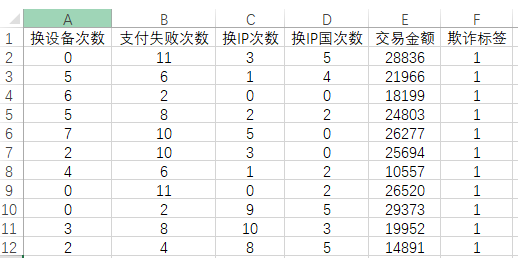
5、文字分析接下来针对最重要的模型拟合情况进行说明,如下表格:
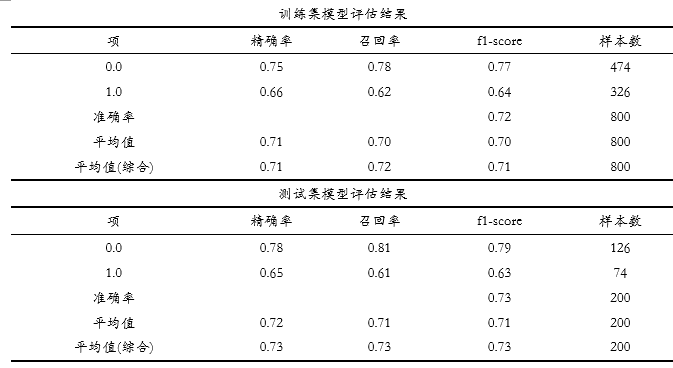
上表格中分别针对训练集和测试集,提供四个评估指标,分别是精确率、召回率、f1-scrore、准确率,以及平均指标和样本量指标等,整体来看,模型效果较差,因为无论是训练集还是测试集,F1-score值均约高于0.7而已,其它指标比如精确率或者召回率指标,均低于0.8。
接着进一步查看测试数据的‘混淆矩阵’,即模型预测和事实情况的交叉集合,如下图:

‘混淆矩阵’时,右下三角对角线的值越大越好,其表示预测值和真实值完全一致。上图中显示测试集时,真实值为1(即欺诈)但预测为0(即不欺诈)的数量为29,还有24个真实值为0但预测为1,整体预测准确率较低。最后SPSSAU输出模型参数信息值,如下表格:

模型汇总表展示模型各项参数设置情况,最后SPSSAU输出使用python中slearn包构建本次神经网络的核心代码如下:
model = LogisticRegression(solver='lbfgs', penalty='l2', fit_intercept=True, max_iter=100, tol=0.001)
model.fit(x_train, y_train)
与此同时, 本次logistic回归为二分类问题,SPSSAU默认输入AUC指标和ROC曲线,如下。AUC指标时,训练集和测试集分别是0.769和0.781,相对尚可。
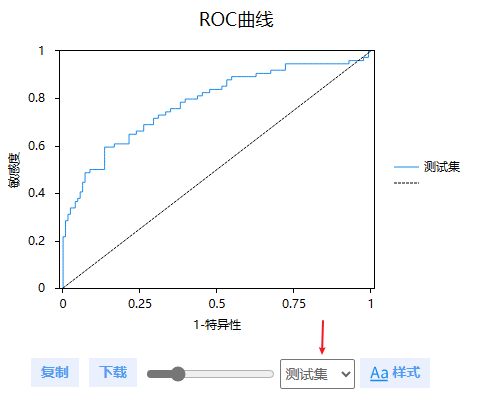
ROC曲线时,可切换测试集或者训练集,查看对应的ROC曲线。需要注意的是,如果非二分类(即Y的不同数字个数大于2时),此时不会输出AUC指标或ROC曲线。研究者可自行结合保存预测值进行构造ROC曲线等。


 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏