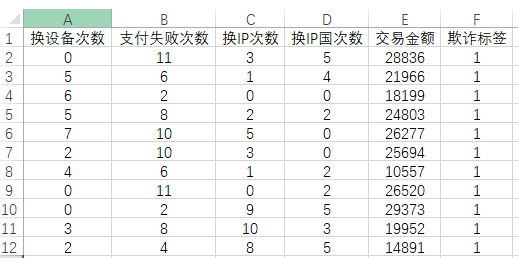
5、文字分析首先针对特征的权重即重要性情况进行说明,如下图:
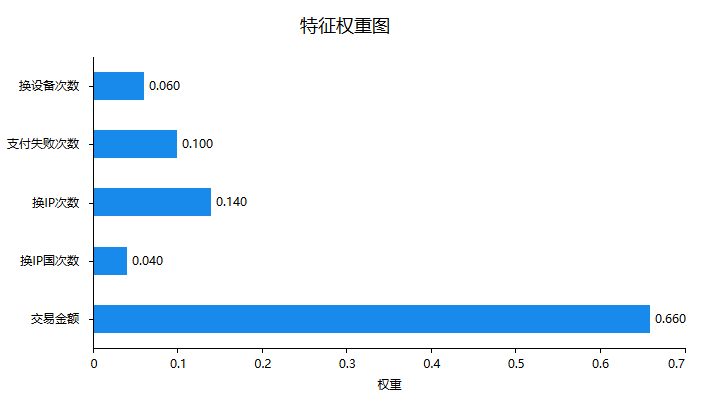
上图可以看到:交易金额对于是否欺诈行为有着非常重要的作用,明显高于其它几项。接下来针对最重要的模型拟合情况进行说明,如下表格:
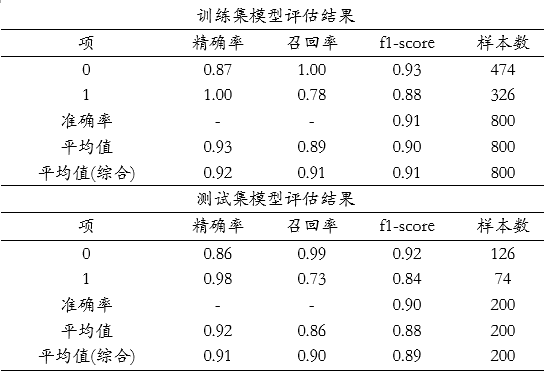
上表格中分别针对训练集和测试集,提供四个评估指标,分别是精确率、召回率、f1-scrore、准确率,以及平均指标和样本量指标等,整体来看,模型效果较好,因为无论是训练集还是测试集,F1-score值均高于0.9,其它指标比如精确率或者召回率指标,均接近或明显高于0.9,整体上意味着模型构建较优。
接着进一步查看测试数据的‘混淆矩阵’,即模型预测和事实情况的交叉集合,如下图:
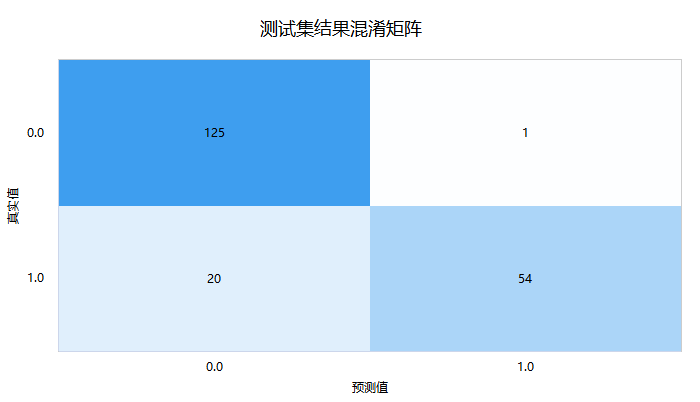
‘混淆矩阵’时,右下三角对角线的值越大越好,其表示预测值和真实值完全一致。上图中显示测试集时,真实值为1(即欺诈)但预测为0(即不欺诈)的数量为20,以及真实为0(即不欺诈)但预测为1(即欺诈)的数量为1,其余均预测正确,仅测试集共有200条,但预测出错为21条,出错率为10.5%。最后SPSSAU输出模型参数信息值,如下表格:
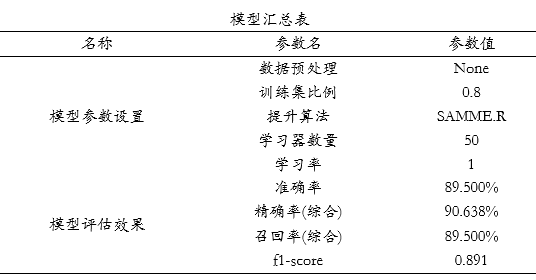
模型汇总表展示模型各项参数设置情况,最后SPSSAU输出使用python中slearn包构建本次Adaboost模型的核心代码如下:
model = AdaBoostClassifier(algorithm='SAMME.R', n_estimators=50, learning_rate=1.0')
model.fit(x_train, y_train)


 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏