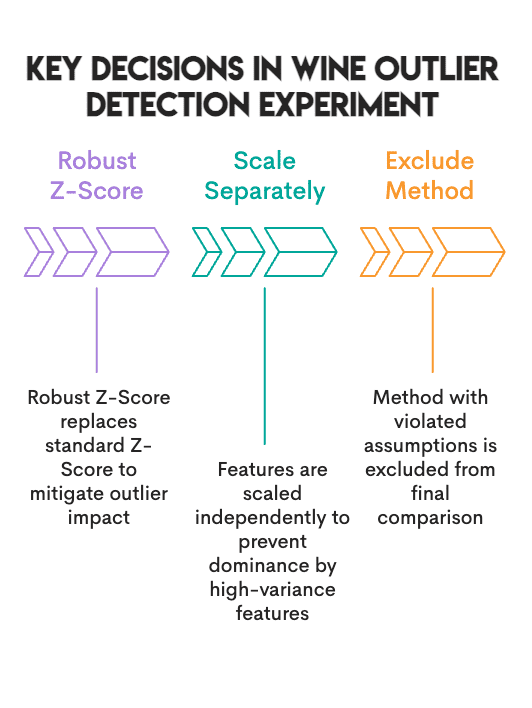
1. 使用稳健Z分数(Robust Z-Score)而非标准Z分数
标准Z分数使用数据的均值和标准差,而这两个统计量都会受到数据中异常值的影响。稳健Z分数则使用中位数和中位数绝对偏差(MAD),这两个统计量均不受异常值影响。
因此,标准Z分数仅识别出0.8%的数据为异常值,而稳健Z分数识别出3.5%的异常值。
median = np.median(data, axis=0)
mad = np.median(np.abs(data - median), axis=0)
robust_z = 0.6745 * (data - median) / mad
2. 红葡萄酒和白葡萄酒分开标准化
红葡萄酒和白葡萄酒的化学物质基准水平不同。例如,将红葡萄酒和白葡萄酒合并为一个数据集时,一款相对于其他红葡萄酒化学性质完全正常的红葡萄酒,仅因其硫含量与红、白葡萄酒合并后的均值对比,就可能被识别为异常值。
因此,我们分别使用每种葡萄酒类型的中位数和四分位距(IQR)对红、白葡萄酒进行标准化,然后再将两者合并。
from sklearn.preprocessing import RobustScaler
scaled_parts = []
for wine_type in ['red', 'white']:
subset = df[df['type'] == wine_type][features]
scaled_parts.append(RobustScaler().fit_transform(subset))
3. 明确何时排除某种方法
椭圆包络(Elliptic Envelope)方法假设数据服从多元正态分布,但我们的数据集并不满足这一条件——11个特征中有6个偏度超过1,其中一个特征的偏度高达5.4。为了保证对比的完整性,我们将椭圆包络方法保留在对比中,但在一致性投票中排除了它。
确定最适合该葡萄酒数据集的方法
作者供图(各方法适配性示意图)
考虑到我们数据的特点(严重偏态、混合群体、无已知真实标签),我们能选出一个“最优方法”吗?
稳健Z分数、IQR、孤立森林和LOF都能较好地处理偏态数据。如果必须选择一种,我们会选择孤立森林:它无需假设数据分布,能同时考虑所有特征,且能优雅地处理混合群体数据。
但没有任何一种方法能做到面面俱到:
孤立森林可能会遗漏仅在单个特征上极端的异常值(这类异常值可被Z分数/IQR检测到)
Z分数/IQR可能会遗漏在多个特征上均异常的样本(多维异常值)
更优的方法是:使用多种方法,相信一致性结果。被3种及以上方法标记的143个葡萄酒样本,比仅被一种方法标记的样本可靠得多。
以下是我们计算一致性的代码:
consensus = zscore_out + iqr_out + iforest_out + lof_out
high_confidence = df[consensus >= 3]
在大多数真实项目中,由于没有已知的真实标签,方法之间的一致性是最接近置信度的衡量标准。
对您自身项目的启示
选择方法前先明确问题:你真正要寻找的是哪种“异常”?数据录入错误、测量异常和真实罕见案例的表现各不相同,问题类型决定了适合的方法。
检查假设条件:如果数据严重偏态,标准Z分数和椭圆包络方法会给出错误结果。在确定方法前,先观察数据分布。
使用多种方法:被3种及以上、对“异常”定义不同的方法标记的样本,比仅被一种方法标记的样本更可信。
不要假设所有异常值都应被移除:异常值可能是错误,也可能是最有价值的数据点。做出判断的是领域知识,而非算法。
结论
本文的核心并非“异常值检测方法存在缺陷”,而是“异常值的定义取决于提问者的需求”。Z分数和IQR检测的是单维度上的极值;孤立森林和LOF寻找的是整体模式中突出的样本;椭圆包络方法在数据确实服从高斯分布时表现良好(我们的数据集不满足这一条件)。
在选择方法前,先明确自己真正要寻找的是什么。如果不确定,就运行多种方法,选择一致性结果。
常见问题(FAQs)
1. 应该从哪种方法开始使用?
一个好的起点是孤立森林方法。它无需假设数据分布,且能同时利用所有特征。但如果您想识别特定测量指标的极值(例如极高的血压读数),那么Z分数或IQR可能更合适。
2. 如何为Scikit-learn方法选择污染度(contamination)?
这取决于您要解决的问题。常用值为5%(或0.05),但需注意,污染度是一个“配额”——这意味着无论数据中真实异常值比例是1%还是20%,都会有5%的样本被分类为异常值。应根据您对数据中异常值比例的了解来选择污染度。
3. 拆分训练/测试数据前是否应移除异常值?
不应该。您应该在训练数据集上训练异常值检测模型,然后将训练好的模型应用于测试数据集。否则,测试数据会影响预处理过程,导致数据泄露(leakage)。
4. 如何处理分类特征?
本文介绍的方法仅适用于数值数据。处理分类特征有三种可能的方案:
对数值列单独进行异常值检测,对分类列使用基于频率的方法。
5. 如何判断标记的异常值是错误还是单纯的异常?
仅通过算法无法判断标记的异常值是错误还是单纯的异常。算法只能标记“异常”,不能判断“错误”。例如,一款残糖量极高的葡萄酒,可能是数据录入错误,也可能是本身就这么甜的餐后葡萄酒。最终,只有领域知识能给出答案。如果不确定,应标记该样本进行人工审核,而非自动移除。
推荐学习书籍 《CDA一级教材》适合CDA一级考生备考,也适合业务及数据分析岗位的从业者提升自我。完整电子版已上线CDA网校,累计已有10万+在读~ !



 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏





