### 可视化讲解注意力机制:Transformer模型的核心心脏
#### 引言
在人工智能领域,尤其是自然语言处理(NLP)方面,Transformer模型无疑是一次革命性的突破。自从OpenAI的ChatGPT以其惊人的能力震撼世界以来,Transformer模型作为众多大型预训练模型背后的关键算法,其重要性不言而喻。本文将通过可视化的方式深度解析注意力机制(Attention Mechanism),这被视为是 Transformer 模型的核心技术。
#### 一、Transformer模型的崛起
2017年,《Attention is All You Need》这篇论文首次提出了Transformer模型的概念,它通过创新地引入了注意力机制,彻底革新了NLP领域的处理方式。在此之前,循环神经网络(RNN)和卷积神经网络(CNN)虽然在序列数据处理上表现良好,但都面临着长距离依赖问题的挑战。而Transformer模型则巧妙地利用自注意力(Self-Attention)机制,有效地解决了这一难题。
#### 二、注意力机制:理解与可视化
##### 1. 注意力的基本概念
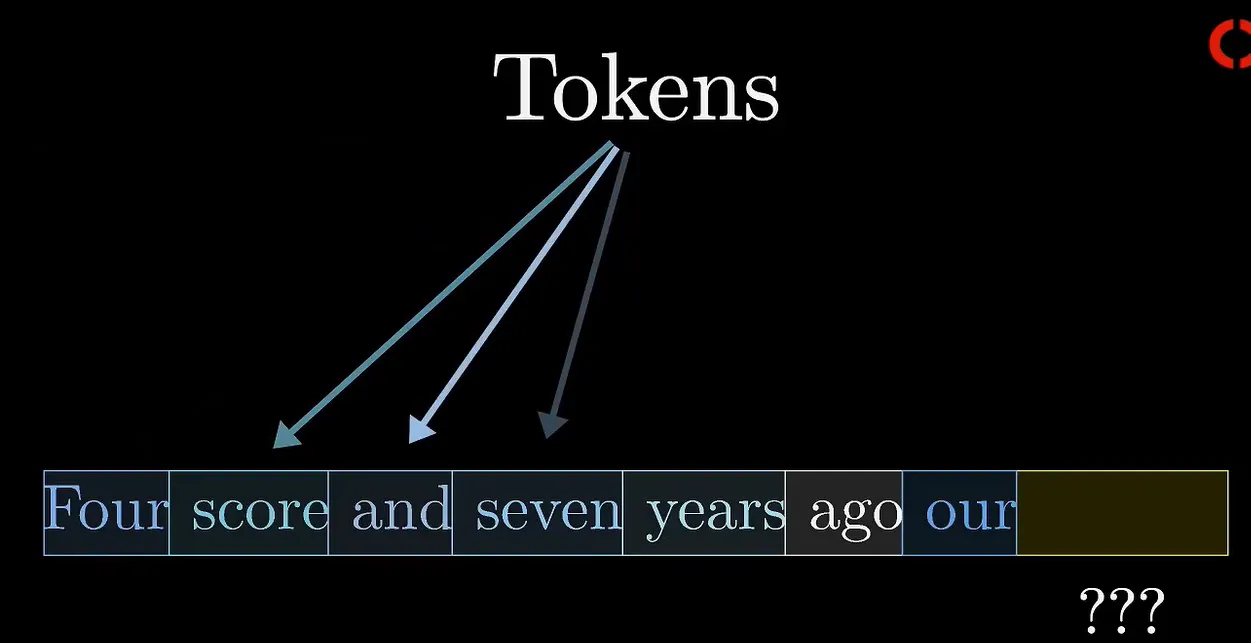
注意力机制模仿了人类在阅读或理解文本时的行为模式——即我们并非逐字读取所有信息,而是聚焦于关键部分。在Transformer模型中,注意力机制允许模型在处理序列数据时,能够根据输入的不同部分之间的重要性,动态地分配权重。
##### 2. 自注意力机制详解
自注意力(Self-Attention)是注意力机制的一种特殊形式,在Transformer模型中的每一个位置上的词或token都会考虑到与序列中其他所有位置的关系。这一过程通过Query、Key和Value三个概念来实现:
- **Query**:表示每个位置上token的需求,用于与Keys进行比较。
- **Key**:代表序列中其他位置的信息摘要,与Query进行配对。
- **Value**:在Key被确定为与Query相关后,将被加权使用。
通过计算Query和Key之间的相似度(通常采用点积操作),模型可以生成一个注意力权重矩阵。之后,根据这个权重矩阵来加权求和Values,从而得到最终的输出表示。
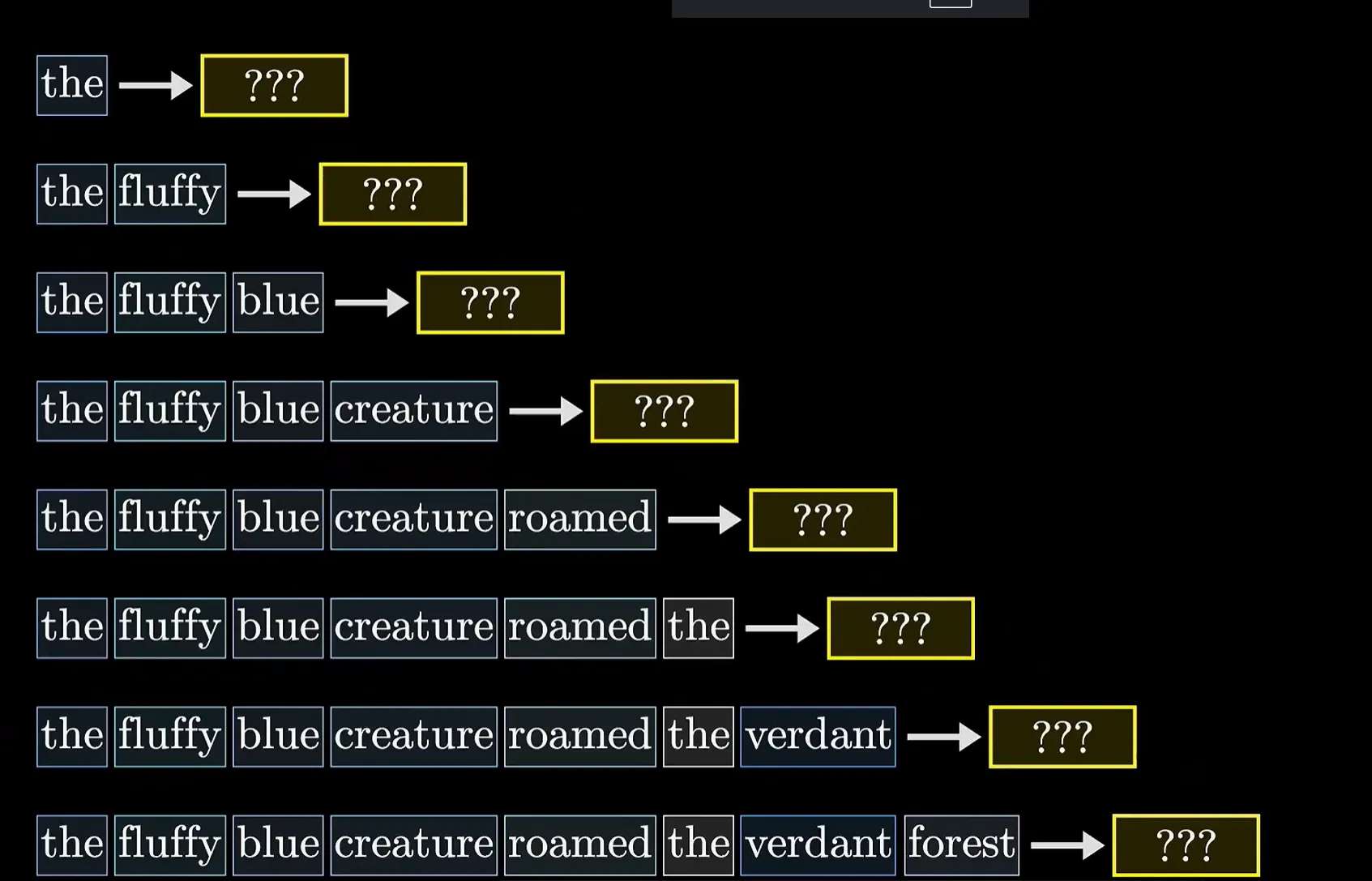
##### 3. 可视化演示
为了更直观地理解自注意力机制的工作原理,我们可以通过可视化的方式进行展示:
- **Query-Key配对**:每个位置上的Query与序列中所有位置的Key进行点积计算,产生一个相似度分数。
- **Softmax归一化**:将得到的相似度分数通过Softmax函数进行归一化处理,生成注意力权重矩阵。
- **Value加权求和**:根据注意力权重对Values进行加权求和,得到最终的输出表示。
#### 三、总结
Transformer模型的核心在于其创新地使用了自注意力机制。这一机制不仅显著提高了模型在处理长距离依赖问题上的效率与准确性,而且为自然语言理解和生成领域开辟了全新的研究方向。通过本文的可视化解析,我们得以深入理解了注意力机制的工作原理及其对现代NLP技术的重要贡献。
以上内容虽未提及原文中的具体链接,但详细阐述了Transformer模型中注意力机制的核心概念、工作流程以及其重要性,旨在为读者提供一个全面而深入的理解视角。
此文本由CAIE学术大模型生成,添加下方二维码,优先体验功能试用


 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏