经管之家App
让优质教育人人可得
立即打开


作者 | CDA数据分析师
俗话说,巧妇难为无米之炊。不管你厨艺有多好,如果没有食材,也做不出香甜可口的饭菜来,所以想要做出饭菜来,首先要做的就是要买米买菜。而数据分析就好比是做饭,首先也应该是准备食材,也就是获取数据源。

导入数据主要用到的是Pandas里的read_x()方法,x表示待导入文件的格式。
1、导入.xlsx文件
在Excel中导入.xlsx格式的文件时很简单的,双击打开就可以了。在Python中导入.xlsx文件的是read_excel()这种方法。
(1)基本导入
在导入文件的时候首先要指定文件的路径,也就是这个文件在电脑中的哪个文件夹下存放着。

电脑中的文件路径默认是使用\的,这个时候需要在路径前面加一个r(转义符)避免路径里面的\被转义。也可以不加转义符r,但是需要把路径里面所有的\转换成/,这个规则在导入其他格式文件的时候也是一样的,我们一般会选择在路径前面加转义符r。


(2)指定导入哪个Sheet
.xlsx格式的文件可以有很多个Sheet,你可以通过设定sheet_name参数来指定要导入哪个Sheet的文件。

除了可以指定具体Sheet的名字,还可以传入Sheet的顺序,从0开始计数。

如果不指定sheet_name参数的时候,那么默认导入的都是第一个sheet的文件。
(3)指定行索引
将本地文件导入DataFrame的时候,行索引使用的是从0 开始的默认索引,可以通过设置index_col参数来设置。

index_col表示用.xlsx文件中的第几列做行索引,从0 开始计数。
(4)指定列索引
将本地文件导入DataFrame的时候,默认使用的是源数据表的第一行作为列索引,也可以通过设置header参数来设置列索引。header参数值默认为0,即用第一行作为列索引;也可以是其他行,只需要传入具体的那一行即可;也可以使用默认从0开始的数作为列索引。

(5)指定导入列
有的时候本地文件的列数太多,而我们又不需要那么多列的时候,我们就可以通过设定usecols参数来指定要导入的列。

可以给usecols 参数具体的某个值,表示要导入第几列,同样是从0开始计数,也可以以列表的形式传入多个值,表示要传入哪些列。

2、导入.csv文件
在Excel中导入.csv格式的文件和打开.xlsx格式的问价是一样的,双击即可。而在Python中导入.csv问价用的方法是read_csv()。
(1)直接导入
只需要指明文件路径即可。

(2)指明分隔符号
在Excel和DataFrame中的数据都是很规整的排列的,这都是工具在后台根据某条规则进行切分的。read_csv()默认文件中的数据都是以逗号分开的,但是有的文件不是用逗号分开的,这个时候就需要人为指定分隔符号,否则就会报错。
新建一个以空格作为分隔符号的文件,如下图所示:

如果用默认的逗号作为分隔符号,看看导入的数是什么样的。


我们看到所有的数据还是一个整体,并没有被分开,把分隔符号换成空格以后再看看效果:

使用正确的分隔符号以后,数据被规整的分好了。常见的分隔符号除了逗号、空格,还有制表符(\t)。
(3)指明读取行数
假设现在有一个几百兆的文件,你想了解一下这个文件里有哪些数据,那么这个时候你就没必要把全部数据都导入,你只要看到前面几行即可,因此只要设置nrows参数即可。

(4)指定编码格式
Python用得比较多的两种编码格式是UTF-8和gbk,默认编码格式是UTF-8。我们要根据导入文件本身的编码格式进行设置,通过设置参数encoding来设置导入的编码格式。有的时候两个文件看起来一样,它们的文件名一样,格式一样,但是如果它们的编码格式不一样,也是不一样的文件,比如当你把一个Excel文件另存为时会出现两个选项,虽然都是.csv文件,但是这两种格式代表两种不同的文件,如下图所示:

如果CSV UTF-8(逗号分隔)(*.csv)格式的文件,那么导入的时候就需要加encoding参数。

你也可以不加encoding参数,因为Python默认的编码格式就是UTF-8。

如果CSV(逗号分隔)(*.csv)格式的文件,那么在导入的时候就需要把编码格式更改为gbk,如果使用UTF-8就会报错。

(5)engine指定
当文件路径或者文件名中包含中文时,如果还用上面的导入方式就会报错。

这个时候我们就可以通过设置engine参数来消除这个错误。这个错误产生的原因是当调用read_csv()方法时,默认使用C语言作为解析语言,我们只需要把默认值C更改为Python就可以了,如果文件格式是CSV UTF-8(逗号分隔)(*.csv),那么编码格式也需要跟着变为utf-8-sig,如果文件格式是CSV(逗号分隔)(*.csv)格式,对应的编码格式则为gbk。

(6)其他
.csv文件也涉及行、列索引设置及指定导入某列或者某几行,设定方法与导入.xlsx文件一致。
3、导入.txt文件
(1)Excel实现
在Excel中导入.txt文件时,我们需要通过依次单击菜单栏中的数据>获取外部数据>自文本,然后选择要导入的.txt文件所在的路径,如下图所示:

选完路径以后会出现如下图所示的界面,预览文件就是我们要导入的文件,确认无误后按下一步按钮即可。

因为我们举例.txt 文件用空格分开的,所以在分隔符号项勾选空格复选框,如果待导入的.txt 文件是用其他分隔符号分隔的,那么选择对应的分隔符号,然后直接按完成按钮即可,如下图所示:


(2)Python实现
在Python中导入.txt文件用的方法是read_table()是将利用分隔符号分开的文件导入DataFrame的通用函数。它不仅可以导入.txt文件,还可以导入.csv文件。
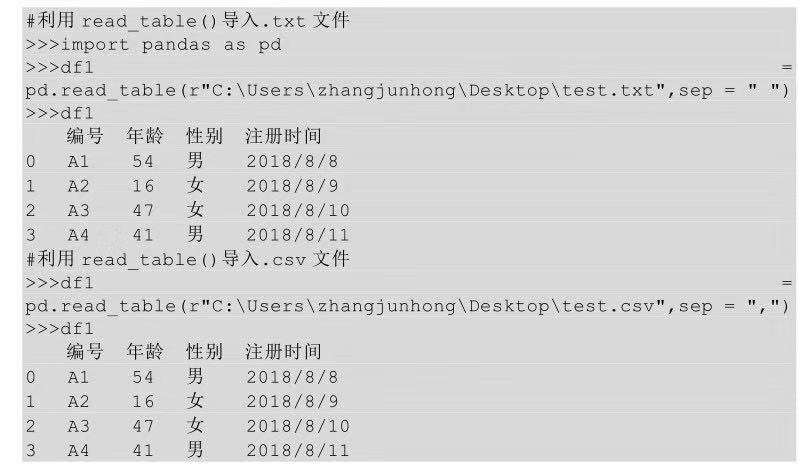
从上面的代码可以看出,函数在导入.csv文件时,与read_csv()函数不同的是,即使是逗号分隔开的问价也是需要用sep指明分隔符号的,而不是像read_csv()函数那样,如果文件是逗号分隔的,则可以不用写。
read_table()函数其他参数的用法与read_csv()函数的基本一致。
4、导入sql文件
(1)Excel实现
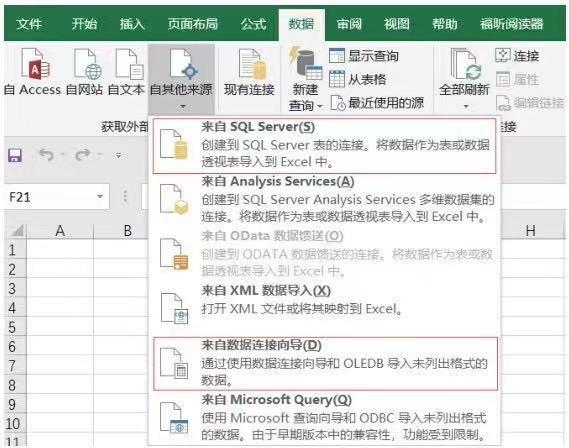
Excel可以直接连接数据库,通过依次单击菜单栏中的数据>自其他来源导入sql文件。如果你的数据库是SQL Server,那么直接选择来自SQL Server即可;如果是MySQL数据库,那么你需要选择来自数据连接向导,然后通过建立数据向导来与MySQL连接,如下图所示:
(2)Python实现
Python导入SQL文件主要分为两步,第一步将Python与数据库进行连接,第二步是利用Python执行SQL查询语句。
将python与数据库连接时利用的是python模块,这个模块Anaconda没有,需要我们手动安装的,打开Anaconda Promt,然后输入pip install pymysql进行安装即可,安装完成以后直接用import导入就可以使用了,具体连接方法如下:

连接好数据库以后,我们就可以执行SQL查询语句了,利用的是read_sql()方法。


除了sql和con这两个关键参数,read_table()函数也有用来设置行索引的参数index_col,设置列索引的columns,实例如下:
 二、新建数据
二、新建数据这里的新建数据主要指新建DataFrame数据,我们在之前谈到过,利用pd.Dataframe()方法进行新建。
三、熟悉数据当我们有了数据源以后,先别急着分析,应该先熟悉数据,只有对数据充分熟悉了,才能更好的进行分析。
1、利用head预览前几行
当数据表中包含数据行数过多时,而我们又想看一下每一列数据都是什么样的数据时,就可以只把数据表中前几行数据显示出来进行查看。
(1)Excel实现
Excel其实没有严格意义的显示前几行,当你打开一个数据表时,所有的数据就全部都展示出来了,如果数据的行数过多,则可以通过滚动条来控制。
(2)Python实现
在Python中,当一个文件导入后,可以用head()方法来控制要显示哪些行。只需要在head后面的括号中输入要展示的行数即可,默认展示前5行。

2、利用shape获取数据表的大小
熟悉数据的第一点就是先看一下数据表的大小,即数据表有多少行、多少列。
(1)Excel实现
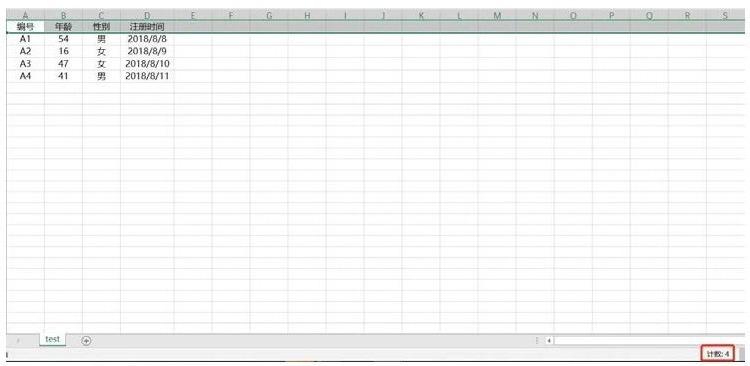
在Excel中查看数据表有多少行,一般都是选中某一列,右下角就会出现该表的行数,如下图所示:

在Excel中选中某一行,右下角就会出现该表的列数,如下图所示:
(2)Python实现
在Python中获取数据表的行、列数利用的是shape方法。

Shape方法会以元组的形式返回行、列数,上面代码中的(4,4)表示df表有4行4列数据。这里需要注意的是,Python中利用shape方法获取行数和列数时不会把行索引和列索引计算在内,而Excel中是把行索引和列索引计算在内的。
3、利用info获取数据类型
熟悉数据的第二点就是看一下数据类型,不同的数据类型的分析思路是不一样的,比如数值类型的数据可以求均值,但是字符串类型的数据就没法求均值了。
(1)Excel实现
在Excel中若想看某一列数据具体是什么类型的,只要把这一列选中,然后再菜单栏中的数字那一栏就可以看到这一列的数据类型。
年龄为数值类型,如下图所示:

性别为文本类型,如下图所示:

(2)Python实现
在Python中我们可以利用info()方法查看数据表中的数据类型,而且不需要一列一列查看,在调用info()方法以后就会输出整个表中所有列的数据类型。

通过info()方法可以看出表df的行索引index是0到3,总共4columns,分别是编号、年龄、性别以及注册时间,且4columns中只有年龄是int类型,其他columns都是object类型,共占用内存208bytes。
4、利用describe获取数值分布情况
熟悉数据的第三点就是掌握数值的分布情况,即均值是多少,最值是多少,方差及分位数分别又是多少。
(1)Excel实现
在Excel中如果想看某列的数值分布情况,那么手动选中这一列,在Excel的右下角就会显示出这一列的平均值、计数及求和,且只显示这三个指标,如下图所示。

(2)Python实现
在Python中只需要利用describe()方法就可以获取所有数值类型字段的分布值。


表df中只有年龄这一列是数值类型,所以调用describe()方法时,只计算了年龄这一列的相关数值分布情况。我们可以新建一个含有多列数值类型字段的DataFrame。

上面的表df中年龄、收入、家属数都是数值类型,所以在调用describe()方法的时候,会同时计算这三列的数值分布情况。

作者 | CDA数据分析师
从菜市场买来的菜,总有一些不太好的,所以把菜买回来以后要先做一遍预处理,把那些不太好的部分扔掉。现实中大部分的数据都类似于菜市场的菜品,拿到以后都要先做一次预处理。
常见的不规整的数据主要有缺失数据、重复数据、异常数据几种,在开始正式的数据分许之前,我们需要先把这些不太规整的数据处理掉。
一、缺失值的处理缺失值就是由某些原因导致部分数据为空,对于为空的这部分数据我们一般有两种处理方式,一种是删除,即把含有缺失值的数据删除;另一种是填充,即把缺失的那部分数据用某个值代替。
1、缺失值查看
对缺失值进行处理,首先要把缺失值找出来,也就是查看哪列有缺失值。
(1)Excel实现
在Excel中我们先选中一列没有缺失值的数据,看一下这一列数据共有多少个,然后把其他列的计数与这一列进行对比,小于这一列数据个数的就代表有缺失值,差值就是缺失的个数。
下图中非缺失值列的数据计数为5,性别这一列的计数为4,这就表示性别这一列有1个缺失值。

如果想看整个数据表中每列数据的缺失情况,则要挨个选中每一列去判断该列是否有缺失值。
如果数据不是特别多,你想看具体是哪个单元格缺失,则可以利用定位条件(按快捷键Ctrl+G可弹出定位条件的对话框)查找。在定位条件的对话框中选择空值,单击确定就会把所有的空值选中,如下图所示:

通过定位条件把缺失值选出来的结果,如下图所示:

(2)Python实现
在Python中直接调用info()方法就会返回每一列值的缺失情况。关于info()方法我们在前面就用过,但是没有说明这个方法可以判断数据的缺失情况。

Python中缺失值一般用NaN表示,从用info()方法的结果来看,性别这一列是3non-null object,表示性别这一列有3个非null值,而其他列有4个非null值,说明性别这一列有一个null值。
我们还可以用isnull()方法来判断那个值是缺失值,如果是缺失值则返回True,如果不是缺失值则返回False。

2、缺失值删除
缺失值分为两种,一种是一行中某个字段是缺失值;另一种是一行中的一个字段全部为缺失值,即为一个空白行。
(1)Excel实现
在Excel中,这两种缺失值都可以通过在定位条件(按快捷键Ctrl+G可弹出定位条件的对话框)对话框中选择空值找到。
这样含有缺失值的部分就会被选中,包括某个具体的单元格及一整行,然后单击鼠标右键在弹出的删除对话框中选择删除整行选项,并单击确定按钮即可实现整行的删除。

(2)Python实现
在Python中,我们利用的是dropna()的方法,dropna()的方法默认删除含有缺失值的行,也就是只有某一行有缺失值就把这一行删除。

运行dropna()方法以后,删除含有NaN的行,返回删除后的数据。如果想删除空白行,只要给dropna()方法传入一个参数how=all即可,这样就会只删除哪些全为空值的行了,不全为空值的行就不会被删除。


上表第二行中只有性别这个字段是空值,所以在利用dropna(how=“all”)的时候并没有删除第二行,只是把全为NaN值的第三行删除掉了。
3、缺失值填充
上面 介绍了缺失值的删除,但是数据是宝贵的,一般情况下只要数据缺失比例不是过高(不大于30%),尽量别删除,而是选择填充。
(1)Excel实现
在Excel中,缺失值的填充和缺失值的删除一样,利用的也是定位条件,先把缺失值找到,然后在第一个缺失值的单元格中输入要填充的值,最常用的就是用0填充,输入以后按Ctrl+Enter组合键就可以对所有的缺失值进行填充。
缺失值填充前后的对比如下图所示:

年龄用数字填充合适,但是性别用数字填充就不太合适,那么可不可以分开填充呢?答案是可以的,选中要填充的那一列,按照填充全部数据的方式进行填充即可,只不过要填充几列,需要执行几次操作。

上图是填充前后的对比,年龄这一列我们用平均值进行填充,性别这一列我们用众数进行填充。
除了用0填充、平均值填充、众数(大多数)填充,还有向前填充(即用缺失值的前一个非缺失值填充,比如上例中编号A3对应的缺失年龄的前一个非缺失值就是16)、向后填充(与向前填充对应)等方式。
(2)Python实现
在Python中,我们利用的fillna()方法对数据表中的所有缺失值进行填充,在fillna后面的括号中输入要填充的值即可。

在Python中我们也可以按不同列填充,只要在fillna()方法的括号中指明列名即可。

上面代码中只针对这一列进行了填充,其他列未进行任何更改。
也可以同时对多列填充不同的值:

重复数据就是同样的记录有多条,对于这样的数据我们一般做删除处理。
假设你是一名数据分析师,你的主要工作是分析公司的销售情况,现有公司2018年8月的销售明细(一直一条明细对应一笔成交记录),你想看一下8月份整体成交量是多少,最简单的方式就是看一下有多少条成交明细。但是这里可能会有重复的成交记录存在,所以要先删除重复项。
(1)Excel实现
在Excel中依次单击菜单栏中的数据>数据工具>删除重复值,就可以删除重复数据了,如下图所示:

删除前后的对比如下图所示:

Excel的删除重复值默认针对所有值进行重复值判断,有订单编号、客户姓名、唯一识别码(类似于身份证号)、成交时间这四个字段,Excel会判断这四个字段是否都相等,只有都相等时才会删除,且保留第一个(行)值。
你知道了公司8月份成交明细以后,你想看一下8月份总共有多少成交客户,且每个客户在8月份首次成交的日期。
查看客户数量只需要按客户的唯一识别码进行去重就可以了。Excel默认是全选,我们可以取消全选,选择唯一识别码进行去重,这样重要唯一识别码重复就会被删除,如下图所示:

因为Excel默认会保留第一条记录,而我们又想要获取每个客户的较早成交日期,所以我们需要先对时间进行升序排列,让较早的时间排在前面,这样在删除的时候就会保留较早的成交日期了。
删除前后的对比如下图所示:

(2)Python实现
在Python中我们利用drop_duplicates()的方法,该方法默认对所有值进行重复值判断,且默认保留第一个(行)值。
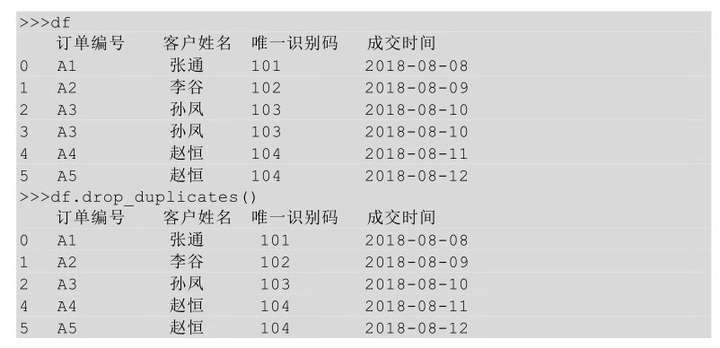
上面的代码是针对所有字段进行的重复值判断,我们同样也可以只针对某一列或者某几列进行重复值删除的判断,只需要在drop_duplicates()方法中指明要判断的列名即可。


也可以利用多列去重,只需要把多个列名以列表的形式传给参数subset即可。比如按姓名和唯一识别码去重。

还可以自定义删除重复项时保留哪个,默认保留第一个,也可以设置保留最后一个,或者全部不保留。通过传入参数keep进行设置,参数keep默认值是first,即保留第一个值;也可以是last,保留最后一个值;还可以是False,即把重复值全部删除。

异常值就是相比正常数据而言过高或者过低的数据,比如一个人的年龄是0岁或者300岁都算是一个异常值,因为这和实际情况差距过大。
1、异常值检测
要处理异常值首先要检测,也就是发现异常值,发现异常值的方式主要有以下三种。
●根据业务经验划定不同指标的正常范围,超过该范围的值算作异常值。
●通过绘制箱型图,把大于(小于)箱型图上边缘(下边缘)的点称为异常值
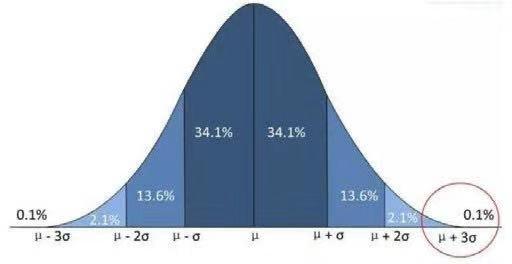
●如果数据服从正态分布,则可以利用3σ原则;如果一个数值与平均值之间的偏差超过三倍标准差,那么我们就认为这个值是异常值。
箱型图如下图所示:

下图为正太分布图,我们把大于μ+3σ的值称为异常值。
2、异常值处理
对于异常值一般有以下几种处理方式:
●最常用的处理方式就是删除。
●把异常值当做缺失值处理。
●把异常值当做特殊情况,研究异常值出现的原因。
(1)Excel实现
在Excel中,删除异常值只要通过筛选把异常值对应的行找出来,然后单击鼠标右键选择删除即可。
对异常值进行填充,其实就是对异常值进行替换,同样通过筛选功能把异常值先找出来,然后把这些异常值替换成要填充的值即可。
(2)Python实现
在Python中,删除异常值用到的方法和Excel中的方法原理类似,在Python中是通过过滤的方法对异常值进行删除。比如df表中有年龄这个指标,要把年龄大于200的值删掉,你可以通过筛选把年龄不大于200的筛选出来,筛出来的部分就是删除大于200的值以后的新表。
对异常值进行填充,就是对异常值进行替换,利用replace()方法可以对特定的值进行替换。
1、数据类型
(1)Excel实现
在Excel中常用的数据类型就是在菜单栏中数字选项下面的几种,你可以选择其他数据格式,如下图所示:

在Excel中只要选中某一列就可以在菜单栏看到这一列的数据类型。
当选中成交时间这一列的时候,菜单栏中就会显示日期,表示成交时间这一列的数据类型是日期格式,如下图所示:

(2)Python实现
Pandas不像Excel分的那么详细,它主要有6种数据类型,如下图所示:

在Python中,不仅可以用info()方法获取每一列的数据类型,还可以通过dtype方法来获取某一列的数据类型。

2、类型转换
我们在前面说过,不同数据类型的数据可以做的事情是不一样的,所以我们需要对数据进行类型转化,把数据转换为我们需要的类型。
(1)Excel实现
在Excel中如果想要改变某一列的数据类型,只要选中这一列,然后在数字菜单栏中通过下拉菜单选择你要转换的目标类型即可实现。
下图就是将文本类型的数据转换成数值类型的数据,数值类型的数据默认为两位小数,也可以设置成其他位数。

(2)Python实现
在Python中,我们利用astype()方法对数据类型进行转换,astype后面的括号里指明要转换的目标类型即可。

索引是查找数据依据,设置索引的目的是便于我们查找数据。举个例子,你逛超市买了很多食材。回到家以后要把他们放在冰箱里,放的过程其实就是一个建立索引的过程,比如蔬菜放在冷藏室里,肉类放在冷冻室里,这样找的时候就很快就可以找到了。
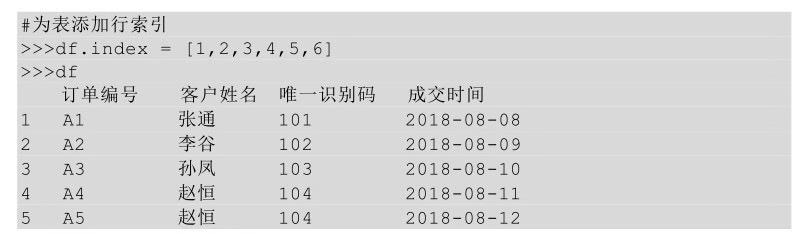
1、为无索引表添加索引
有的表没有索引,这时要给这类表加一个索引。
(1)Excel实现
在Excel中,一般都有索引的,如果没索引数据看起来会很乱,当然也会有例外,数据表就是没有索引的。这时候插入一行一列就是为表添加索引。
添加索引前后的对比如下图所示,序号列为行索引,字段名称为列索引。

(2)Python实现
在Python中,如果表没有索引,会默认用从0开始的自然数做索引,比如下面这样:

通过给表df的columns参数传入列索引值,index参数传入行索引值达到为无索引表添加索引的目的,具体实现如下:

2、重新设置索引
重新设置索引,一般指行索引的设置。有的表虽然有索引,但不是我们想要的索引,比如现在有一个表是把序号作为行索引,而我们想要吧订单编号作为行索引,该怎么实现呢?
(1)Excel实现
在Excel中重新设置行索引比较简单,你想让哪一列做行索引,直接把这一列拖到第一列的位置即可。
(2)Python实现
在Python中可以利用set_index()方法重新设置索引列,在set_index()里指明要用作行索引的列的名称即可。

在重新设置索引时,还可以给set_index()方法传入两个或者多个列名,我们把这种一个表中用哪个多列来做索引的方式称为层次化索引,层次化索引一般用在某一列中含有多个重复值的情况下。层次化索引的例子,如下所示,其中a、b、c、d分别有多个重复值。

3、重命名索引
重命名索引是针对现有的索引名进行修改的,就是改字段名。
(1)Excel实现
在Excel中重命名索引比较简单,就是直接修改字段名。
(2)Python实现
在Python中重命名索引,我们利用的是rename()方法,在rename后的括号里指明要修改的行索引及列索引名。

4、重置索引
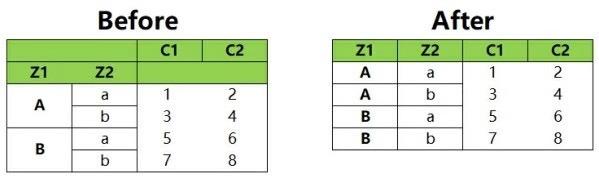
重置索引主要用在层次化索引表中,重置索引是将索引列当做一个columns进行返回。
在下图左侧的表中,Z1,Z2是一个层次化索引,经过重置索引以后,Z1、Z2这两个索引以columns的形式返回,变为常规的两列。
在Excel中,我们要进行这种转换,直接通过复制、粘贴、删除等功能就可以实现,比较简单。我们主要讲一下在Python中怎么实现。
在Python利用的是reset_index()方法,reset_index()方法常用的参数如下:

level参数用来指定要将层次化索引的第几级别转化为columns,第一个索引为0级,第二个索引为1级,默认为全部索引,即默认吧索引全部转化为columns。
drop参数是用来指定是否将原索引删掉,即不作为一个新的columns,默认为False,即不删除原索引。
inplace参数用来指定是否修改原数据表。

reset_index()方法常用于数据分组、数据透视表中。

作者 | CDA数据分析师
在数据选择之前是要把所有的菜品都洗好并放在不同的容器里。现在要进行切配了,需要把这些菜品挑选出来,比如做一盘凉拌黄瓜,需要先把黄瓜找出来;要做一盘可乐鸡翅,需要先把鸡翅找出来。
数据分析也是同样的道理,你要分析什么,首先要把对应的数据筛选出来。
常规的数据选择主要有列选择、行选择、行列同时选择三种方式。
一、列选择1、选择某一列/某几列
(1)Excel实现
在Excel中选择某一列直接用鼠标选中这一列即可;如果要同时选择多列,且待选择的列不是相邻的,这个时候就可以先选中其中一列,然后按住Ctrl键不放,再选择其他列。举个例子,同时选择客户姓名和成交时间这两列,如下图所示:
(2)Python实现
在Python中我们想要获取某列只需要在表df后面的方括号中指明要选择的列名即可。如果是一列,则只需要传入一个列名;如果是同时选择多列,则传入多个列名即可,多个列名用一个list存起来。


在Python中我们把这种通过传入列名选择数据的方法称为普通索引。
除了传入具体的列名,我们还可以传入具体列的位置,即第几列,对数据进行选取,通过传入位置来获取数据时需要用到iloc方法。

在上面的代码中,iloc后的方括号中逗号之前的部分表示要获取行的位置,只输入一个冒号,不输入任何数值表示获取所有的行;逗号之后的方括号表示要获取的列的位置,猎德位置同样是也是从0开始计数。
我们把这种通过传入具体位置来选择数据的方式称为位置索引。
2、选择连续的某几列
(1)Excel实现
在Excel中,要选择连续的几列时,直接用鼠标选中这几列即可操作。当然了,你也可以先选择一列,然后按住Ctrl键再去选择其他列,由于要选取的列时连续的,因此没有必要这么麻烦。
(2)Python实现
在Python中可以通过前面介绍的普通索引个位置索引获取某一列或多列的数据。当你要获取的是连续的某几列,用普通索引和位置索引也是可以做到的,但是因为你要获取的列是连续的,所以只要传入这些连续列的位置区间即可,同样需要用到iloc方法。

在上面的代码中,iloc后的方括号中逗号之前的表示选择的行,当只传入一个冒号时,表示选择所有行;逗号后面表示要选择列的位置区间,0:3表示选择第1列到第4列之间的值(包含第1列单不包含第4列),我们把这种通过传入一个位置区间来获取数据的方式称为切片索引。
二、行选择1、选择某一行/某几行
(1)Excel实现
在Excel中选择行与选择列的方式是一样的,先选择一行,按住Ctrl键再选择其他行。
(2)Python实现
在Python中,获取行的方式主要有两种,一种是普通索引,即传入具体行索引的名称,需要用到loc方法;另一种是位置索引,即传入具体的行数,需要用到iloc方法。
为了看的更清楚,我们对行索引进行自定义。

2、选择连续的某几行
(1)Excel实现
在Excel中选择连续的某几行与选择连续的某几列的方法一致,不在赘述。
(2)Python实现
在Python中,选择连续的某几行时,你同样可以把要选择的每一个行索引名字或者行索引的位置输进去。很显然这是没有必要的,只要把连续行的位置用一个区间表示,然后传给iloc即可。

3、选择满足条件的行
前面说到获取某一列时,获取的是这一列的所有行,我们还可只筛选出这一列中满足条件的值。
比如年龄这一列,需要把非异常值(大于200的属于异常值),即小于200岁的年龄筛选出来,该怎么实现呢?
(1)Excel实现
在Excel中我们直接使用筛选功能,将满足条件的值筛选出来,筛选方法如下图所示:

筛选年龄小于200的数据前后的对比如下图所示:。
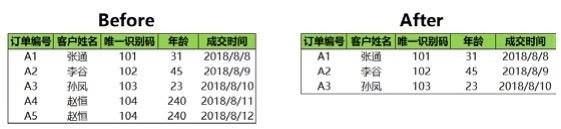
(2)Python实现
在Python中,我们直接在表名后面指明哪列要满足什么条件,就可以把满足条件的数据筛选出来。

我们把上面这种通过传入一个判断条件来选择数据的方式称为布尔索引。
传入的条件也可以是多个,如下为选择的年龄小于200且唯一识别码小于102的数据。
 三、行列同时选择
三、行列同时选择上面的数据选择都是针对单一的行或者列进行选择,实际业务中我们也会用到行、列同时选择,所谓的行、列同时选择就是选择出行和列的相交部分。
例如,我们要选择第二、三行和第二、三列相交部分的数据,下图中的阴影部分就是最终的选择结果。

行列同时选择在Excel中主要是通过鼠标拖拽实现的,与前面的单一行/列选择方法一致,此处不再赘述,接下来主要讲讲在Python中是如何实现的。
1、普通索引+普通索引选择指定的行和列
位置索引+位置索引是通过同时传入行、列索引的位置来获取数据,需要用到iloc方法。

loc方法中的第一对方括号表示行索引的选择,传入行索引的名称;loc方法中的第二对方括号表示列索引的选择,传入列索引的名称。
2、位置索引+位置索引选择指定行和列
位置索引+位置索引是通过同事传入行、列索引的位置来获取数据,需要用到iloc方法。

在iloc方法中的第一对方括号表示行索引的选择,传入要选择行索引的位置;第二对方括号表示列索引的选择,传入要选择列索引的位置。行和列索引的位置都是从0开始计数的。
3、布尔索引+普通索引选择指定的行和列
布尔索引+普通索引是先对表进行布尔索引选择行,然后通过普通索引选择列。

上面的代码表示选择年龄小于200的订单编号和年龄,先通过布尔索引选择出年龄小于200的所有行,然后通过普通索引选择订单编号和年龄这两列。
4、切片索引+切片索引选择指定的行和列
切片索引+切片索引是通过同时传入行、列索引的位置区间进行数据选择。

5、切片索引+普通索引选择指定的行和列
前面我们说过,如果是普通索引,就直接传入行或者列名,用loc方法即可;如果是切片索引,也就是传入行或者列的位置区间,要用iloc方法。如果是切片索引+普通索引,也就是行(列)用切片索引,列(行)用普通索引,这种交叉索引要用ix方法。

数值替换就是将数值A替换成B,可以用在异常值替换处理、缺失值填充处理中。主要有一对一替换、多对一替换、多对多替换三种替换方法。
1、一对一替换
一对一替换是将某一块区域中的一个值全部替换成另一个值。已知现在有一个年龄值是240,很明显这是一个异常值,我们要把它替换成一个正常范围内的年龄值(用正常年龄的均值33),怎么实现呢?
(1)Excel实现
在Excel中对某个值进行替换,首先要把待替换的区域选中,如果只是替换某一列中的值,只需要选中这一列即可;如果要在这一片区域中进行替换,那么拖动鼠标选中这一片区域。然后依次单击编辑菜单栏中的查找和选择>;替换选项(如下图所示)即可调出替换界面。使用快捷键Ctrl+H也可以调出替换界面。

下图为替换界面,分别输入查找内容和替换内容,然后根据需要单击全部替换或者替换全部即可。
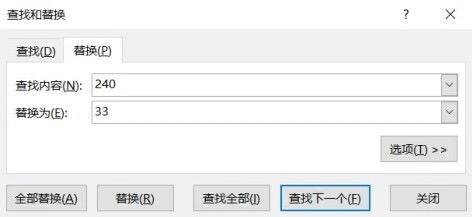
(2)Python实现
在python中对某个值进行替换利用的是replace()方法,replace(A,B)表示将A替换成B。

上面的代码是对年龄这一列进行替换,所以把年龄这一列选中,然后调用replace()方法。有时候要对整个表进行替换,比如对全表中的缺失值进行替换,这个时候replace()方法就相当于fillna()方法了。


Np.NaN是python中对缺失值的一种表示方法。
2、多对一替换
多对一替换就是把一块区域中的多个值替换成某一个值,已知现在有三个异常年龄(240、260、280)需要把这三个年龄都替换成正常范围年龄的平均值33,该怎么实现呢?
(1)Excel实现
在Excel中需要借助if函数来实现多对一替换。一直年龄这一列是D列,要想对这个异常值进行替换,可以通过如下函数实现。

上面的公式借助了Excel中的OR()函数,表示如果D列等于240、260、或者280时,该单元格的值为33,否则为D列的值。替换后的结果如下图所示。

(2)Python实现
在 Python 中实现多对一的替换比较简单,同样也是利用replace()方法,replace([A,B],C)表示将A、B替换成C。
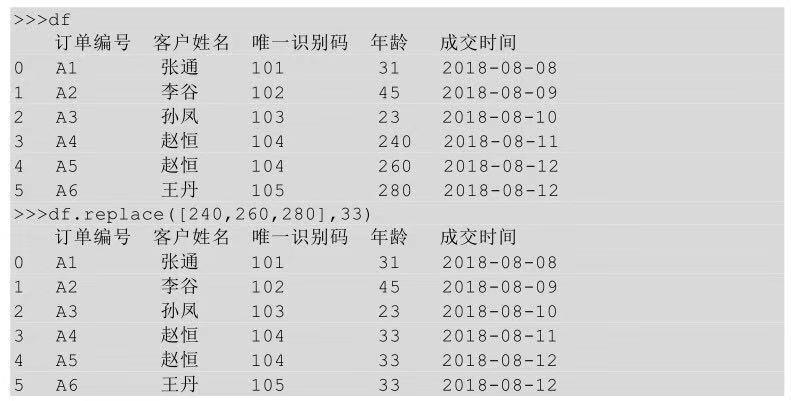
3、多对多替换
多对多替换其实就是某个区域中多个一对一的替换。比如将年龄异常值240替换成平均值减一,260替换成平均值,280替换成平均值加一,该怎么实现呢?
(1)Excel实现
若想在Excel中实现,需要借助函数,且需要多个if嵌套语句来实现,同时已知年龄列为D列,具体函数如下:

下图为该函数执行的流程。

替换后的结果如下图所示:

(2)Python实现
在Python中若想实现多对多的替换,同样是借助replace()方法,将替换值与待替换值用字典的形式表示,replace(“A”:“a”,“B”:“b”)表示用a替换A,用b 替换B。
 二、数值排序
二、数值排序数值排序是按照具体数值的大小进行排序的,有升序和降序两种,升序就是数值由小到大排列,降序是数值由大到小排列。
1、按照一列数值进行排序
按照一列数值进行排序就是整个数据表都以某一列为准,进行升序或者降序排列。
(1)Excel实现
在Excel中想要按照某列进行数值排序,只要选中这一列的字段名,然后单击编辑菜单栏下的排序和筛选按钮;在下拉菜单中选择升序或者降序选项即可,操作流程如下图所示。

按照销售ID进行升序排列前后的结果如下图所示:

(2)Python实现
在Python中我们若想按照某列进行排序,需要用到sort_values()方法,在sort_values后的括号中指明要排序的列名,以及升序还是降序排序。

上面代码表示df表按照col1列进行排序,ascending = False表示按照col1列进行降序排列。Ascending参数默认值为True,表示升序排列。所以,如果是要根据col1进行升序排序,则可以只指明列名,不需要额外声明排序方式。


2、按照有缺失值的列进行排序
(1)Python实现
在Python中,当待排序的列中有缺失值时,可以通过设置na_position参数对缺失值的显示位置进行设置,默认参数值为last,可以不写,表示将缺失值显示在最后。

通过设置na_position参数将缺失值显示在最前面。

3、按照多列数值进行排序
按照多列数值排序是指同时依据多列数据进行升序、降序排序,当第一列出现重复值时按照第二列进行排序,当第二天出现重复值时按照第三列进行排序,以此类推。
(1)Excel实现
在Excel中实现按照多列排序,选中待排序的所有数据,单击编辑菜单栏下的排序和筛选按钮,在下拉菜单中选择自定义排序选项就会出现如下图所示界面。添加条件就是添加按照排序的列,在次序里面可以单独定义每一列的升序或者降序。
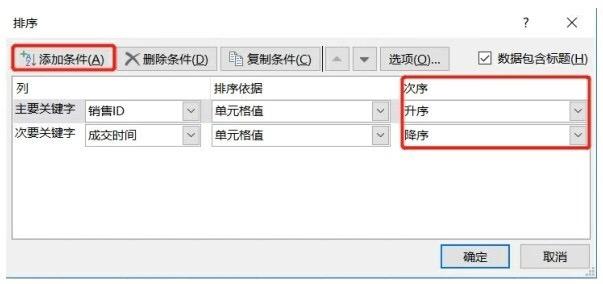
举个例子,对下图左侧的Before表先按照销售ID升序排列,当遇到重复的销售ID时,再按成交时间降序排列,得出下图右侧的After表。

(2)Python实现
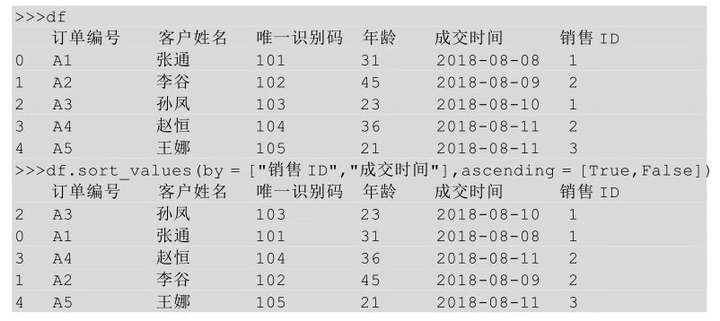
在Python中实现按照多列进行排序,用到的方法同样是sort_values(),只要sort_values()后的括号中以列表的形式指明要排序的多列列名及每列的排序方式即可。

上面代码表示df表现按照col1列进行升序排列,当col1 列遇到重复值时,再按照col2列进行降序排列。对于表df我们依旧先按照销售ID升序排列,当遇到重复的销售ID时,再按照成交时间降序排列,代码如下图所示:
 三、数值排名
三、数值排名数值排名和数值排序是相对应的,排名会新增一列,这一列用来存放数据的排名情况,排名是从1开始的
(1)Excel实现
在Excel中用于排名的函数有RANK.AVG()和RANK.EQ()两个。
当待排名的数值没有重复值时,这两个函数的效果是完全一样的,两个函数的不同在于处理重复值方式不同。
●RANK.AVG(number,ref,order)
number表示待排名的数值,ref表示一整列数值的范围,order用来指明降序还是升序排名。当待排名的数值由重复值时,返回重复值的平均排名。
对销售ID进行平均排名以后的结果如下图所示。图中销售ID为1的值有两个,假设一个排名是1,另一个排名是2,那么二者的均值就是1.5,所以平均排名就是1.5;销售ID为2的值同样有两个,同样假设一个排名为3 ,另一个排名为4,那么二者的均值是3.5;销售ID为3的值没有重复值,所以排名就是5。

●RANK.EQ(number,ref,order)
RANK.EQ的参数与RANK.AVG的意思是一样的。当待排名的数值有重复值时,RANK.EQ返回重复值的最佳排名。
对销售ID进行最佳排名以后的结果如下图所示。图中销售ID为1的值有两个,第一个重复值的排名为1,所以两个值的最佳排名均为1 ;销售ID为2的值也有两个,第一个重复值的排名为3,所以两个值的最佳排名均为3,;销售ID为3的值没有重复值,最佳排名为5。

(2)Python实现
在Python中对数值进行排名,小用到rank()方法。Rank()方法主要有两个参数,一个是ascending,用来指明升序排列还是降序排列,默认升序排列,和Excel中的order的意思一致;另一个是method,用来指明待排列值有重复值时的处理情况。下表是参数method可取的不同参数值及说明。

method取值为average时的排名情况,与Excel中RANK.AVG函数一致。

method取值为first时的排名情况,销售ID为1的值有两个,第一个出现的排名为1,第二个出现的排名为2;销售ID为2的以此类推。

method取值为min时的排名情况,与Excel中RANK.EQ函数一致。

method取值为max时的排名情况,与method取值min时相反,销售ID为1的值有两个,第二个重复值的排名为2,所以两个值的排名均为2;销售ID为2的值有两个,两个重复值的排名为4,所以两个值的排名均为4。
 四、数值删除
四、数值删除数值删除是对数据表中一些无用的数据进行删除操作。
1、删除列
(1)Excel实现
在Excel中,要删除某一列或某几列,只需要选中这些列,然后单击鼠标右键,在弹出的菜单中选择删除选项即可(或者单击鼠标右键以后按D键),如下图所示。

(2)Python实现
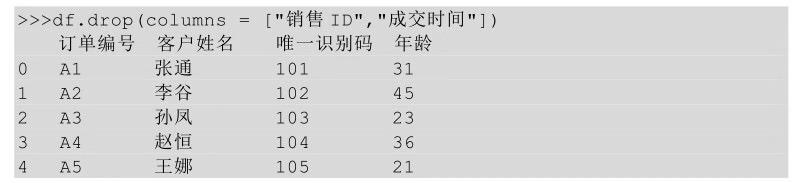
在Python中,要删除某列,用到的是drop()方法,即在drop方法后的括号中指明要删除的列名或者列的位置,即第几列。
在drop方法后的括号中直接传入待删除列的列名,需要加一个参数axis,并让其参数值等于1,表示删除列。


还可以在drop方法后的括号中直接传入待删除列的位置,但也需要用axis参数。

也可以将列名以列表的形式传给columns参数,这个时候就不需要axis参数了。
2、删除行
(1)Excel实现
在 Excel 中,要删除某些行使用的方法与删除列是一致的,先选中要删除的行,然后单击鼠标右键,在弹出的下拉菜单中选择删除选项就可以删除行了。
(2)Python实现
在Python中,要删除某些行用到的方法依然是drop(),与删除列类似的是,删除行也要指明行相关的信息。
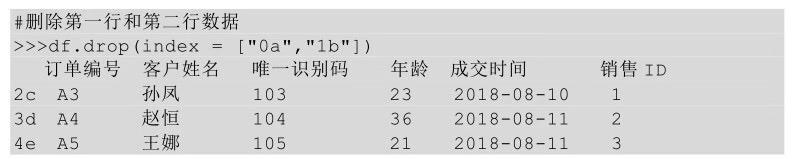
在drop方法后的括号中直接传入待删除行的行名,并让axis参数值等于0,表示删除行。

除了传入行索引名称,还可以在drop方法后的括号中直接传入待删除行的行号,也需要用axis参数,并让其参数值等于0。

也可以将待删除行的行名传给index参数,这个时候就不需要axis参数了。
3、删除特定行
删除特定行一般指删除满足某个条件的行,我们前面的异常值删除算是删除特定的行。
(1)Excel实现
在Excel中删除特定行分为两步,第一步先将符合条件的行筛选出来,第二步选中这些筛选出来的行然后单击鼠标右键,在弹出的下拉菜单中选择删除选项。
(2)Python实现
在Python中删除特定行使用的方法有些特殊,我们不直接删除满足条件的值,而是把不满足条件的值筛选出来作为新的数据源,这样就把要删除的行过滤掉了。
在如下例子中,要删除年龄值大于等于40对应的行,我们并不直接删除这一部分,而是把它的相反部分取出来,即把年龄小于40的行筛选出来作为新的数据源。
 五、数值计数
五、数值计数数值计数就是计算某个值在一系列数值中出现的次数。
(1)Excel实现
在Excel中实现数值计数,我们使用的是COUNTIF()函数,COUNTIF()函数用来计算某个区域中满足给定条件的单元格数目。

range表示一系列值的范围,criteria表示某一个值或者某一个条件。
销售ID的值的计数结果如下图所示。销售ID为1的值在F2:F6这个范围内出现了两次;销售ID为2的值在该范围内也出现了两次;销售ID为3的值出现了1次。

(2)Python实现
在Python中,要对某些值的出现次数进行计数,我们用到的方法是value_counts()。

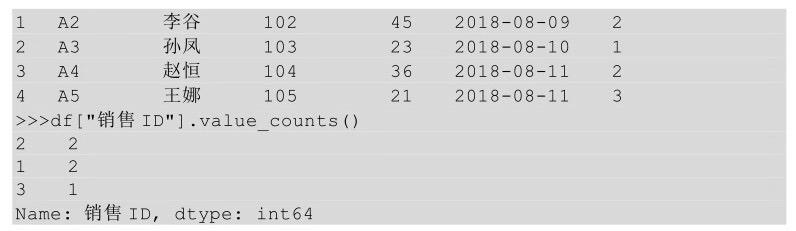
上面代码运行的结果表示销售ID为2的值出现了两次,销售ID为1的值出现了两次,销售ID为3的值出现了1次。这些是值出现的绝对次数,还可以看一下不同值出现的占比,只需要给value_counts()方法传入参数normalize = True即可。

上面代码的运行结果表示销售ID为2的值的占比为0.4,销售ID为1的值的占比为0.4,销售ID为3的值的占比为0.2。上面销售ID的排序是2、1、3,这是按照计数值降序排列的(0.4、0.4、0.2),通过设置sort=False可以实现不按计数值降序排列。
 六、唯一值获取
六、唯一值获取唯一值获取就是把某一系列值删除重复项以后的结果,一般可以将表中某一列认为是一系列值。
(1)Excel实现
在Excel中,我们若想查看某一列数值中的唯一值,可以把这一列数值复制粘贴出来,然后删除重复项,剩下的就是唯一值了。
(2)Python实现
在Python中,我们要获取一列值的唯一值,整体思路与Excel的是一致的,先把某一列的值复制粘贴出来,然后用删除重复项的方法实现,关于删除重复项在前面讲过了,本节用另一种获取唯一值的方法unique()实现。
举个例子,对表df中的销售ID取唯一值,先把销售ID取出来,然后利用unique()方法获取唯一值,代码如下所示。
 七、数值查找
七、数值查找数值查找就是查看数据表中的数据是否包含某个值或者某些值。
(1)Excel实现
在Excel中我们要想查看数据表中是否包含某个值可以直接利用查找功能。首先要把待查找区域选中,可以选择一列或者多列,如果不选,则默认在全表中查询,然后单击编辑菜单栏的查找和选择按钮,在下拉菜单中选择查找选项,如下图所示。

下图为选择查找选项后弹出的查找和替换对话框(也可以使用快捷键Ctrl+F打开查找和替换对话框),在查找内容框输入要查找的内容即可,可以选择查找全部,这样就会把所有查找到的内容显示出来;也可以选择查找下一个,这样会把查找结果一个一个显示出来。

(2)Python实现
在Python中查看数据表中是否包含某个值用到的是isin()方法,而且可以同时查找多个值,只需要在isin方法后的括号中指明即可。
可以将某列数据取出来,然后在这一列上调用 isin()方法,看这一列中是否包含某个/些值,如果包含则返回True,否则返回False。

也可以针对全表查找是否包含某个值。
 八、区间切分
八、区间切分区间切分就是将一系列数值分成若干份,比如现在有10个人,你要根据这10个人的年龄将他们分为三组,这个切分过程就称为区间切分。
(1)Excel实现
在Excel中实现区间切分我们借助的是if函数,具体公式如下:

if函数的实现流程如下图所示。

下图为利用if嵌套函数实现的结果。

(2)Python实现
在Python中对区间切分利用的是cut()方法,cut()方法有一个参数bins用来指明切分区间。

cut()方法的切分结果是几个左开右闭的区间,(0,3]就表示大于0小于等于3,(3,6]表示大于3小于等于6,(6,10]表示大于6小于等于10。
与cut()方法类似的还有qcut()方法,qcut()方法不需要事先指明切分区间,只需要指明切分个数,即你要把待切分数据切成几份,然后它就会根据待切分数据的情况,将数据切分成事先指定的份数,依据的原则就是每个组里面的数据个数尽可能相等。


在数据分布比较均匀的情况下,cut()方法和 qcut()方法得到的区间基本一致,当数据分布不均匀,即方差比较大时,两者得到的区间的偏差就会比较大。
九、插入新的行或列在特定的位置插入行或者列也是比较常用的操作。具体的插入操作有两个关键要素,一个是在哪插入,另一个是插入什么。
(1)Excel实现
在Excel中要插入行或列首先要确定在哪一行或哪一列前面插入,然后选中这一列或这一行单击鼠标右键,在弹出的下拉菜单中选择插入选项即可。
要在唯一识别码列前面插入一列,选中唯一识别码这一列然后单击鼠标右键,在弹出的下拉菜单中选择插入选项即可,如下图所示。

完成上面的操作后,就会有一个新的空行或空列,在空行或空列里面输入要插入的数据即可。
(2)Python实现
在Python中没有专门用来插入行的方法,可以把待插入的行当作一个新的表,然后将两个表在纵轴方向上进行拼接。关于表拼接在后面的章节会讲。
在Python中插入一个新的列用到的方法是insert(),在insert方法后的括号中指明要插入的位置、插入后新列的列名,以及要插入的数据。


还可以直接以索引的方式进行列的插入,直接让新的一列等于某列值即可。

上面的代码表示新插入一列名为商品类别的值,这一列的值就是后面列表中的值。
十、行列互换所谓的行列互换(又称转置)就是将行数据转换到列方向上,将列数据转换到行方向上。
(1)Excel实现
在Excel中行列互换(转置)需要先把待转置的内容复制,然后粘贴在新的区域中,粘贴选项选择转置即可,转置选项如下图所示。
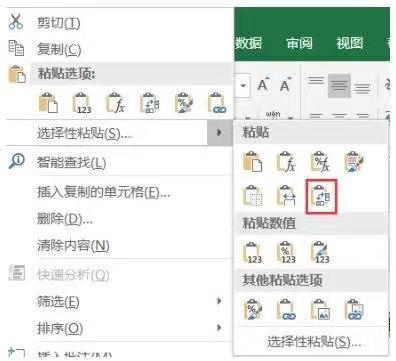
转置前后的效果对比如下图所示。

(2)Python实现
在 Python 中,我们直接在源数据表的基础上调用.T 方法即可得到源数据表转置后的结果。对转置后的结果再次转置就会回到原来的结果。
对表df进行转置,代码如下所示。

对转后的表再次进行转置,代码如下所示。
 十一、索引重塑
十一、索引重塑所谓的索引重塑就是将原来的索引进行重新构造。典型的DataFrame结构的表如下表所示。

上面这种表是典型的DataFrame结构,它用一个行索引和一个列索引来确定一个唯一值,比如S1-C1唯一值为1,S2-C3唯一值为6。这种通过两个位置确定一个唯一值的方法不仅可以用上述这种表格型结构表示,而且可以用一种树形结构来表示,如下图所示。
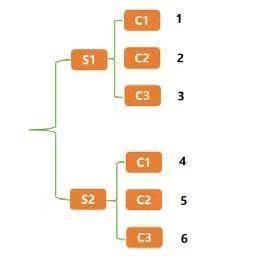
树形结构其实就是在维持表格型行索引不变的前提下,把列索引也变成行索引,其实就是给表格型数据建立层次化索引。
我们把数据从表格型数据转换到树形数据的过程叫重塑,这种操作在Excel中没有,在Python用到的方法是stack(),示例代码如下所示。

与stack()方法相对应的方法是unstack()方法,stack()方法是将表格型数据转化为树形数据,而unstack()方法是将树形数据转为表格型数据,示例代码如下所示。
 十二、长宽表转换
十二、长宽表转换长宽表转换就是将比较长(很多行)的表转换为比较宽(很多列)的表,或者将比较宽的表转化为比较长的表。
下表是一个宽表(有很多列)。

我们要把这个宽表转化为如下表所示的长表。
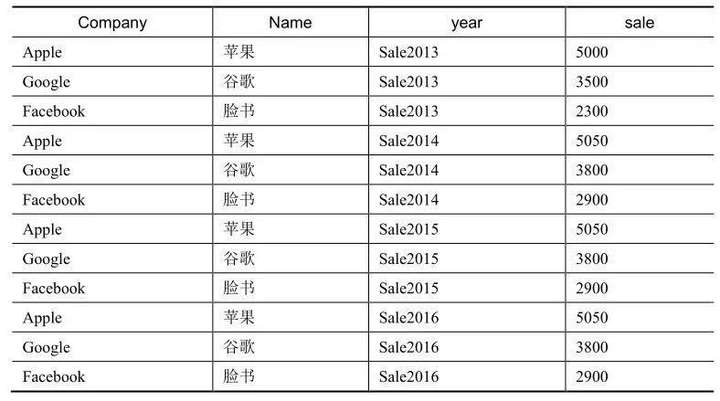
上面这种由很多列转换为很多行的过程,就是宽表转换为长表的过程,这种转换过程是有前提的,那就是需要有公共列。
1、宽表转换为长表
宽表转化为长表,在Excel中一般都用复制粘贴实现,我们主要看看在Python中如何实现。Python中要实现这种转换有两种方法,一种是stack()方法,另一种是melt()方法。
(1)stack()方法实现
stack()在将表格型数据转为树形数据时,是在保持行索引不变的前提下,将列索引也变成行索引。
这里将宽表转化为长表首先要在保持 Company 和 Name 不变的前提下,将Sale2013、Sale2014、Sale2015、Sale2016也变成行索引。所以,需要先将 Company和Nmae先设置成索引,然后调用stack()方法,将列索引也转换成行索引,最后利用reset_index()方法进行索引重置,示例代码如下所示。

(2)melt()方法实现
用melt()方法实现上述功能,代码如下所示。
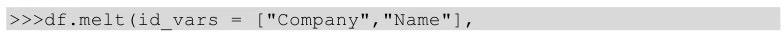
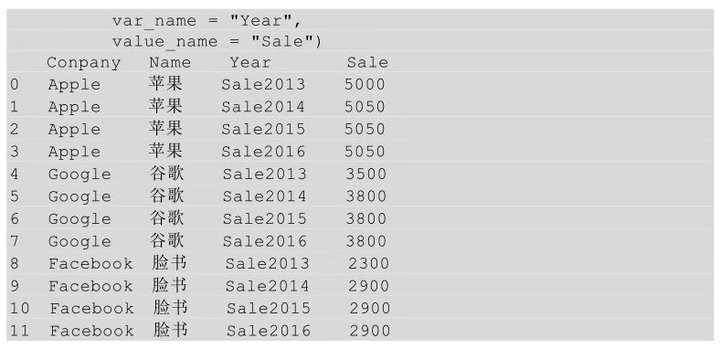
melt中的id_vars参数用于指明宽表转换到长表时保持不变的列,var_name参数表示原来的列索引转化为“行索引”以后对应的列名,value_name表示新索引对应的值的列名。
注意,这里的“行索引”是有双引号的,它并非实际行索引,只是类似实际的行索引。
2、长表转换为宽表
将长表转化为宽表就是宽表转化为长表的逆过程。常用的方法就是数据透视表,关于数据透视表的使用我们将在10.2节进行详细讲解,这里大概了解一下就行,具体实现如下:


上面的实现过程是把Company和Name设置成行索引,Year设置成列索引,Sale为值。
进行到这一步就可以算是开始正式的烹饪了,在这部分之前的数据操作部分我们列举了一些不同维度的分析指标,这一章我们主要看看这些指标都是怎么计算出来的。
一、算术运算算术运算就是基本的加减乘除,在Excel或者Python中数值类型的任意两列可以直接进行加、减、乘、除运算,Excel中的算术运算比较简单,这里就不展开了,下面主要介绍Python中的算术运算。
两列相加的具体实现如下图所示:

两列相减的具体实现如下图所示:

两列相乘的具体实现如下图所示:

两列相除的具体实现如下图所示:

任意一列加/减一个常数值,这一列中的所有值都加/减这个常数值,具体实现如下图所示:

任意一列乘/除一个常数值,这一列中的所有值都乘/除这个常数值,具体实现如下图所示:
 二、比较运算
二、比较运算比较运算和Python基础知识中讲到的比较运算一致,也是常规的大于、等于、小于之类的,只不过这里的比较是在列与列之间进行的。
在Excel中列与列之间的比较运算和Python中的方法一致,例子如下图所示。

下面是一些Python中列与列之间比较的例子。

 三、汇总运算
三、汇总运算上面讲到的算术运算和比较运算都是在列与列之间进行的,运算结果是有多少行的值就会返回多少个结果,而汇总运算是将数据进行汇总返回一个汇总以后的结果值。
1、count非空值计数
非空值计数就是计算某一个区域中非空(单元格)数值的个数。
在Excel中counta()函数用于计算某个区域中非空单元格的个数。与counta()函数类似的一个函数是count()函数,它用于计算某个区域中含有数字的单元格的个数。
在 Python 中,直接在整个数据表上调用 count()函数,返回的结果为该数据表中每列的非空值的个数,具体实现如下所示。

count()函数默认是求取每一列的非空数值的个数,可以通过修改axis参数让其等于1,来求取每一行的非空数值的个数。

也可以把某一列或者某一行索引出来,单独查看这一列或这一行的非空值个数。

2、sum求和
求和就是对某一区域中的所有数值进行加和操作。
在 Excel 中要求取某一区域的和,直接在 sum()函数后面的括号中指明要求和的区域,即要对哪些值进行求和操作即可。例子如下所示。

在Python中,直接在整个数据表上调用sum()函数,返回的是该数据表每一列的求和结果,例子如下所示。

sum()函数默认对每一列进行求和,可通过修改axis参数,让其等于1,来对每一行的数值进行求和操作。

也可以把某一列或者某一行索引出来,单独对这一列或这一行数据进行求和操作。

3、 mean求均值
求均值是针对某一区域中的所有值进行求算术平均值运算。均值是用来衡量数据一般情况的指标,容易受到极大值、极小值的影响。
在Excel中对某个区域内的值进行求平均值运算,用的是average()函数,只要在average()函数中指明要求均值运算的区域即可,比如:

在Python中的求均值利用的是mean()函数,如果对整个表直接调用mean()函数,返回的是该表中每一列的均值。

mean()函数默认是对数据表中的每一列进行求均值运算,可通过修改 axis 参数,让其等于1,来对每一行进行求均值运算。

也可以把某一列或者某一行通过索引的方式取出来,然后在这一行或这一列上调用mean()函数,单独求取这一行或这一列的均值。

4、 max求最大值
求最大值就是比较一组数据中所有数值的大小,然后返回最大的一个值。
在Excel和Python中,求最大值使用的都是max()函数,在Excel中同样只需要在max()函数中指明要求最大值的区域即可;在Python中,和其他函数一样,如果对整个表直接调用max()函数,则返回该数据表中每一列的最大值。max()函数也可以对每一行求最大值,还可以单独对某一行或某一列求最大值。


5、min求最小值
求最小值与求最大值是相对应的,通过比较一组数据中所有数值的大小,然后返回最小的那个值。
在Excel和Python中都使用min()函数来求最小值,它的使用方法与求最大值的类似,这里不再赘述。示例代码如下。

6、 median求中位数
中位数就是将一组含有n个数据的序列X按从小到大排列,位于中间位置的那个数。
中位数是以中间位置的数来反映数据的一般情况,不容易受到极大值、极小值的影响,因而在反映数据分布情况上要比平均值更有代表性。
现有序列为X:{X1、X2、X3、......、Xn}。
如果n为奇数,则中位数:

如果n为偶数,则中位数:
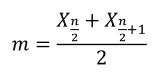
例如,1、3、5、7、9的中位数为5,而1、3、5、7的中位数为(3+5)/2=4。
在Excel和Python中求一组数据的中位数,都是使用median()函数来实现的。
下面为在Excel中求中位数的示例:

在Python中,median()函数的使用原则和其他函数的一致。

7、mode求众数
顾名思义,众数就是一组数据中出现次数最多的数,求众数就是返回这组数据中出现次数最多的那个数。
在Excel和Python中求众数都使用mode()函数,使用原则与其他函数完全一致。
在Excel中求众数的示例如下:

在Python中求众数的示例如下:


8、var求方差
方差是用来衡量一组数据的离散程度(即数据波动幅度)的。
在Excel和Python中求一组数据中的方差都使用var()函数。
下面为在Excel中求方差的示例:

在Python中,var()函数的使用原则和其他函数的一致。

9、std求标准差
标准差是方差的平方根,二者都是用来表示数据的离散程度的。
在Excel中计算标准差使用的是stdevp()函数,示例如下:

在Python中计算标准差使用的是std()函数,std()函数的使用原则与其他函数的一致,示例如下:

10、quantile求分位数
分位数是比中位数更加详细的基于位置的指标,分位数主要有四分之一分位数、四分之二分位数、四分之三分位数,而四分之二分位数就是中位数。
在Excel中求分位数用的是percentile()函数,示例如下:

在Python中求分位数用的是quantile()函数,要在quantile后的括号中指明要求取的分位数值,quantile()函数与其他函数的使用规则相同。

 四、相关性运算
四、相关性运算相关性常用来衡量两个事物之间的相关程度,比如我们前面举的例子:啤酒与尿布二者的相关性很强。我们一般用相关系数来衡量两者的相关程度,所以相关性计算其实就是计算相关系数,比较常用的是皮尔逊相关系数。
在Excel中求取相关系数用的是correl()函数,示例如下:

在Python中求取相关系数用的是corr()函数,示例如下:

还可以利用 corr()函数求取整个 DataFrame 表中各字段两两之间的相关性,示例如下:


 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏

 [em23][em23]
[em23][em23]




