经管之家App
让优质教育人人可得
立即打开


完整代码如下
setwd("E:/AllClass/junior1/RegressionAnalysis/unit2")#设置文件路径
#保留原路径setwd("C:/User/10854/documents")
#以下利用理论方法使用一元回归模型
#导入数据
data<-read.csv("2-7.csv")#书本2.15,表数据2-7
x<-data[,1]
y<-data[,2]
n<-length(x)
split.screen(c(1,3))
screen(1)
plot(x,y,pch=16)
title(main="数据散点图")
#求均值与回归变量lxx,lyy,lxy
meanx<-mean(x)
meany<-mean(y)
lxx<-sum((x-meanx)^2)
lyy<-sum((y-meany)^2)
lxy<-sum((x-meanx)*(y-meany))
#回归系数估计
beta_1<-lxy/lxx#beta_1
beta_0<-meany-beta_1*meanx#beta_0
screen(2)
plot(x,y,pch=16)
points(x,beta_0+beta_1*x,type="l")
title(main="回归图")
#预测值与平方和
y_hat<-beta_0+beta_1*x
sse<-sum((y_hat-y)^2)#残差平方和
ssr<-sum((y_hat-meany)^2)#回归平方和
sst<-ssr+sse#总离差平方和
#回归误差ε的方差sigma估计
sigma_hat<-sqrt(1/(n-2)*sse)
#对bet_0、beta_1的95%区间估计
alpha<-0.05
#beta_0,beta_1的分布标准差
sd.beta_0<-sqrt((1/n+(meanx^2)/lxx))*sigma_hat
sd.beta_1<-sqrt(sigma_hat^2/lxx)
beta_1l<-beta_1-qt(1-alpha/2,n-2)*sd.beta_1#beta_1置信下限
beta_1u<-beta_1+qt(1-alpha/2,n-2)*sd.beta_1#beta_1置信上限
beta_0l<-beta_0-qt(1-alpha/2,n-2)*sd.beta_0#beta_0置信下限
beta_0u<-beta_0+qt(1-alpha/2,n-2)*sd.beta_0#beta_0置信上限
#remark
#qt是求出置信度1-α对应的统计量值t(1-α)
#dt是求出统计量对应的置信度值,即p值(这里用不上t分布)
#dt返回概率密度,pt返回分布函数,qt返回分位数函数,rt生成随机数。
#qf\df都是同理,对应的是F分布
#计算xy决定系数
R<-ssr/sst
#回归方程的显著性检验
#法一方差分析F检验
f<-(ssr/1)/(sse/(n-2))
p1<-pf(f,1,n-2)#F为统计量、1为第一个自由度,n-2为第二个自由度
#法二回归系数的beta_1的t检验
t1<-beta_1/sd.beta_1#t统计量
p2<-pt(t1,n-2)
#法三相关系数r的t检验
r<-lxy/(sqrt(lxx*lyy))
t2<-sqrt(n-2)*r/sqrt(1-r^2);
p3<-pt(t2,n-2) #p值
#残差图
screen(3)
e<-y_hat-y #残差
n<-length(e)
sigma_u<-seq(2*sigma_hat,2*sigma_hat,length.out=n) #残差2σ原则
sigma_l<-seq(-2*sigma_hat,-2*sigma_hat,length.out=n)
plot(x,e,pch=16,ylim=c(5,-5))
points(x,sigma_u,type="l") #画2σ上下界
points(x,sigma_l,type="l")
title(main="残差图")
#预测广告费用为1000万元时,销售达多少
x0<-1000
y0<-beta_0+beta_1*x0
#因变量新值得95%置信区间
h00<-1/n+((x0-meanx)^2)/lxx
y0_l<-y0-qt(1-alpha/2,n-2)*sqrt(1+h00)*sigma_hat#预测新值得置信下限
y0_u<-y0+qt(1-alpha/2,n-2)*sqrt(1+h00)*sigma_hat#预测新值得置信上限
#近似置信区间
y0_l_ <- y0-2*sigma_hat
y0_u_ <- y0+2*sigma_hat
#因变量新值得平均值的95%置信区间
y0_l_E<-y0-qt(1-alpha/2,n-2)*sqrt(h00)*sigma_hat#预测新值均值得置信下限
y0_u_E<-y0+qt(1-alpha/2,n-2)*sqrt(h00)*sigma_hat#预测新值均值得置信上限
#以下利用R函数回归
#导入数据
data<-read.csv("2-7.csv")#书本2.15,表数据2-7
x<-data[,1]
y<-data[,2]
n<-length(x)
# split.screen(c(1,3))
# screen(1)
plot(x,y,pch = 16)
title(main="数据散点图")
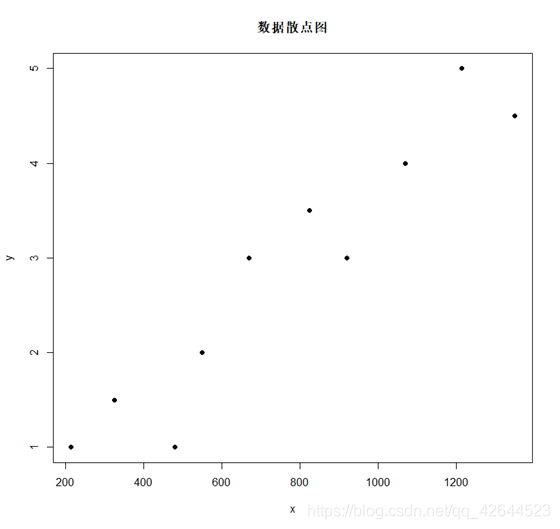
由第一问的散点图,大致正相关,并且呈线性关系
先求样本均值
xˉ=Σxi,yˉ=Σyi
Lxx=Σi=1n(xi−xˉ)2
Lyy=Σi=1n(yi−yˉ)2
Lxy=Σi=1n(xi−xˉ)(yi−yˉ)
则回归系数的估计如下:
β^1=LyyLxx
β^0=yˉ−β1xˉ
得到回归方程如下:
yi=β^0+β^1xi
#求均值与回归变量lxx,lyy,lxy
meanx<-mean(x)
meany<-mean(y)
lxx<-sum((x-meanx)^2)
lyy<-sum((y-meany)^2)
lxy<-sum((x-meanx)*(y-meany))
#回归系数估计
beta_1<-lxy/lxx#beta_1
beta_0<-meany-beta_1*meanx#beta_0
# screen(2)
plot(x,y,pch=16) #散点
points(x,beta_0+beta_1*x,type="l") #回归线
title(main="回归图")
得出各参数
| 统计量 | 统计值 |
|---|---|
| xˉ | 762 |
| yˉ | 2.85 |
| LXX | 1297860 |
| Lxy | 4653 |
| Lyy | 18.525 |
| β^0 | 0.118 |
| β^1 | 0.00359 |
回归方程:
yi=0.118+0.00359xi
回归图:
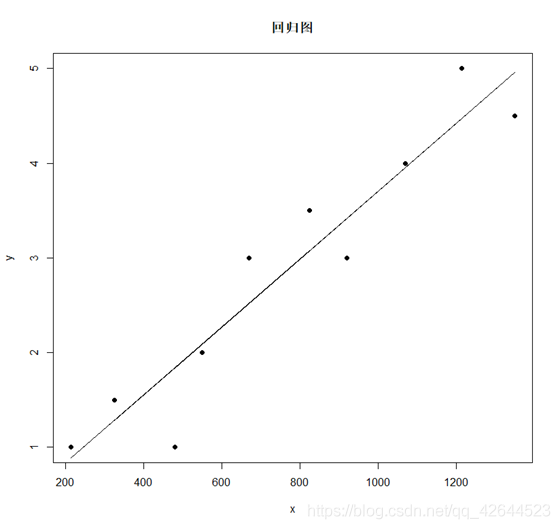
分别得出
SSE=Σ(yi−y^)2
标准误差σ的无偏估计为:
σ^=n−21Σi=1nei2=n−21Σ(yi−y^)2
sse<-sum((y_hat-y)^2)#残差平方和
#回归误差ε的方差sigma估计
sigma_hat<-sqrt(1/(n-2)*sse)
SSE=1.843,σ^=0.48
β^1与β^0的分布为
β^1∼N(β1,Lxxσ2),β^0∼N(β0,[n1+Lxxxˉ2]σ2)
由β^1分布构造了服从自由度为n−2的t分布统计量
t=σ^(β^1−β1)Lxx
因而
P(∣∣∣∣∣σ^(β^1−β1)Lxx∣∣∣∣∣>tα/2(n−2))
得到β1的置信度为1−α的置信区间为(α=0.05)
(β^1−tα/2Lxxσ^,β^1+tα/2Lxxσ^)
对β^0同理得置信度为1−α的置信区间为(α=0.05)
(β^1−tα/2[n1+Lxxxˉ2]σ^,β^1+tα/2[n1+Lxxxˉ2]σ^)
alpha<-0.05 #置信度
#beta_0,beta_1的分布标准差
sd.beta_0<-sqrt((1/n+(meanx^2)/lxx))*sigma_hat
sd.beta_1<-sqrt(sigma_hat^2/lxx)
beta_1l<-beta_1-qt(1-alpha/2,n-2)*sd.beta_1#beta_1置信下限
beta_1u<-beta_1+qt(1-alpha/2,n-2)*sd.beta_1#beta_1置信上限
beta_0l<-beta_0-qt(1-alpha/2,n-2)*sd.beta_0#beta_0置信下限
beta_0u<-beta_0+qt(1-alpha/2,n-2)*sd.beta_0#beta_0置信上限
得到β1的置信度为0.05的置信区间为[0.0026,0.0046]
得到β1的置信度为0.05的置信区间为[-0.7,0.937]
各平方和如下:
SSE=Σ(yi−y^)2
SSR=Σ(y^−yˉ)2
SST=SSR+SSE
决定系数为
r2=SSTSSR
sse<-sum((y_hat-y)^2)#残差平方和
ssr<-sum((y_hat-meany)^2)#回归平方和
sst<-ssr+sse#总离差平方和
#计算xy决定系数
R<-ssr/sst
SSE=1.84,SSR=16.68,SST=18.525,r2=0.9
f<-(ssr/1)/(sse/(n-2))
p1<-pf(f,1,n-2)#F为统计量、1为第一个自由度,n-2为第二个自由度
#1-p1为p值
一元线性回归方差分析表如下:
| 方差来源 | 自由度 | 平方和 | 均方 | F值 | P值 |
|---|---|---|---|---|---|
| 回归 | 1 | SSR=16.68 | SSR/1=16.68 | SSE(n−2)SSR/1=72.40 | p=2.8∗10−5 |
| 残差 | n−2 | SSE=1.84 | SSE/(n−2)=0.23 | ||
| 总和 | n−1 | SST=18.525 |
β^1的分布为
β^1∼N(β1,Lxxσ2)
假设检验原假设为H0:β1=0 ,构造检验统计量t服从自由度为 n−2 的 t 分布
t=σ^β^1Lxx
并计算对应的 p 值
#回归系数的beta_1的t检验
t1<-beta_1/sd.beta_1 #t统计量
p2<-pt(t1,n-2) #(1-p2)为p值
t=8.50,p=1.40∗10−5
相关系数为r
r=LxxLyyLxy=β^1LyyLxx
构造检验统计量
t=1−r2n−2r∼t(n−2)
当∣t∣>tα/2(n−2) 时,认为简单回归系数显著不为零
#相关系数r的t检验
r<-lxy/(sqrt(lxx*lyy))
t2<-sqrt(n-2)*r/sqrt(1-r^2);
p3<-pt(t2,n-2) #(1-p3)为p值
t=8.50,p=1.40∗10−5
#残差图
# screen(3)
e<-y_hat-y #残差
n<-length(e)
sigma_u<-seq(2*sigma_hat,2*sigma_hat,length.out=n) #残差2σ原则
sigma_l<-seq(-2*sigma_hat,-2*sigma_hat,length.out=n)
plot(x,e,ylim=c(5,-5))
points(x,sigma_u,type="l") #画2σ上下界
points(x,sigma_l,type="l")
title(main="残差图")
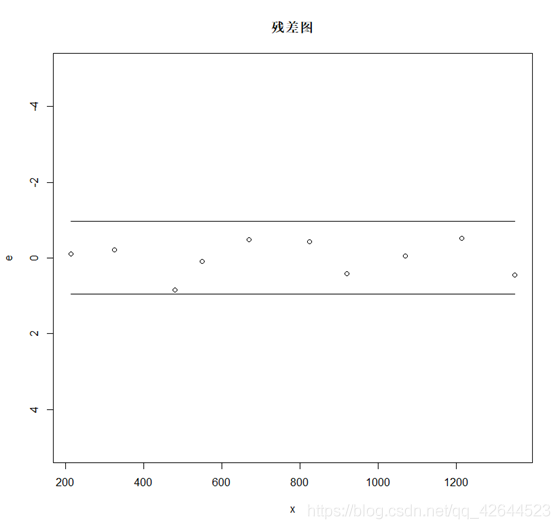
计算出残差后,及自变量x为横轴,以残差为总纵轴画散点图得到残差图,从残差图上看出,产茶时围绕着 e=0 随机波动,并且波动范围在方差估计σ^的两倍。所以可以判定模型的基本假定是满足的。
x0<-1000
y0<-beta_0+beta_1*x0
y=3.7
可以计算得到 y^0 的分布为
y^0∼N(β0+β1x0,(n1+Lxx(x0−xˉ)2)σ2)
所以枢轴量为
y0−y^0∼N(0,(1+h00)σ2),h00=(n1+Lxx(x0−xˉ)2)
统计量为
t=1+h00σ^y0−y0^∼t(n−2)
得精确置信区间为
y0^±tα/2(n−2)1+h00σ^
近似预测区间为
y^0±2σ^
#因变量新值95%置信区间
h00<-1/n+((x0-meanx)^2)/lxx
y0_l<-y0-qt(1-alpha/2,n-2)*sqrt(1+h00)*sigma_hat#预测新值得置信下限
y0_u<-y0+qt(1-alpha/2,n-2)*sqrt(1+h00)*sigma_hat#预测新值得置信上限
精确置信区间为[2.519,4.887]
近似预测区间为[2.743,4.663]
所以两区间比较接近,可以用近似区间估计
根据 y^0 构造枢轴量(含E(y0))
y0^−E(y0)∼N(0,h00σ2),h00=(n1+Lxx(x0−xˉ)2)
统计量为
t=h00σ^y0−y0^∼t(n−2)
得置信水平95%得精确置信区间为
y0^±tα/2(n−2)h00σ^
#因变量新值得平均值的95%置信区间
y0_l_E<-y0-qt(1-alpha/2,n-2)*sqrt(h00)*sigma_hat#预测新值均值得置信下限
y0_u_E<-y0+qt(1-alpha/2,n-2)*sqrt(h00)*sigma_hat#预测新值均值得置信上限
E(y0)的95%置信区间为[3.283,4.122]
根据上一题的程序,我们对例题2.1直接求解
setwd("E:/AllClass/junior1/RegressionAnalysis/unit2")#设置文件路径
#保留原路径setwd("C:/User/10854/documents")
#以下利用理论方法使用一元回归模型
#导入数据
data<-read.csv("2-1.csv")#书本火灾题目,表数据2-1
x<-data[,1];y<-data[,2]
n<-length(x)
split.screen(c(1,3))
screen(1)
plot(x,y)
title(main="数据散点图")
#求均值与回归变量lxx,lyy,lxy
meanx<-mean(x);meany<-mean(y)
lxx<-sum((x-meanx)^2)
lyy<-sum((y-meany)^2)
lxy<-sum((x-meanx)*(y-meany))
#回归系数估计
beta_1<-lxy/lxx#beta_1
beta_0<-meany-beta_1*meanx#beta_0
screen(2)
plot(x,y)
points(x,beta_0+beta_1*x,type="l")
title(main="回归图")
#预测值与平方和
y_hat<-beta_0+beta_1*x
sse<-sum((y_hat-y)^2)#残差平方和
ssr<-sum((y_hat-meany)^2)#回归平方和
sst<-ssr+sse#总离差平方和
#回归误差ε的方差sigma估计
sigma_hat<-sqrt(1/(n-2)*sse)
#对bet_0、beta_1的95%区间估计
alpha<-0.05
#beta_0,beta_1的分布标准差
sd.beta_0<-sqrt((1/n+(meanx^2)/lxx))*sigma_hat
sd.beta_1<-sqrt(sigma_hat^2/lxx)
beta_1l<-beta_1-qt(1-alpha/2,n-2)*sd.beta_1#beta_1置信下限
beta_1u<-beta_1+qt(1-alpha/2,n-2)*sd.beta_1#beta_1置信上限
beta_0l<-beta_0-qt(1-alpha/2,n-2)*sd.beta_0#beta_0置信下限
beta_0u<-beta_0+qt(1-alpha/2,n-2)*sd.beta_0#beta_0置信上限
#计算xy决定系数
R<-ssr/sst
#回归方程的显著性检验
#方差分析F检验
f<-(ssr/1)/(sse/(n-2))
p1<-pf(f,1,n-2)#F为统计量、1为第一个自由度,n-2为第二个自由度
#回归系数的beta_1的t检验
t1<-beta_1/sd.beta_1#t统计量
p2<-pt(t1,n-2)
#残差图
screen(3)
e<-y_hat-y
n<-length(e)
sigma_u<-seq(2*sigma_hat,2*sigma_hat,length.out=n)#残差2σ原则
sigma_l<-seq(-2*sigma_hat,-2*sigma_hat,length.out=n)
plot(x,e,ylim=c(12,-12))
points(x,sigma_u,type="l")
points(x,sigma_l,type="l")
title(main="残差图")
回归方程如下
yi=10.28+4.91xi
参数表如下:
| 参数 | 参数值 |
|---|---|
| β^0 | 10.28 |
| β^1 | 4.91 |
| r2 | 0.92 |
| σ^ | 2.31 |
| β^0区间估计 | [7.2,13.34] |
| β^1区间估计 | [4.07,5.76] |
一元线性回归方差分析表如下:
| 方差来源 | 自由度 | 平方和 | 均方 | F值 | P值 |
|---|---|---|---|---|---|
| 回归 | 1 | SSR=841.8 | SSR/1=841.8 | SSE/13SSR/1=156.89 | p=1.248∗10−8 |
| 残差 | 13 | SSE=69.8 | SSE/13=5.37 | ||
| 总和 | 14 | SST=911.5 |
回归方程的 β^1的检验中,p值为6.239∗10−9<0.05
数据的散点图,回归图,残差图如下
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZPFVwi2s-1570342114068)(C:\Users\10854\AppData\Roaming\Typora\typora-user-images\1570338668192.png)]](https://img-blog.csdnimg.cn/20191006141632798.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQyNjQ0NTIz,size_16,color_FFFFFF,t_70)
因为决定系数为0.92,具有比较强的线性相关性,且残差均在 ±2σ^ 内波动,而线性回归系数β^1的检验通过,所以可以认为火灾发生地点与最近的消防站距离和火灾损失呈线性关系,符合模型yi=10.28+4.91xi

 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏




