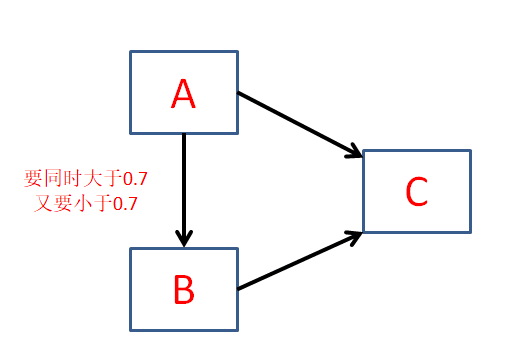
如制作下图这种样式的模型,想检验:
① 自变量A 对 因变量C 产生影响;
② 自变量B 对 因变量C 产生影响;
③ 自变量A 对 因变量B 产生影响;(即在这里B由自变量变成了因变量)
这个模型不涉及中介变量,也不做间接回归影响。只是单纯考察两两之间的影响。
问题是当B为因变量,考察自变量A对B的影响时,相关系数大于0.7才会认识是有比较高的相关性,进一步做回归的时候结果可能才会比较“好看”。
而当A与B都为自变量,考察各自对C的影响时,A和B之间又要小于0.7,才不会出现多重共线性,被认为是同一个东西。
要是这么推的话,这个模型不就矛盾了吗?A与B之间的相关既要大于0.7又要小于0.7.
还是说如果我想考察这三个变量两两间的回归影响时,模型不可以这么画?一个变量不可以既做自变量又做因变量?
其实问这个问题是看了不少管理学的定量研究论文,发现一个趋势是很多人喜欢把模型画的越来越复杂,可能认为越复杂的模型越能显出水平,于是设计了一堆变量画了一堆方框。然后用一堆箭头各种连接一通猛指。但仔细想想这样会不会在统计学上出现矛盾的情况。因此想请教各位统计学达人,谢谢



 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏






