◎ 常见问题Q:什么时候可以参加比赛?是否接受邮件报名? A:本届竞赛的注册截止时间是2011年4月15日。在这之前,你都可以通过在线注册来获取建模数据集,并提交你的作品。注册后,你可以在4月27日比赛结束前,一直参加我们的比赛,并随时在线提交及测试你的模型效果。本届竞赛不接受邮件报名,所有报名工作请在竞赛网页上完成。
Q:本届比赛的参赛对象是谁? A:本届竞赛面向国内所有高校和科研院所的在校本科生、硕士生和博士生。但评比时会进行分组。这主要是从公平性角度考虑的。
Q:本科生可以与研究生混合组队么? A:原则上是允许的。但为了公平起见,含有至少一位非本科生的队伍,在比赛中将被划分到非研究生组中进行排名和评比。
Q:如何获取建模数据集?我可以把数据集传给别人么? A:本数据集仅能用于本次竞赛的分析、建模用途,且限于在线注册用户使用。不得用于任何其他商业用途。用于学术研究和论文发表目的的,请与上海花千树信息科技有限公司联系并获取授权。竞赛委员会不具有授权权力。
Q:如何获知赛题的相关变动? A:你可以随时登录竞赛页面进行查看。对于特别重要的变动,我们会在第一时间在本网站上发布,并通过下述两种方式通知大家。
新浪微博:
http://t.sina.com.cn/cosname
COS论坛:
http://cos.name/cn
Q:比赛期间遇到问题(如数据错误等),应该与谁联系解决? A:比赛期间的任何问题请与
dataminingcompetition@gmail.com联系。但一般的数据错误等问题,只要是不影响建模的,请自行解决。
Q:为什么我的提问没有得到反馈? A:出现这种情况时,请先确认你的问题是否可以通过仔细阅读本FAQ解决。否则请考虑你的问题是否真的会影响建模工作。如果并非这两种原因,请尝试再给我们发信询问。
Q:为什么要限制每个参赛队每天提交测试的数量? A:我们提供的训练数据集足够大,你完全可以在训练数据集中预留一部分用于算法的早期测试。当这样的测试表明你的模型性能足够良好时,再将模型结果提交到服务器上。这并不会影响你的建模工作,反而会保证每次提交的结果有改进的倾向。这样做的好处还在于,在比赛结束前,从十多个历史提交记录中挑选出一个最终模型预测文件变得更加容易(假设你不希望从几十个文件中进行挑选)。当然,这样做也会减轻服务器的负担。
Q:为什么限制每个参赛队的队员数量? A:责任分散(Diffusion of responsibility)是一种广泛存在的社会现象,类似的情况还包括旁观者效应(Bystander effect)和社会惰化(Social loafing)。竞赛委员会认为不超过4个人的团队足以应付本次竞赛的挑战。
Q:比赛期间是否允许在各种论坛上讨论题目? A:我们建议你与自己的队员进行探讨和尝试。
Q:为什么要填写真实的注册信息? A:比赛过程中常常会出现某些意外的情况,如数据集中的致命错误等,这会影响你的模型。另外,一些新的通知发布时,如公布答辩名单、时间和地点时,我们可能需要与你联系。
Q:什么时候公布最终的答辩名单、时间和地点? A:请等待后续通知。
Q:为什么要设置验证数据集(Validation)和测试数据集(Test)? A:这是出于防止模型过度拟合(overfitting)、更真实地反映模型推广能力的考虑。由于在比赛期间,你可以多次提交预测结果,并能实时获得模型效果的反馈。如果仅仅设置一个Test集,那么在多次提交后,你的模型(及其调整后的模型)就倾向于在这个特定的Test数据集上表现良好,而在更大的数据集合上则可能表现出一般的性能。为了避免这一风险,竞赛委员会从整个Test集中,随机挑选了40%的数据构成Validation集,你在提交测试的时候,获得的反馈即能在一定程度上能反映出模型质量,也能保证最终基于整个Test集计算得到的排名能真实地反映各参赛队算法的差异。更多关于过度拟合的信息请参考:
http://en.wikipedia.org/wiki/Overfitting。
Q:为什么要从历史提交记录中挑选一个最终的预测文件进行提交? A:如前所述,过度拟合现象的危害十分明显。在Validation集上表现良好的预测,未必就能保证应用到整个Test集上时,仍能让你占据排行榜的前列。反之亦然。因此你需要根据自己建模时的心得,自己挑选一个最终的预测。
Q:为什么选择NDCG作为评价标准? A:NDCG在Learning to Rank问题中被广为采用。与经常用来比较两个序之间的相关程度的肯德尔和谐系数相比,NDCG的不同之处在于,它更强调和关注两个序中排名靠前的部分的相关程度。这与我们的实际需求相符,因为我们更希望将与会员A有可能发生msg行为的候选会员排名靠前。
Q:能否提供一些参考资料? A:推荐系统在最近几年陆续受到工业界和学术界的关注。Netflix公司曾发起过一个奖金高达100万美元的
竞赛,目的是寻找能将Netflix公司原有模型的性能提供10%的新的推荐算法。获奖者的部分算法能在
这里找到。在现有的诸多算法中,
协同过滤算法的基本思想常常处于基础重要的地位。与推荐系统相关的有趣信息还可以参考
ReSysChina。需要强调的是,许多推荐算法都是针对用户—商品之间的推荐来设计的,如
Amazon和
豆瓣。本次竞赛的问题涉及的是用户—用户之间的推荐,也许需要新的思路来获取更好的模型。另外,基本但有效的统计模型(或机器学习算法)的相关知识,可以通过许多教材来获取,如C. M. Bishop的Pattern Recognition and Machine Learning(PRML)。关于推荐系统的一本及其浅显的小书可参考Programming Collective Intelligence: Building Smart Web 2.0 Application。
Q:是否可以定义新变量? A:可以根据提供的数据任意构造新的变量。但参加答辩的队伍需要在最终的论文中详细说明构造方法
Q:提交时间是否影响最终的排名 A:不影响。本次竞赛的排名主要参考预测结果在Test集中所有USER_ID_A上的平均NDCG值。在出现胶着状态时,会由竞赛委员会在答辩时酌情考虑算法复杂度、可解释性以及部署成本等因素来给出最终排名。


 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏


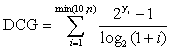 。
。



