我刚刚一岁零几天的孩子咳嗽,外加低烧37.7(对一岁婴儿来说还不算发烧),人还是挺活泼的,与平时相比没什么不同。老婆和岳母带他去某家大型儿童医院。我因为忙没有去。
本来应该挂呼吸科,但因为是双休日,呼吸科不上班,于是挂了内科普通门诊……做了血常规,显示某些项目偏低,诊断为“上感”。开了四种口服药和雾化。
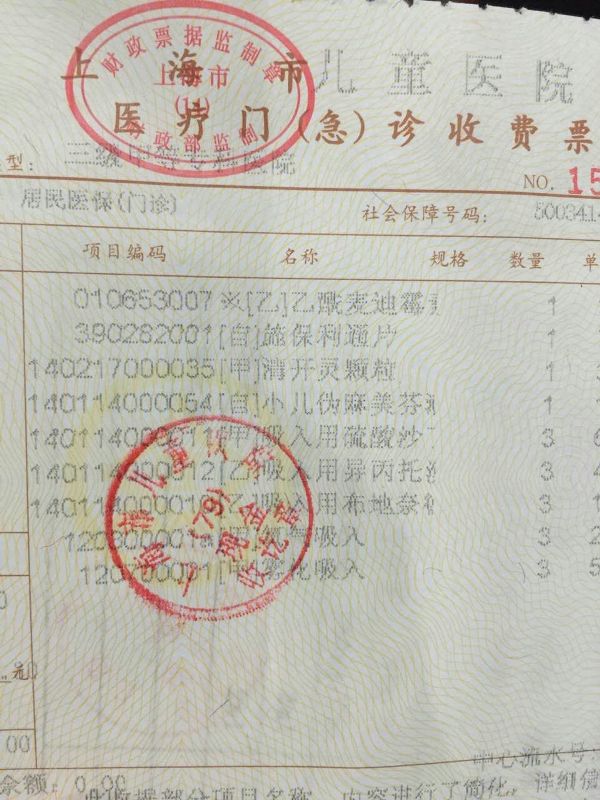
老婆把单子拍给我看,我一看就心想:糟了!
第一种是抗生素。抗生素对病毒无效这是我知道的。
第二种施保利通片。我还以为是什么西药,一查,我了个去,是草药!德国草药,作为中药进口的。
进口药品 德国 Schaper & Brümmer GmbH & Co. KG
英文名称:Esberitox N Tablets
注册证号:Z20090002,2009-03-30
药品特性:中药,每片重0.3g
这药特别神,教科书上没有,用药指南里没有,却被国内的儿科作为常用药来用,说是能提高免疫力,特别喜欢开。在德国是非处方草药,四岁以下儿童禁用,到了中国变成处方药,改配方改说明书,没有了年龄限制。非儿科医生大都不认识这玩艺。知乎上有几个医生在我对此药进行声讨时试图为它进行辩护,拿着说明书说没问题,因为说明书上写了可以用于婴儿,在别人指出问题后依然不屈不挠试图为此药正名。
这药70元一盒,是开出的所有药里最贵的。
据后来网友说,此药是药企行为。
第三种,清开灵颗粒,中成药。
第四种,盐酸伪麻黄碱 和 氢溴酸右美沙芬,也就是艾畅。右美沙芬是一种中枢止咳药,FDA禁止2岁以下儿童使用。
我查完资料后我就崩溃了。老婆要听医生的,我跟她吵起来。她说她有一个手机 app 可以打电话问别的医生,我当然不信,但是好歹就让她打吧。
一个其他医院的儿科医生跟我们通上了话,详细了解了情况,看了医院的检查报告,说了挺久的,最后开始说这些药。直接把抗生素以外的三种药全部否定了。中成药,没有证据显示有效。艾畅,不要吃。施保利通片是德国的草药,不要吃。最后仅剩下抗生素,他说他很为难,因为按照美国来说是不会开的,但是国内都会开。上感只有极小的可能性是细菌性感染。他让我们自己决定吃不吃。当然,我老婆还是决定吃,真不让吃的话,我的家庭就要破裂了。
于是就开始做雾化治疗和服用抗生素。
吃抗生素后第二天,孩子开始呕吐、腹泻。我岳母就火了,说是我不让吃药造成,要把所有的药都给孩子吃。我一查,那个抗生素有呕吐、腹泻的副作用,于是怀疑是抗生素造成。但是我说话没用。
然后全家出动去复诊,这次说什么也要找个专家门诊。还是这个医院,很幸运地挂上了内科专家门诊。
体温36.5,血检指标基本正常,X光片显示肺部纹理增多(报告书上的意见是“支气管炎改变”),喉咙发炎……我向医生询问呕吐会不会是抗生素造成?她没有明确回答,或者声音太小我没听清。最后开药,说要挂水。
挂水这俩字一出来,我就傻眼了。然后说施保利通片,要吃!我当时就崩溃了。
还好她说清开灵可以不吃。这是唯一我感到欣慰的地方。
接下来在医院,我和岳母展开了抢婴儿大战。岳母坚决要挂水,我瞅准机会想把孩子抢跑,没成功,反而被岳母一阵大骂,还要老婆跟我离婚。眼看家庭就要破裂。
期间还用那个 app 联系了另一个医生,那个医生听说我们是在这个医院看的,就说这个医院没问题。我又崩溃。看来这个 app 也不是很靠谱,关键还是要看医生。最后好不容易联系上当初那个医生,他说他没办法给我们拿主意,因为有1%-5%的可能性是细菌感染。
最后岳母妥协,先不挂水,第二天去我们常去的一家私立医院(不是莆田系那种,千万不要去莆田系!)做最后的诊断和决定,医生说啥就是啥。这个医院是我们经常带孩子去做检查和打疫苗的,老婆和我都在那里看过病,很信任,但是比较远,收费也特别高(挂号费800起),所以这次感冒觉得是小病就没有去。
半夜里,孩子又是咳嗽又是呕吐。岳母又是一阵骂。
第二天,终于见到了我们信任的医生。她一看我们带去的那些药就皱眉。做完详细检查后,她解释了为什么这是病毒性而不会是细菌性感染,说孩子得的是由呼吸道合胞病毒感染引起的毛细支气管炎,在北半球这个纬度这个季节很常见,抗生素无效,除了雾化以外,那些药都属于过度治疗。腹泻确实是那个抗生素的副作用,清开灵会更厉害。咳嗽是支气管痉挛引起(我没听清,孩子在叫,我抱他出去了几次),也就是由“喘”引起,现在要控制“喘”,否则可能会演变成哮喘。开了三种控制“喘”的药,价格都不高。
这下岳母没话说了,我也满意了。家庭免于破裂。
后面我的想法:
1,公立医院的问题根源在于国家限制诊疗费,逼着医院以药养医,引发了一系列问题……
2,当然,如果不限制诊疗费,穷人看不起病怎么办?这我不知道,我只知道是谁造成了穷人那么穷的,就应该由它来解决这个问题。
3,我自己在公立医院的看病体验还是可以的,虽然人多拥挤,但是费用实在是低,而且基本不会乱开药。只是这一次我实在理解不了。我知道医生不容易,但真正到了我头上,而且是宝贝儿子,忍不了。
4,有理想有抱负的医生,可以考虑一下跳出体制。通过这次事件,我对体制外医疗又多了一份好感。
来源:胡戈


 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页



