
作者 | Jason Brownlee
编译 | CDA数据分析师
特征选择是识别和选择与目标变量最相关的输入特征子集的过程。
使用实值数据(例如使用Pearson的相关系数)时,特征选择通常很简单,但是使用分类数据时可能会遇到挑战。
当目标变量也是分类的(例如分类预测建模)时,分类输入数据的两种最常用的特征选择方法是卡方统计和互信息统计。
在本教程中,您将发现如何使用分类输入数据执行特征选择。
完成本教程后,您将知道:
- 具有分类输入和二元分类目标变量的乳腺癌预测建模问题。
- 如何使用卡方和互信息统计来评估分类特征的重要性。
- 在拟合和评估分类模型时,如何对分类数据执行特征选择。
教程概述本教程分为三个部分:他们是:
乳腺癌分类数据集作为本教程的基础,我们将使用自1980年代以来作为机器学习数据集而被广泛研究的所谓“ 乳腺癌 ”数据集。
该数据集将乳腺癌患者数据分类为癌症复发或无复发。有286个示例和9个输入变量。这是一个二进制分类问题。
天真的模型可以在此数据集上达到70%的精度。好的分数大约是76%+/- 3%。我们将针对该区域,但是请注意,本教程中的模型并未进行优化。它们旨在演示编码方案。
您可以下载数据集,然后将文件另存为“ breast-cancer.csv ”在当前工作目录中。
- 乳腺癌数据集(breast-cancer.csv)
查看数据,我们可以看到所有九个输入变量都是分类的。
具体来说,所有变量都用引号引起来;有些是序数,有些不是。
我们可以使用Pandas库将该数据集加载到内存中。
加载后,我们可以将列分为输入(X)和输出以进行建模。
最后,我们可以将输入数据中的所有字段都强制为字符串,以防万一熊猫试图将某些字段自动映射为数字(确实如此)。
我们可以将所有这些结合到一个有用的功能中,以备后用。
加载后,我们可以将数据分为训练集和测试集,以便我们可以拟合和评估学习模型。
我们将使用scikit-learn形式的traintestsplit()函数,并将67%的数据用于训练,将33%的数据用于测试。
将所有这些元素结合在一起,下面列出了加载,拆分和汇总原始分类数据集的完整示例。
运行示例将报告训练和测试集的输入和输出元素的大小。
我们可以看到,我们有191个示例用于培训,而95个用于测试。
既然我们已经熟悉了数据集,那么让我们看一下如何对它进行编码以进行建模。
我们可以使用scikit-learn的OrdinalEncoder()将每个变量编码为整数。这是一个灵活的类,并且允许将类别的顺序指定为参数(如果已知这样的顺序)。
注意:我将作为练习来更新以下示例,以尝试为具有自然顺序的变量指定顺序,并查看其是否对模型性能产生影响。
对变量进行编码的最佳实践是使编码适合训练数据集,然后将其应用于训练和测试数据集。
下面名为prepare_inputs()的函数获取火车和测试集的输入数据,并使用序数编码对其进行编码。
我们还需要准备目标变量。
这是一个二进制分类问题,因此我们需要将两个类标签映射到0和1。这是一种序数编码,而scikit-learn提供了专门为此目的设计的LabelEncoder类。尽管LabelEncoder设计用于编码单个变量,但我们可以轻松使用OrdinalEncoder并获得相同的结果。
所述prepare_targets()函数整数编码的训练集和测试集的输出数据。
我们可以调用这些函数来准备我们的数据。
综上所述,下面列出了加载和编码乳腺癌分类数据集的输入和输出变量的完整示例。
现在我们已经加载并准备了乳腺癌数据集,我们可以探索特征选择。
分类特征选择有两种流行的特征选择技术,可用于分类输入数据和分类(类)目标变量。
他们是:
让我们依次仔细研究每个对象。
卡方特征选择皮尔逊的卡方统计假设检验是分类变量之间独立性检验的一个示例。
您可以在教程中了解有关此统计测试的更多信息:
该测试的结果可用于特征选择,其中可以从数据集中删除与目标变量无关的那些特征。
scikit-learn机器库在chi2()函数中提供了卡方检验的实现。此功能可用于特征选择策略中,例如通过SelectKBest类选择前k个最相关的特征(最大值)。
例如,我们可以定义SelectKBest类以使用chi2 ()函数并选择所有功能,然后转换训练序列和测试集。
然后,我们可以打印每个变量的分数(越大越好),并将每个变量的分数绘制为条形图,以了解应该选择多少个特征。
将其与上一节中乳腺癌数据集的数据准备结合在一起,下面列出了完整的示例。

首先运行示例将打印为每个输入要素和目标变量计算的分数。
注意:您的具体结果可能会有所不同。尝试运行该示例几次。
在这种情况下,我们可以看到分数很小,仅凭数字很难知道哪个功能更相关。
也许功能3、4、5和8最相关。
创建每个输入要素的要素重要性得分的条形图。
这清楚地表明,特征3可能是最相关的(根据卡方),并且九个输入特征中的四个也许是最相关的。
在配置SelectKBest来选择这前四个功能时,我们可以设置k = 4 。
输入要素的条形图(x)vs Chi-Squared要素重要性(y)
互信息特征选择来自信息理论领域的互信息是信息增益(通常用于决策树的构建)在特征选择中的应用。
在两个变量之间计算互信息,并在给定另一个变量的已知值的情况下测量一个变量的不确定性降低。
您可以在以下教程中了解有关相互信息的更多信息。
scikit-learn机器学习库通过commoninfoclassif()函数提供了用于信息选择的互信息实现。
像chi2()一样,它可以用于SelectKBest特征选择策略(和其他策略)中。
我们可以使用关于乳腺癌组的相互信息来进行特征选择,并像上一节中那样打印和绘制分数(越大越好)。
下面列出了使用互信息进行分类特征选择的完整示例。
首先运行示例将打印为每个输入要素和目标变量计算的分数。
注意:您的具体结果可能会有所不同。尝试运行该示例几次。
在这种情况下,我们可以看到某些功能的得分很低,表明也许可以将其删除。
也许功能3、6、2和5最相关。
创建每个输入要素的要素重要性得分的条形图。
重要的是,促进了特征的不同混合。
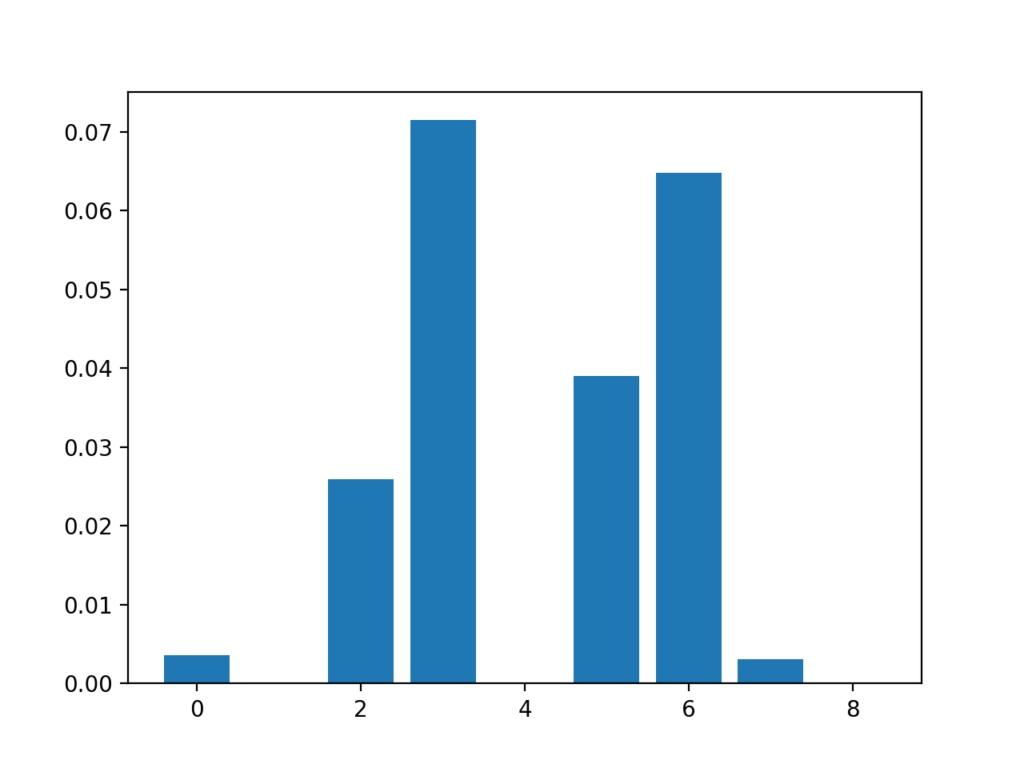
输入要素的条形图(x)vs互信息特征的重要性(y)
既然我们知道如何针对分类预测建模问题对分类数据执行特征选择,那么我们可以尝试使用选定的特征开发模型并比较结果。
使用选定特征建模有许多不同的技术可用来对特征评分和根据分数选择特征。您怎么知道要使用哪个?
一种可靠的方法是使用不同的特征选择方法(和特征数量)评估模型,然后选择能够产生最佳性能的模型的方法。
在本节中,我们将评估具有所有要素的Logistic回归模型,并将其与通过卡方选择的要素和通过互信息选择的要素构建的模型进行比较。
逻辑回归是测试特征选择方法的良好模型,因为如果从模型中删除了不相关的特征,则逻辑回归性能会更好。
使用所有功能构建的模型第一步,我们将使用所有可用功能评估LogisticRegression模型。
该模型适合训练数据集,并在测试数据集上进行评估。
下面列出了完整的示例。
运行示例将在训练数据集上打印模型的准确性。
注意:根据学习算法的随机性,您的特定结果可能会有所不同。尝试运行该示例几次。
在这种情况下,我们可以看到该模型实现了约75%的分类精度。
我们宁愿使用能够实现比此更好或更高的分类精度的功能子集。
Accuracy: 75.79

使用卡方特征构建的模型我们可以使用卡方检验对特征进行评分并选择四个最相关的特征。
下面的select_features()函数已更新以实现此目的。
下面列出了使用这种特征选择方法评估逻辑回归模型拟合和对数据进行评估的完整示例。
运行示例将报告使用卡方统计量选择的九个输入要素中只有四个要素的模型性能。
注意:根据学习算法的随机性,您的特定结果可能会有所不同。尝试运行该示例几次。
在这种情况下,我们看到该模型的准确度约为74%,性能略有下降。
实际上,某些已删除的功能可能会直接增加价值,或者与所选功能一致。
在这个阶段,我们可能更喜欢使用所有输入功能。
Accuracy: 74.74
使用互信息功能构建的模型我们可以重复实验,并使用相互信息统计量选择前四个功能。
下面列出了实现此目的的select_features()函数的更新版本。
下面列出了使用互信息进行特征选择以拟合逻辑回归模型的完整示例。
运行示例使模型适合于使用互信息选择的前四个精选功能。
注意:根据学习算法的随机性,您的特定结果可能会有所不同。尝试运行该示例几次。
在这种情况下,我们可以看到分类精度小幅提升至76%。
为了确保效果是真实的,最好将每个实验重复多次并比较平均效果。探索使用k倍交叉验证而不是简单的训练/测试拆分也是一个好主意。
阅读更多精彩信息:
2020年聊天机器人将走向何方?-AIU人工...数据科学
AI人工智能是职业杀手还是工作创造者?人工智能
老码农的「锦囊」:10个编程技巧、5个纠错步...数据科学
大批金融从业者会在未来10年被AI取代?!转...数据科学
当谈论机器学习中的公平公正时,我们该谈论些什...机器学习
管轶团队重磅研究:走私穿山甲中发现冠状病毒,...数据科学
Excel狂魔?单元格做计算机视觉:人脸检测...数据科学
2020年,图机器学习将走向何方?机器学习
疫情之下,这是你也能上手的Python新冠病...数据科学
最大规模新冠临床研究:近9000个病例,男性...数据科学
机器学习背后,你不能不知道的数学核心概念数据科学
一个喷嚏就能传播病毒?关于病毒,还有多少是你...数据科学
破冰方案!焦虑有啥用?VIP会员2020,全...数据科学
什么是预测分析,其应用行业都有哪些?数据科学
5G时代下,AI人工智能扮演何种关键角色?人工智能
如何用python在工作中“偷懒”?人工智能
一文讲解机器学习算法中的共线性问题机器学习
数据科学家的高级进修:学会如何“讲故事”数据科学
数据分析实践入门(一):数据预处理数据科学
数据分析师的核心竞争力在哪里?数据科学


 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏





