AIU人工智能学院:数据科学、人工智能从业者的在线大学。
数据科学(Python/R/Julia)数据分析、机器学习、深度学习
通过前面的说明,我们已经知道Pipeline可以用于将多个处理步骤合并为一个,并且本身具备fit、predict和score方法,其行为与scikit-learn中的其他模型相同,并且最常见的用力是将预处理步骤(比如缩放)与一个监督模型(比如分类器)链接在一起。
构建管道:我们来看使用Pipeline类表示MinMaxScaler缩放数据之后在使用一个SVM工作流程(暂时不适用网格搜索)。
首先,我们构造一个由步骤列表组成的管道对象,每个步骤都是一个元组,其中包含名称(可以选定任意字符串作为其名称(不包含双下划线))和一个估计器示例:
from sklearn.pipeline import Pipeline
from sklearn.datasets import load_breast_cancer
from sklearn.preprocessing import MinMaxScaler
#加载并划分数据
cancer = load_breast_cancer
x_train, x_test, y_train, y_test = train_test_split(cancer.data, cancer.target, random_state=0)
pipe = Pipeline([("scaler", MinMaxScaler), ("svm", SVC)])
#这里我们创建了两个步骤,第一个叫做“scaler”,第二个叫做“svm”,分别是MinMaxScaler实例和SVC实例。
#现在我们可以向任何其他scikit-learn估计器一样拟合这个管道
pipe.fit(x_train, y_train)
#这里首先对第一个缩放器调用fit,然后使用该缩放器对训练数据进行变化,最后将缩放后的数据来拟合SVM。
#现在我们要在测试数据上进行评估,只需要调用pipe_score
print("Test score of pipe: {:.3f}".format(pipe.score(x_test, y_test)))
运行后其结果为:
Test score of pipe: 0.951
由上述步骤可以看出:如果对管道调用score方法,则首先使用缩放器对测试数据进行变换,然后利用缩放后的测试数据对SVM调用score方法。这个结果与我们从上节得到的结果相同(利用手动变换数据)。但是我们减少了“预处理+分类”这个过程,减少了不少的代码量。不过,使用管道的主要优点在于我们可以在cross_val_score或GridSearchCV中使用这个估计器。
在网格中使用管道:在网格中使用管道的工作原理和使用其他任何估计器相同。首先我们定义一个需要搜索的网格参数,并利用管道和参数构建一个GridSearchCV。不过在指定参数网格时存在一个细微的变化——我们需要为每个参数指定他在管道中所属的步骤,需要调节两个参数C和gamma,属于第二个步骤。我们给出这个步骤的名称是“SVM”。
为管道定义参数网格的语法是为每个参数指定步骤的名称,后面加上__(双下划綫),然后是参数的名称。因此,要想搜索SVC的C参数,必须使用“svm__C”作为参数网格的字典,对gamma也使用类似的方法。
param_grid = {'svm__C': [0.001,0.01,0.1,1,10,100], 'svm__gamma': [0.001,0.01,0.1,1,10,100]}
#有了这个参数网格,我们可以向平常一样使用GridSearchCV
grid = GridSearchCV(pipe, param_grid=param_grid, cv=5)
grid.fit(x_train, y_train)
print("Best cross validation accuracy is: {:.3f}".format(grid.best_score_))
print("Test set score of Pipe is: {:.3f}".format(grid.score(x_test, y_test)))
print("Best parameters of Pipe are : {}".format(grid.best_params_))
运行后其结果为:
Best cross validation accuracy is: 0.981
Test set score of Pipe is: 0.972
Best parameters of Pipe are : {'svm__C': 1, 'svm__gamma': 1}
与前面所作的网格搜索不同,现在对于交叉验证的每次划分来说,仅使用训练部分对MinMaxScaler进行拟合,测试部分的信息没有泄露到搜错中,下面我们对两种情况进行对比:
mglearn.plots.plot_proper_processing
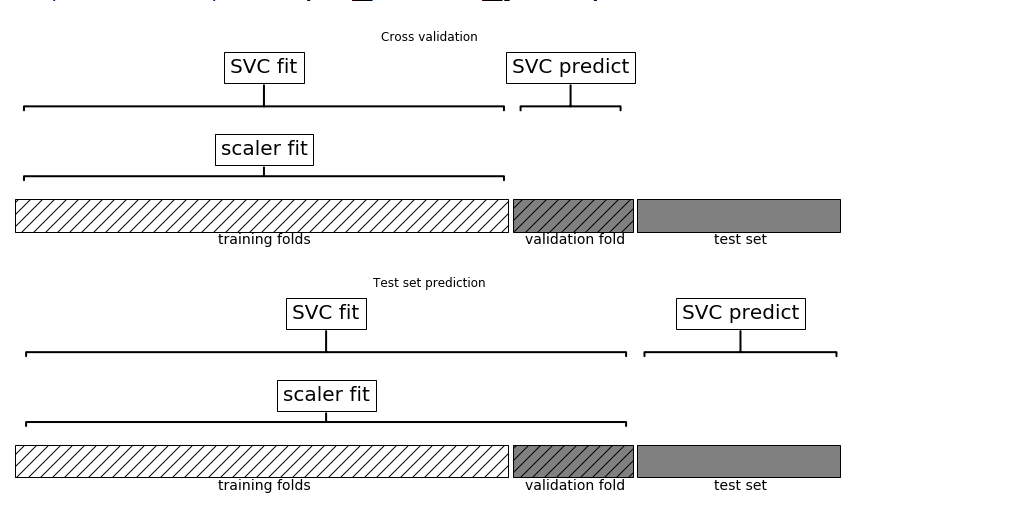
使用管道在交叉验证循环内部进行预处理时的数据使用情况
在交叉验证中,信息泄露的影响大小取决于预处理步骤的性质,使用测试部分来估计数据的范围,通常不会产生大的影响,但是在特征提取和特征中使用测试部分,则会导致较大的差异。

关注“AIU人工智能”公众号,回复“白皮书”获取数据分析、大数据、人工智能行业白皮书及更多精选学习资料!


 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏





