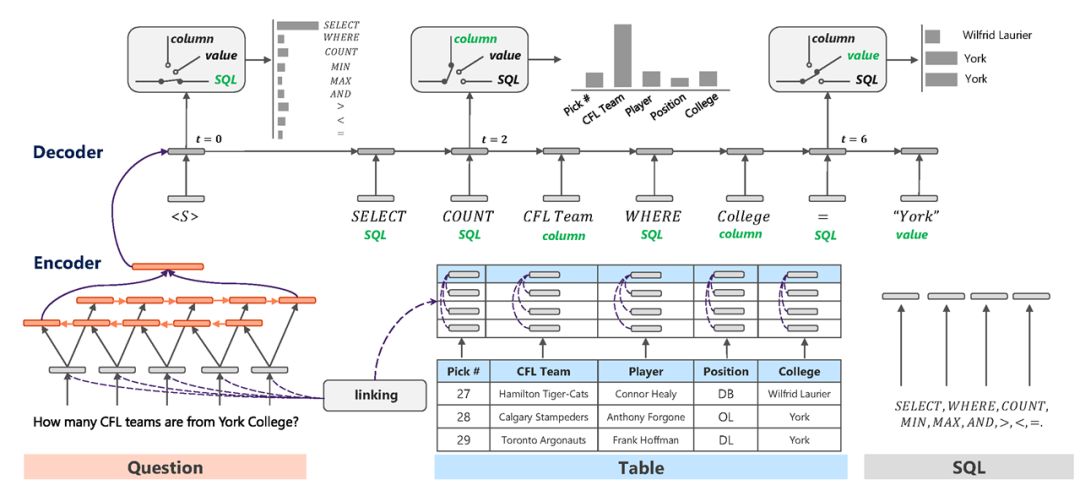
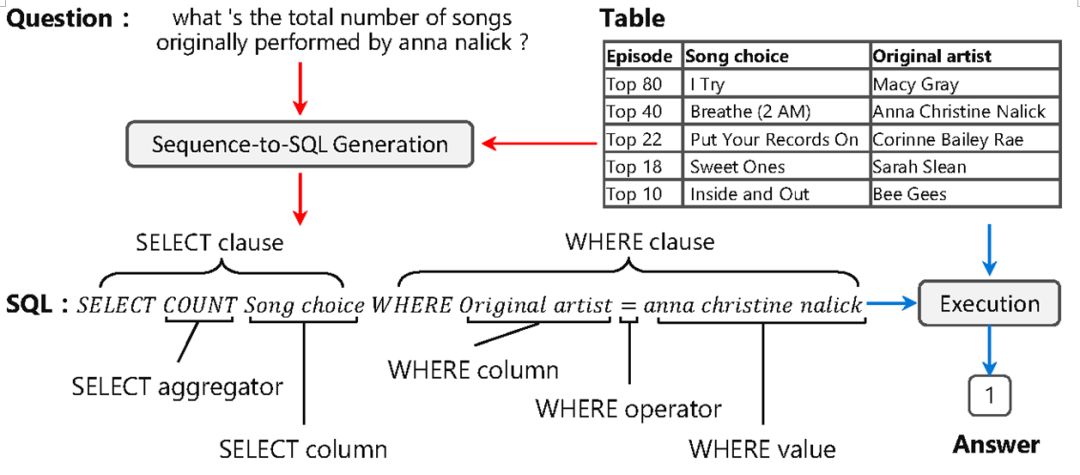
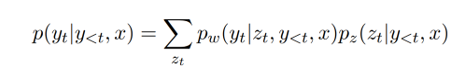具体来说,在三个频道中,column和value频道的候选由于由N个单词组成,所以用RNN建模,得到向量表示,而SQL频道的候选用对应的word embedding表示。在每个频道中,当前时刻生成元素的概率是由此时刻解码器RNN的状态向量和候选元素的向量表示之间通过计算相似度后归一化所得。而门单元的概率输出则是直接由解码器RNN的状态向量经线性变化后经过softmax所得。由于column、value频道的预测候选是直接从表中获得,所以解决了Pointer Network模型所面对的不一致问题。
此外,我们还在模型中加入了SQL语法和表结构的信息来提升性能。
首先,列名和单元格直接的关系可以帮助column频道的预测。如果我们在问题中提到了表中的某一单元格,那么Where column的结果也大概率是此单元格所在的列。所以,我们也用了表中单元格的信息去帮助column频道的预测。具体来说,我们将单元格的向量表示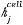 的加权求和与原列名称的向量表示
的加权求和与原列名称的向量表示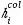 首尾相,以此作为新的列名的向量表示。这个权重
首尾相,以此作为新的列名的向量表示。这个权重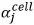 是由单元格中出现的单词在句子中复现的程度决定的。
是由单元格中出现的单词在句子中复现的程度决定的。
 公式3
公式3
其次,列名和单元格之间的关系也可以帮助value频道的预测。Where value所在的单元格一定在Where column所在的列,所以我们用一个全局变量保存了最近一侧预测的列位置,在value频道中只选择这列的单元格作为候选进行预测。直观来看,要预测的单元格内容基本都出现在问句之中,所以我们进一步用上文中提到的由单词复现得到的权重和value频道预测的概率分布 做一个加权求和,从而得到最终value频道的预测概率。
做一个加权求和,从而得到最终value频道的预测概率。
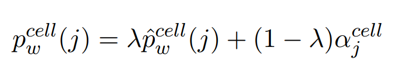
公式4
我们在WikiSQL数据集上进行了实验。这个数据集包含了61,297/9,145/17,284个训练/开发/测试样本。每个样本分别包含了一个问句、一张表、一个SQL表达式,以及问句在表中的答案。我们用了两种评估指标,分别是逻辑表达式准确率(Acc_lf):生成的SQL是否和样本中的SQL表达式完全匹配的比例,和执行准确率(Acc_ex):生成的SQL在表中查询后得到的答案和样本中的答案一致的比例。
实验结果如下图所示。Aug.PntNet代表Pointer Network模型,其中在STAMP(w/o)cell的模型中,value频道预测的候选不是表中的单元格,而是问句中的单词,即在value频道沿用了Point Network的拷贝机制。在STAMP (w/o column-cell relation)模型中,我们去掉了单元格信息对于column和value频道的增强。
 图3
图3
通过此表我们可以看到,用表中的元素整体作为预测候选以及加入列名与单元格之间的依赖关系这两点设计都对模型有所加强。我们在逻辑表达式准确率和执行准确率两个维度上对比Pointer Network模型分别获得了14.7%和14.1%的提升。
下图展示了我们的模型在更细粒度上的执行准确率:

图4
可以看到,在Where从句中,我们模型的效果有着明显的提升。
下图中展示了模型的输出样例:
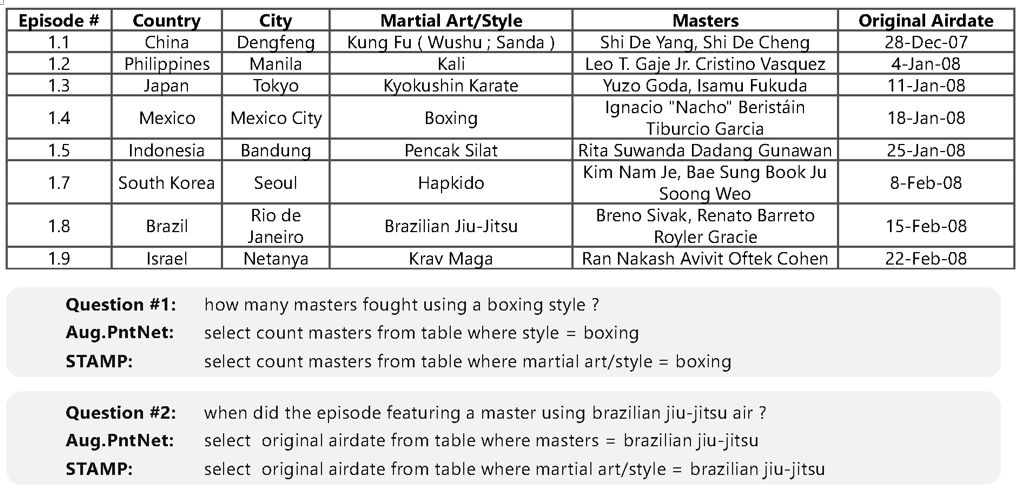
图5
我们可以看到,我们的模型解决了问题表达和表中内容表达不一致所导致的问题。
总结
本文以自然语言到SQL语句生成任务为例,介绍了在语义分析(semanticparsing)领域我们提出的一种融合SQL语法的端到端神经网络方法。这一语义分析技术的应用将有效地提升搜索引擎的结果准确度、提高虚拟语音助手的多轮对话表现等。未来,我们还计划使用更多样的监督信号学习适用于不同场景的语义分析算法。
想要了解更多细节的读者,欢迎阅读我们发布在今年ACL 2018上的论文:
Semantic Parsing with Syntax- and Table-Aware SQL Generation, Yibo Sun, Duyu Tang, Nan Duan, Jianshu Ji , Guihong Cao , Xiaocheng Feng , Bing Qin, Ting Liu, Ming Zhou, ACL 2018
作者简介
孙一博,微软亚洲研究院自然语言计算组的实习生,目前就读于哈尔滨工业大学,社会计算与信息检索实验室。研究兴趣包括问答系统,语义分析和深度学习等。
转载自微软研究院


 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏

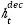 代表解码器中的隐层状态,
代表解码器中的隐层状态, 代表编码器中第i个单词对应的因层状态。
代表编码器中第i个单词对应的因层状态。