融合因果机制的RAG 探索:赋能LLM推理深度与一致性【创新洞察日报--专刊】 推荐理由 在2025年国际数学奥林匹克(IMO)上,OpenAI与DeepMind的语言模型首次以自然语言形式完成高难度数学证明,获得金牌级成绩。这一突破不仅彰显了LLM在严谨逻辑推理上的潜力,也凸显了因果一致性在复杂任务中的核心价值。与此同时,融合因果关系的检索增强生成技术正成为LLM研究的关键方向。传统RAG方法因缺乏因果建模,难以满足医学问答、多跳推理与语境敏感生成等任务的逻辑需求。融合因果关系的检索增强生成技术通过因果图构建、链式推理与因果验证机制,有效提升了生成内容的准确性与解释性。本专刊系统调研了该领域多个代表性成果,展现因果RAG技术在提升LLM推理质量中的广泛适用性与研究热度。
作者:王晶、刘家祺、肖震、吴瑾
更多精彩创新观点,欢迎进入【创新洞察日报】栏目:
https://www.chaspark.com/#/s/chuangxindongcha
正文
凯斯西储大学提出CausalRAG,在知识密集型检索增强生成任务中实现更高精度与更强因果一致性
伊利诺伊大学香槟分校团队提出CC-RAG,在金融与医疗专业领域实现结构化多跳因果推理,显著提升LLM生成结果的准确性与解释性
加州大学欧文分校提出 CDF-RAG 框架,在复杂问答任务中实现因果一致性与高准确率的生成式推理突破
美国伊利诺伊大学芝加哥分校等机构提出文献驱动的RAG技术,用于加速阿尔茨海默病生物标志物因果网络发现,提升疾病诊断与治疗精准性
英国华威大学与中国浙江大学合作提出因果优先图神经推理框架,在医学问答应用场景下实现诊断准确率提升10%的突破性成果
北京大学与腾讯微信AI联合提出CRAT多智能体框架,在处理语境敏感术语的英汉翻译任务中实现BLEU提升3.1点、CONSIS提升3.3点的显著成效
新加坡国立大学与阿里巴巴集团联合提出E²RAG双图框架,在叙事文档的检索增强生成任务中显著提升因果一致性与角色一致性理解能力
1.凯斯西储大学提出CausalRAG,在知识密集型检索增强生成任务中实现更高精度与更强因果一致性 摘要: 凯斯西储大学计算与数据科学系的Ma Jing教授团队联合创新设计了CausalRAG框架,将因果图模型引入传统检索增强生成(RAG)系统,以显著改善响应的准确性与解释性。传统RAG方法受限于文本分块引发的上下文破裂,以及仅依赖语义相似度导致检索精度不足。该研究通过构建因果关系图,在检索过程中追踪文本中的因果路径,使模型能够生成因果一致、信息精确的回答。相比于常规RAG与基于图结构的GraphRAG,CausalRAG在多个性能指标上表现出显著优势,尤其在上下文精度方面达到了92.86%的最高值。该框架在长文本处理和复杂问答任务中也保持稳定性能,实验覆盖21,285个token的文献数据,涵盖生命科学、物理、社会科学等多个学科领域,验证了该方法在真实知识密集型场景中的广泛适用性。作者使用Ragas评估框架从回答忠实性、上下文召回率与上下文精度三个角度量化性能,结果显示CausalRAG分别取得78.00%、49.46%和92.86%的得分,在保持召回的同时显著提升了回答质量并降低了“幻觉”现象,为RAG系统的因果性集成提供了有效方法。
核心观点:
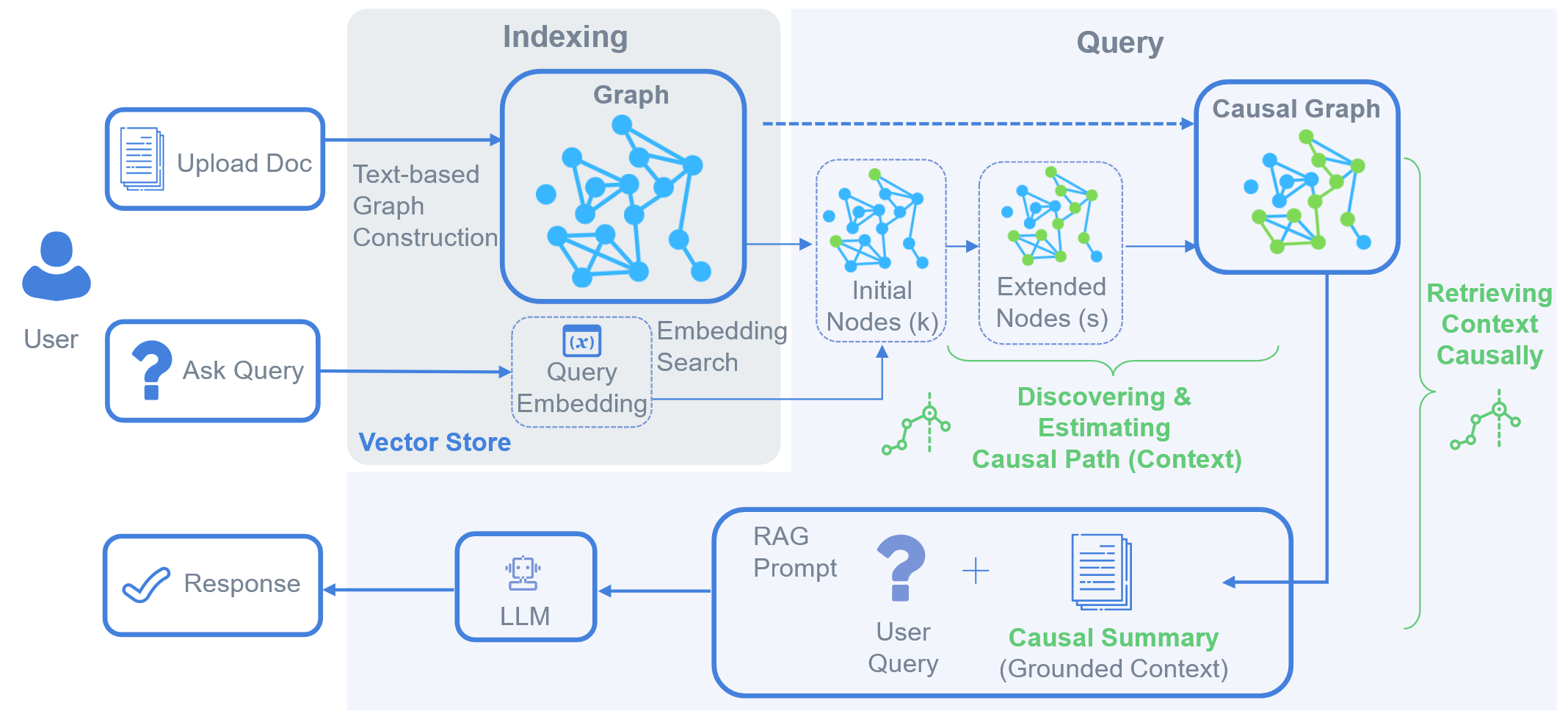
构建文本因果图实现因果一致性检索:CausalRAG通过采用LLM辅助的文本解析方法将非结构化文档构建为因果图结构。该方法将文本中的关键概念抽象为节点,并识别其因果关系作为图中的边,从而形成支持因果推理的知识表示体系。在查询阶段,系统基于用户查询embedding匹配初始节点,并沿因果路径扩展检索范围,有效维持上下文的因果连贯性。这一方法突破了常规语义搜索无法识别隐藏因果机制的瓶颈,使模型更加契合用户的深层次信息需求。
提出上下文“召回-精度”双指标评估法,揭示传统RAG缺陷:作者提出一种基于上下文召回率与精度的新评估视角,通过分析文档检索与生成过程中的信息关联性,系统性揭示了传统RAG面临的三大问题:上下文断裂、语义检索引入偏差、响应片面。实验结果显示,普通RAG系统虽然在召回方面表现较好(46.06%),但精度严重不足(47.34%);而GraphRAG虽提升了精度(66.67%),却牺牲了召回(40.65%)。相比之下,CausalRAG在精度上取得最高成绩(92.86%),同时保持较高回答忠实度(78.00%),展现了因果检索机制在应对知识密集型任务中的优越性。
在多学科与长文档场景中验证CausalRAG稳健性:研究进一步通过三种版本(摘要、引言、全文)对同一文献进行对比实验,CausalRAG在16,000-token长文档处理下仍取得91.69的综合得分,较GraphRAG-Global(76.37)与Regular RAG(74.72)更为优异,展现了因果扩展机制在多尺度文档下的强健性能。此外,该方法在生命科学、物理、社会科学等领域均保持稳定表现,表明其具备跨领域通用性与真实场景适应能力。参数研究也证实,随着因果扩展参数(k与s)增加,系统平均性能从0.534提升至0.824,为未来构建动态检索策略提供理论依据。
CausalRAG的架构图
信息来源:
ACL findings, 2025 https://arxiv.org/pdf/2503.19878
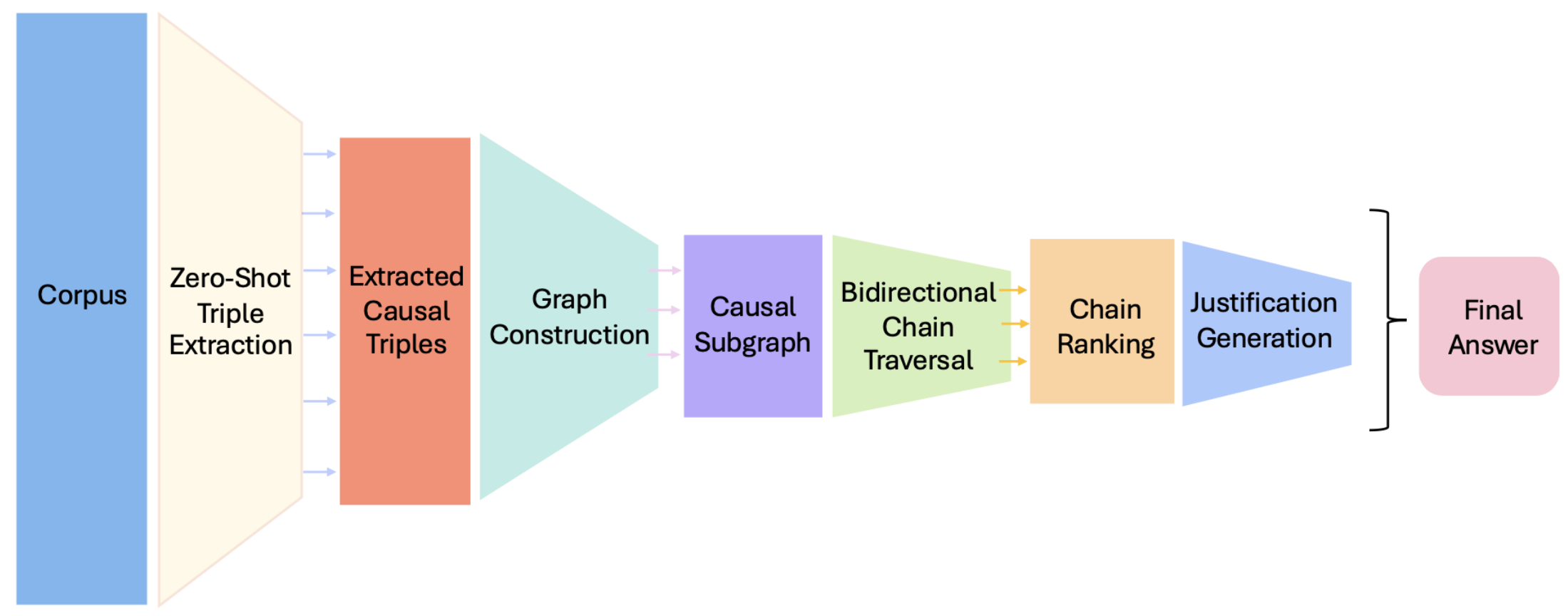
2.伊利诺伊大学香槟分校团队提出CC-RAG,在金融与医疗专业领域实现结构化多跳因果推理,显著提升LLM生成结果的准确性与解释性 摘要: 在金融和医疗等专业领域,LLM在理解多跳因果关系方面存在挑战。传统的RAG方法仅使用文本片段,缺乏结构建模能力。伊利诺伊大学香槟分校的研究团队提出CC-RAG方法,通过零样本抽取(cause, relation, effect)三元组构建因果有向图,并采用链式推理强化LLM的生成过程。将因果关系结构化为主题相关的有向无环图(DAG),并结合查询意图实施前向或后向链式遍历,使模型能够沿结构化路径进行推理生成。这种基于图结构的推理机制显著提升了答案的准确性与解释性。在“比特币价格波动”与“戈谢病”任务中表现优异,BERTScore分别高达0.90和0.88,人类与LLM评估中均获优选结果。即使替换为轻量模型LLaMA,CC-RAG仍保持高准确性与解释力,展现出结构化推理的稳健性与通用性。
核心观点: 基于零样本LLM的因果三元组抽取与DAG构建机制:CC-RAG通过GPT-4o进行零样本抽取,将非结构化文本中的因果链转化为(cause, relation, effect)三元组。该过程不仅识别显式因果连接词(如“导致”、“引发”),还可推断隐性关系,实现更广泛因果语义覆盖。随后将这些三元组构建为无环有向图(DAG),为因果推理提供结构支持,补足ThemeKG未具备的因果建模与图遍历能力。
基于查询方向性的双向链式推理策略:系统可识别查询方向为前向(寻找结果)或后向(追溯原因),并以此进行链式图遍历。在推理过程中,采用KeyBERT进行关键词抽取,结合Sentence-BERT进行语义匹配,从图中选取语义相符节点,通过多跳推理生成因果路径。该技术突破了传统RAG单跳检索的限制,使生成结果具备因果链条的可追溯性与逻辑连贯性。
结构化链排名与自然语言解释融合机制:在多个备选因果链中,CC-RAG引入LLM对因果链进行动态语义评估与排名,选取与查询最匹配的路径。最终将推理结果结合链条结构生成自然语言响应,包含答案与推理过程解释。该机制强化了输出内容的解释性,避免模型生成无依据结论。同时在少样本评估及模型替换下,CC-RAG仍保持优异性能,说明其结构化推理机制具有良好的可扩展性与模型适配能力。
CC-RAG的架构图
信息来源:
https://arxiv.org/pdf/2506.08364
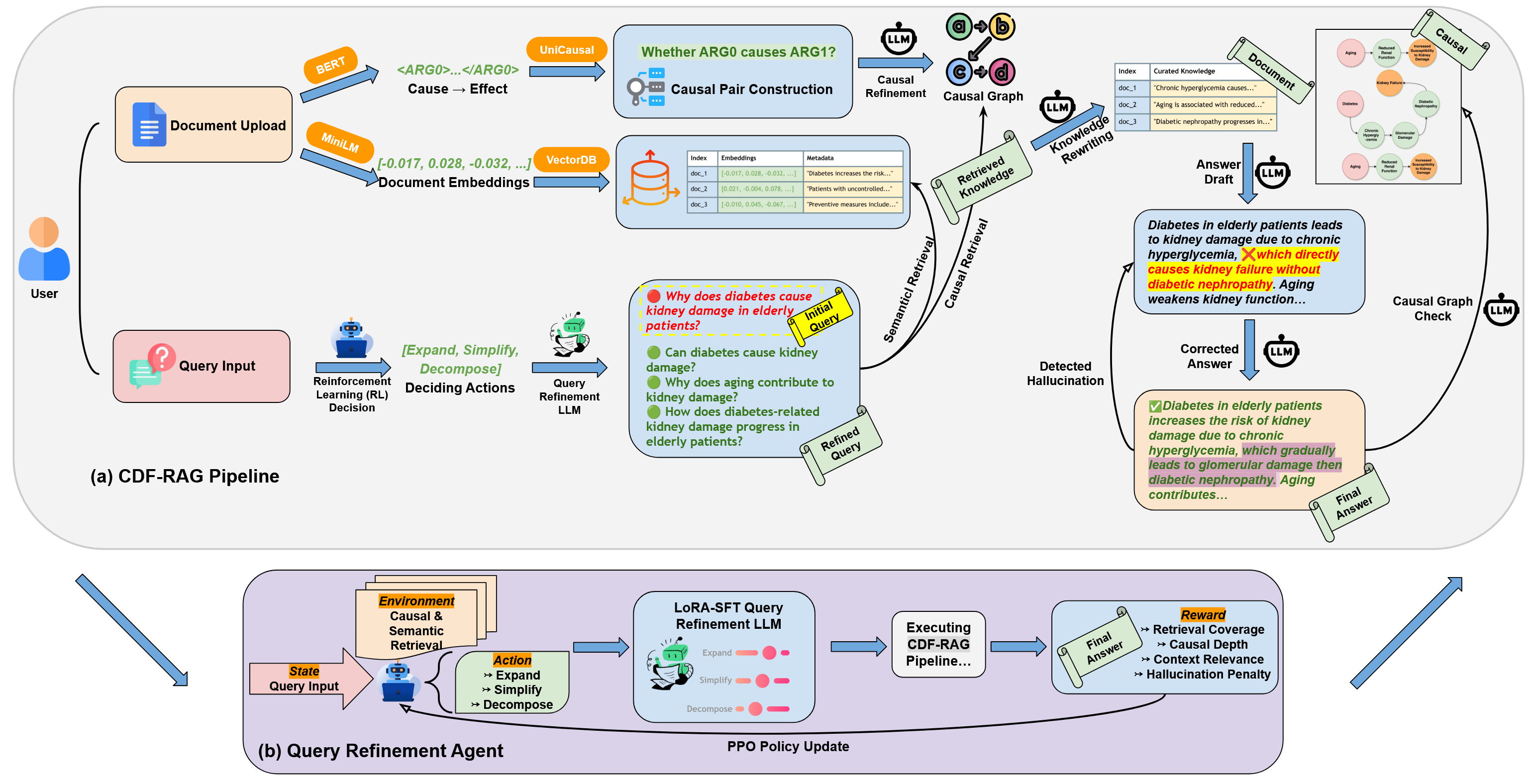
3.加州大学欧文分校提出 CDF-RAG 框架,在复杂问答任务中实现因果一致性与高准确率的生成式推理突破 摘要: 加州大学欧文分校的研究团队针对RAG(检索增强生成)方法在因果推理中存在的不足,提出了新框架 CDF-RAG(Causal Dynamic Feedback for Retrieval-Augmented Generation)。现有 RAG 方法主要依赖语义相似度检索,容易将相关性误判为因果性,导致生成结果表面合理但缺乏因果逻辑,尤其在医学等需要多跳因果推理的应用场景中存在信息误导和幻觉。为解决这一问题,CDF-RAG引入强化学习驱动的查询优化机制,自动对问题进行扩展、简化或分解,使其更具因果导向性。同时采用语义检索与因果图遍历相结合的双通道检索策略,并在生成后进行因果一致性校验与幻觉检测,确保生成内容与因果路径逻辑吻合。实验证明,该系统在 CosmosQA、MedQA、MedMCQA 和 AdversarialQA 四个复杂问答数据集上均实现性能突破,GPT-4模型在 MedMCQA 数据集上准确率达 94%,幻觉率低至 7%。整体提升因果一致性、答案准确性与解释性,为医学问答、知识推理等关键领域提供了更可靠的技术支撑。
核心观点: 强化学习驱动的因果查询重写技术突破传统RAG 的静态检索限制:CDF-RAG 引入基于强化学习的查询优化模块,将查询建模为马尔科夫决策过程,通过训练策略网络动态选择扩展、简化或分解操作。该机制优化后的查询提升了因果相关内容的检索覆盖度,并在多跳因果推理中展现出更强的结构表达能力。实验表明,该机制在MedQA数据集上可提高检索因果深度(CCD)从 1.50 至 1.70。
双通道检索策略融合语义与因果推理,实现结构化信息获取与语义匹配的平衡:CDF-RAG 采用语义向量搜索与因果图遍历相结合的检索方式,一方面通过 MiniLM 编码获取高语义相关文本,另一方面通过使用 UniCausal 工具构建的因果图谱进行图路径扩展,使得系统能同时捕获隐含因果机制与语境贴合内容。融合后的知识集合使生成模块具备更高的因果一致性,在 AdversarialQA 中 CRC 提升至 0.89,Context Relevance 提升至 0.76。
生成阶段引入因果验证与幻觉修正机制显著提升答案的事实一致性与可信: CDF-RAG 在生成答案后进行因果图一致性校验,若发现因果路径不匹配则触发严格约束下的重新生成。此外,系统会计算幻觉评分,对逻辑不一致回答进行知识改写纠错。该机制在 MedQA 中将幻觉率降低至 0.07,生成内容的 Groundedness 得分提升至 0.71。此闭环反馈设计确保每一阶段的因果一致性和事实真实性。
CDF-RAG的架构图
信息来源:
https://arxiv.org/pdf/2504.12560
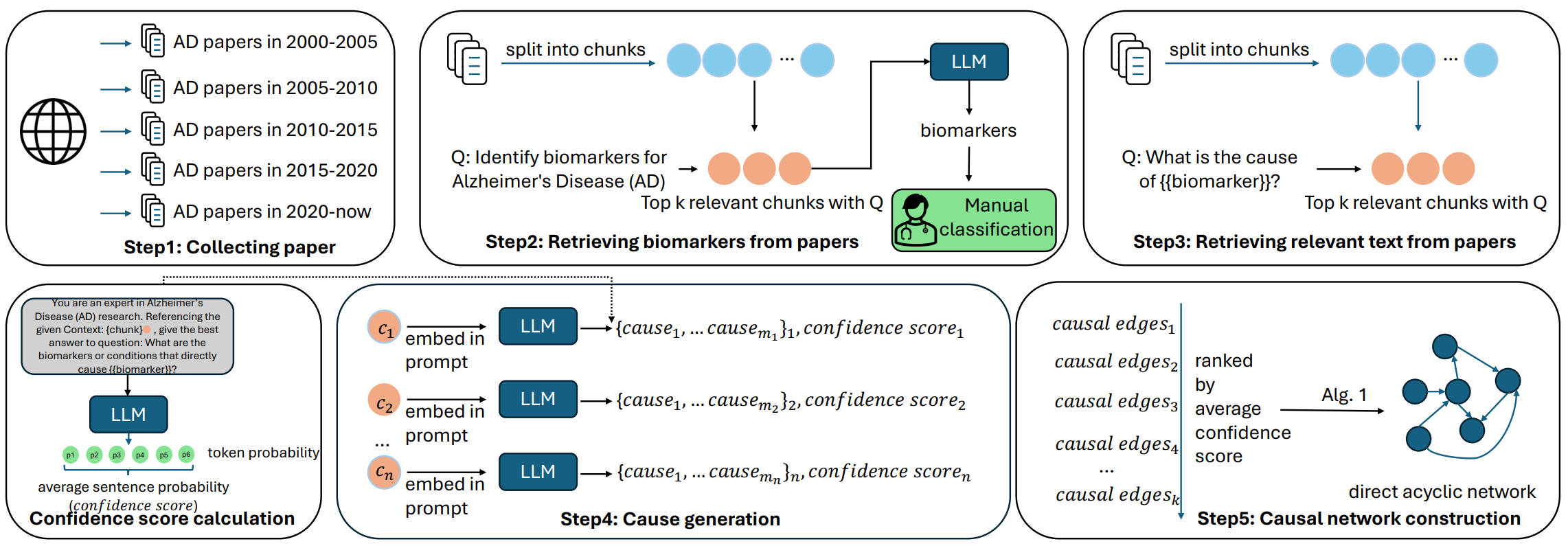
4.美国伊利诺伊大学芝加哥分校等机构提出文献驱动的RAG技术,用于加速阿尔茨海默病生物标志物因果网络发现,提升疾病诊断与治疗精准性 摘要: 美国伊利诺伊大学芝加哥分校和宾夕法尼亚州立大学联合研究团队提出一种基于科学文献的检索增强生成(RAG)框架,用于构建阿尔茨海默病(AD)生物标志物的因果关系网络,以支持早期诊断和治疗决策。研究汇总了过去25年间200篇高影响力AD相关文献,通过语义嵌入及文本检索提取关键生物标志物,并借助大语言模型完成因果关系推理。该框架引入不确定性估计机制,依据生成序列的平均token概率评估每条因果边的置信度,并以此构建有向无环图因果网络。对比分析表明,改进型split-RAG策略在小规模模型上表现优异。例如,在me ta-Llama-3-8B模型下,split-RAG取得了64.29%的准确率与46.14%的F1值,明显优于未使用文献检索的基础模型。此研究不仅证明文献驱动的RAG模型在因果发现中的有效性,也提供了可扩展、高信度的生物医学分析工具。
核心观点: 构建科学文献驱动的RAG框架,用于自动化抽取AD生物标志物及其因果关系:该模型以RAG框架为基础,将文献语义嵌入与命名实体识别技术相结合,高效提取阿尔茨海默病相关因果实体;通过链式思维机制和分块式判断策略,精确识别节点间因果关联并构建因果边。随后引入图排序与层级优化算法,在语义聚合与逻辑约束条件下自动生成结构清晰的有向无环图(DAG),并保留推理路径及文献支撑,实现因果知识图谱 的自动化建构与可解释性表达。
引入不确定性估计机制,提升因果推理可靠性与科学性:为确保生成图结构的可信性,模型引入基于平均token概率的不确定性量化机制,对因果边进行置信度打分,并据此筛选进入最终因果网络的边缘信息。该机制有效避免闭环结构的引入,增强了模型的自我校准能力与逻辑一致性,使得所构建的因果图不仅具备结构合理性,更在推理可靠性与应用安全性方面符合医学研究标准。
系统评估不同RAG策略及LLM规模的因果推理表现,为模型选择与参数设置提供指导依据:通过在me ta-Llama-3、Mixtral、Mistral等不同规模的大语言模型下比较base-LLM、concat-RAG与split-RAG三种策略,研究发现split-RAG在小模型中更具优势,而concat-RAG在大模型中有更好的性能平衡。此外,研究还分析了检索文本数量对性能的影响,确认低k值有助于提升准确率,而高k值在保持召回率方面更有优势。
方法框架
信息来源:
https://arxiv.org/pdf/2504.08768
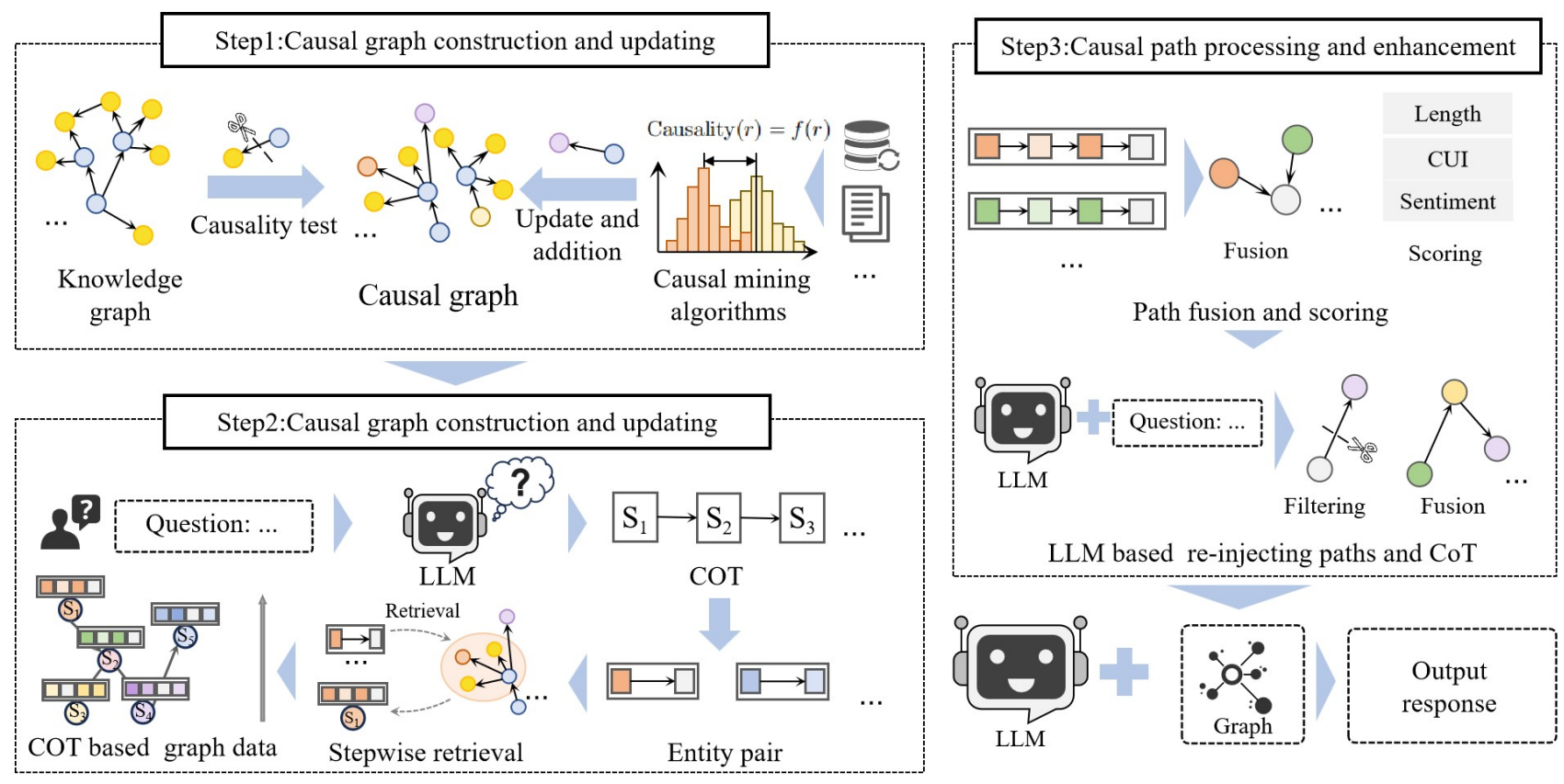
5.英国华威大学与中国浙江大学合作提出因果优先图神经推理框架,在医学问答应用场景下实现诊断准确率提升10%的突破性成果 摘要: 在知识密集型的推理任务中,尤其是医学与法律等高风险领域,对信息检索的准确性、因果推理能力及过程可解释性有着极高的要求。由英国华威大学与中国浙江大学共同开展的研究工作,针对大型语言模型(LLMs)在医学问答场景中存在的“知识注入困难”“推理过程不透明”“易产生幻觉”等问题,提出了一种全新的因果优先图增强生成框架(Causal-first Graph-RAG)。该技术创新性地从大规模知识图谱中筛选出具有因果关系的边构建子图,利用链式思维(Chain-of-Thought, CoT)引导图检索过程,使检索逻辑与模型的推理过程同步。最终,通过路径融合与多阶段增强机制,显著提升模型在多步骤复杂推理任务中的表现。实验在两个医学多选问答数据集MedMCQA与MedQA上进行,相比传统Graph-RAG方法,该框架在多个模型中实现了高达10%的诊断精度提升。例如,在MedMCQA数据集上,该方法结合GPT-4o模型达到Precision 92.90%、Recall 93.33%、F1分数0.95的水平,大幅优于传统方法和原始模型响应结果。
核心观点: 构建因果优先子图实现推理路径优化:传统知识图谱检索多采用“相关性”边,缺乏因果方向,导致检索路径混乱、信息冗余、逻辑不连贯。本研究通过定义因果评分函数对边进行加权筛选,仅保留因果强度高于阈值的边构成因果子图。此外,采用因果挖掘算法持续更新边的权重,使知识图谱具备清晰的因果结构,显著提升模型的推理清晰度与可靠性。
链式思维引导图检索,实现推理与检索的高效协同:通过引入链式思维(CoT)方法,将模型的整体推理过程分解为若干子问题,并对每一子问题执行专门的图检索步骤。这种按步骤驱动的图检索方式,使模型在每一推理节点都能获得与当前上下文高度匹配的知识片段,从而实现检索内容与推理逻辑的精准对齐。此举有效减少了传统方法中“检索内容与推理需求不匹配”所造成的逻辑断裂与推理错误。
多阶段路径融合与一致性增强,提升最终推理输出质量:在完成初步检索后,系统对所有路径执行融合、去重与打分操作。路径评分函数综合考虑临床实体重叠(CUI overlap)、语义类型一致性与路径长度等因素,对各路径进行量化处理并筛选出高质量子图。最终将筛选结果与原始CoT一同注入语言模型,执行一致性验证与推理增强。该机制显著提高了模型输出结果的逻辑连贯性与可解释性。在MedQA数据集上,该方法结合GPT-4o模型取得Precision 88.36%的成果,远高于传统Graph-RAG方法的83.07%。
整体框架分为三个阶段:(1)构建与更新因果图;(2)基于链式思维的检索过程;(3)多阶段路径处理与优化。
信息来源:
https://arxiv.org/pdf/2501.14892
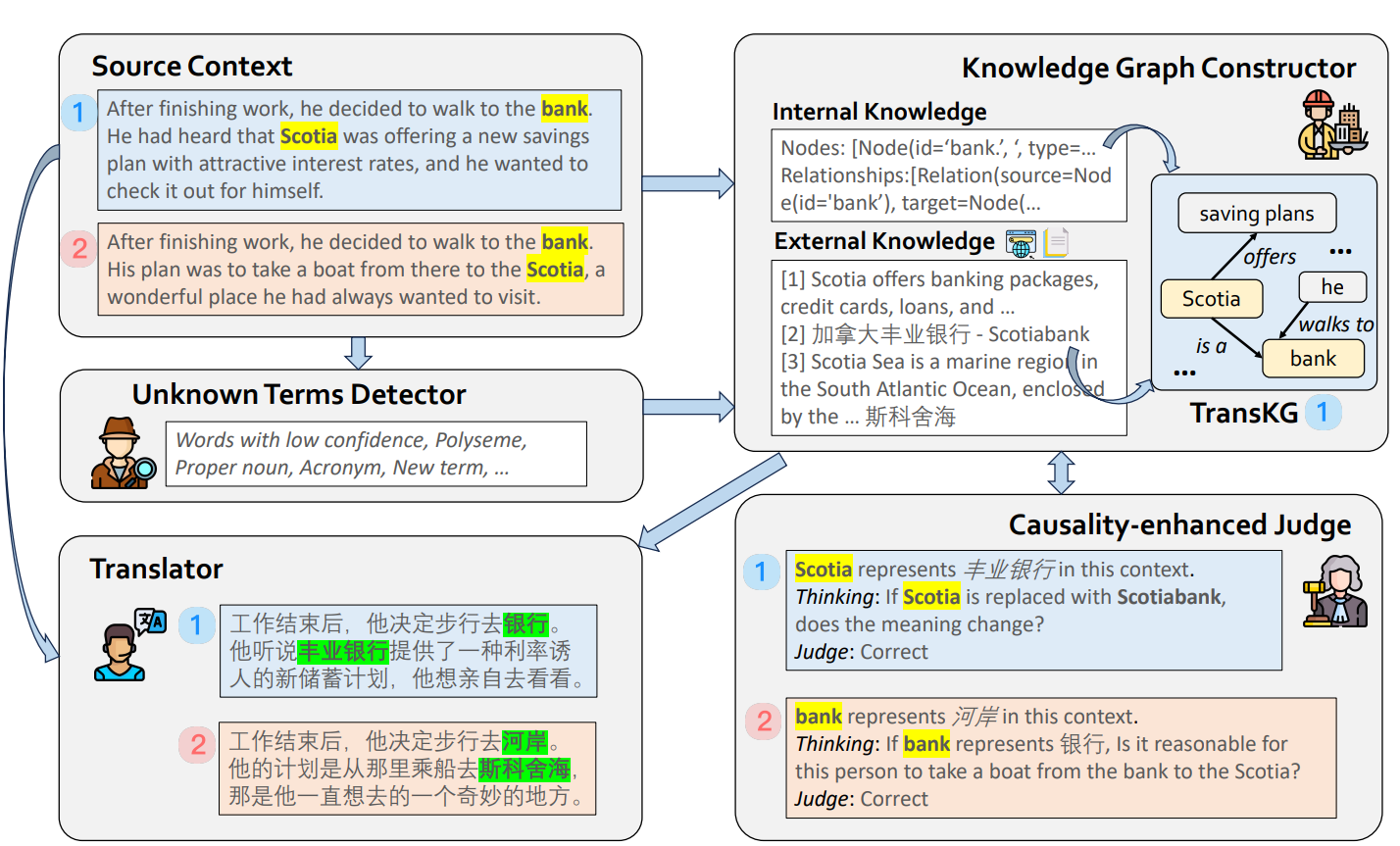
6.北京大学与腾讯微信AI联合提出CRAT多智能体框架,在处理语境敏感术语的英汉翻译任务中实现BLEU提升3.1点、CONSIS提升3.3点的显著成效 摘要: 面对大语言模型(LLM)在机器翻译任务中易受上下文歧义和术语变异影响的问题,北京大学联合腾讯微信AI模式识别中心,提出了CRAT(Causality-enhanced Reflective and Retrieval-Augmented Translation),一种多智能体因果增强反思与检索辅助翻译框架。该方法针对术语识别困难、语义偏差以及翻译一致性差等现实挑战,创新性引入四类协作智能体:未知术语识别代理、知识图谱构建代理、因果反思验证代理与翻译代理,从语义识别、知识构建到因果验证全过程优化LLM的翻译能力。在使用GPT-4o与Qwen-72B模型进行的英汉双向翻译实验中,CRAT框架在New York Times 2024年度新闻报道数据集上展现出显著性能提升。具体而言,GPT-4o模型引入CRAT后,BLEU从32.7提升至33.5,CONSIS从83.5上升至86.7;Qwen-72B模型BLEU从29.9提升至30.8,CONSIS从81.7提高至85.0。
核心观点: 构建术语知识图谱并实现语境感知结构化:CRAT框架通过知识图谱构建智能体对上下文中的术语进行语义抽取与结构化表达。内部知识通过句法解析挖掘实体及其关系(如“Scotia”与“offers savings plan”),外部知识则从在线数据库获取双语术语定义与领域专属信息(如“Scotiabank”金融服务 vs “Scotia Sea”地理定义)。图谱中的节点和边构成TransKG,反映术语在具体语境下的含义基础,并实现术语多义性消解和上下文语义精准对齐。该模块的引入使LLMs获得可验证的背景语义支持,明显缓解其语义漂移问题。
因果性反思机制确保术语语义的一致性与稳定性:为避免语境歧义导致翻译语义偏差,CRAT框架引入因果增强验证机制。当外部知识被接入TransKG后,由因果反思智能体执行语义一致性检验,例如替换“Scotia”为“Scotiabank”后是否逻辑一致,是否与路径“乘船去Scotia”合理。该机制依据因果不变性原理,结合反事实推理(如替换回原文是否语义一致)判定外部语义是否有效并过滤错误信息。验证通过的术语定义将被作为翻译输入,有效防止模型生成不符语境的“幻觉”式翻译结果,是CRAT中保持语义鲁棒性的关键技术。
多智能体联动提升翻译准确度与术语处理一致性:CRAT框架通过四类代理模块构建多阶段处理路径,分别针对术语识别、语义图构建、语义验证及最终翻译环节进行优化。相较于直接使用LLM翻译方法,CRAT实现从语义识别到图谱生成再到翻译生成的全过程精化,特别是在处理低置信度术语、多义词、新词等方面表现出显著优势。例如Qwen-72B模型原始翻译“phin”为“滤杯”,而引入CRAT后修正为“滴滤咖啡壶”;GPT-4o处理“cosmetic overhauls”时也从“美容翻新”修正为“外观调整”,提升术语译文的专业性与上下文契合度。综合BLEU、COMET与CONSIS等指标提升,验证了CRAT对复杂语义翻译的一致性与准确性强化作用。
多智能体翻译框架
信息来源:
https://arxiv.org/pdf/2410.21067
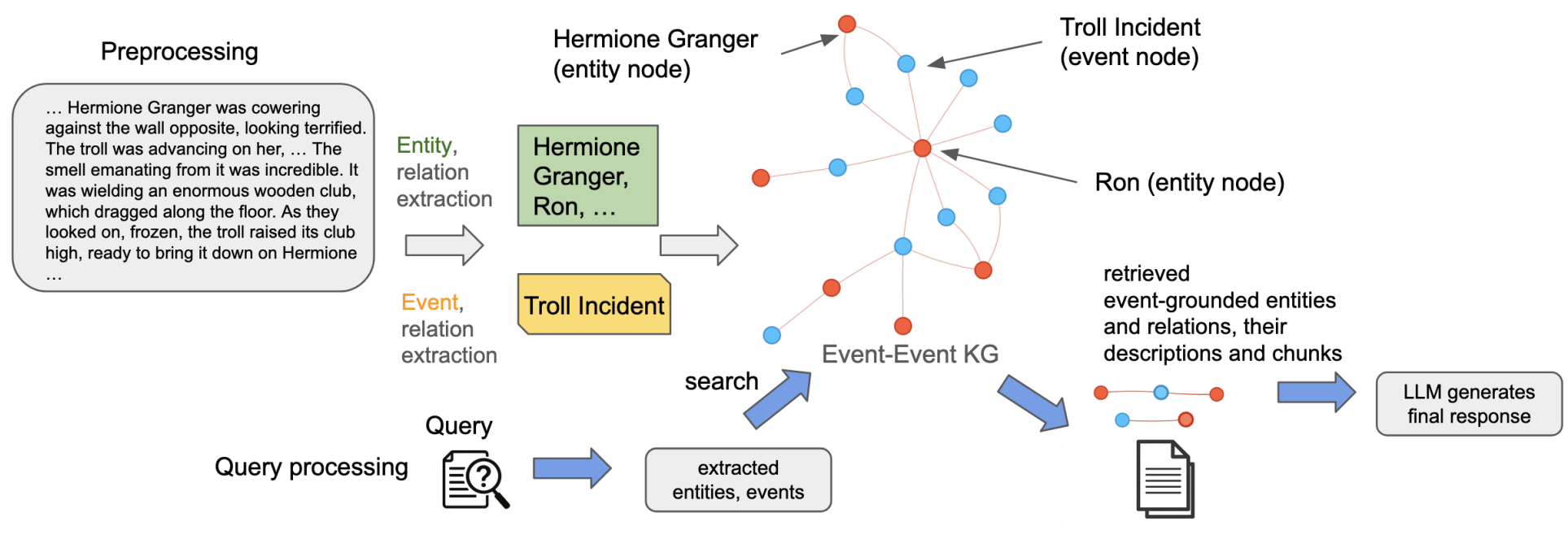
7.新加坡国立大学与阿里巴巴集团联合提出E²RAG双图框架,在叙事文档的检索增强生成任务中显著提升因果一致性与角色一致性理解能力 摘要: 在大型语言模型(LLMs)广泛应用于自然语言处理任务的背景下,传统检索增强生成(RAG)方法在处理具有时间因果结构的叙事文档时表现不佳,主要原因在于其无法有效编码或利用时间信息。为解决该问题,新加坡国立大学计算机系与阿里巴巴集团的研究团队联合提出了Entity–Event RAG(E²RAG)框架,该方法通过构建实体图与事件图并以双向映射连接,保留了叙事文本中的时间与因果关系,从而实现更精细的推理能力。研究团队构建了一个名为ChronoQA的问答基准数据集,用于评估模型在时间一致性、因果一致性和角色一致性方面的理解能力。实验结果显示,E²RAG在ChronoQA上的表现显著优于现有的非结构化RAG和基于知识图谱的RAG方法,尤其在因果一致性和角色一致性查询上取得了显著提升。该框架为需要时间敏感推理的检索任务提供了更具上下文意识的解决方案。
核心观点: 实体图与事件图分离建模:E²RAG框架摒弃了传统知识图谱RAG方法中将所有实体合并为单一节点的做法,而是分别构建了“实体图”(Entity Graph)与“事件图”(Event Graph),并通过双向映射机制(Entity Event)将两者关联起来。这种结构使得模型能够精细地保留角色在叙事中跨时间的语义变化,同时捕捉事件之间的因果顺序。例如,如果某角色在不同时间参与了多个因果相关的事件,传统图结构可能无法展现其行为演化逻辑,而E²RAG则通过节点状态随时间更新的方式,有效编码了时间动态。这一设计弥补了现有RAG模型在时间敏感文本建模上的结构缺陷,使模型具备更强的上下文一致性和推理深度。
推动时间因果一致性评估标准化:研究团队意识到现有的问答基准数据集多数缺乏对时间与因果推理能力的评估维度,因此提出了ChronoQA,这是首个专注于叙事文档时间一致性、因果一致性与角色一致性理解能力的数据集。该数据集涵盖了从儿童文学、小说到历史文献等多种体裁,通过设计针对三类一致性的问题模板,对模型的深层理解能力进行系统性挑战。尤其在角色一致性方面,ChronoQA中的问题不仅要求模型记住角色事件,还需推断其行为逻辑和情感动机,如“角色面对特定情境会如何反应”这类问题。这种设计推动了叙事推理模型从信息检索走向语义理解,开启了基准测试的新维度,对RAG类模型发展具有重要的推动作用。
在一致性查询任务上显著优于现有方法:E²RAG展示了在处理叙事文本一致性问题上的显著优势。通过构建实体图与事件图并建立双向映射,模型能够更有效地捕捉角色行为的变化、事件之间的因果关系和时间序列结构,使得生成的回答更具语义连贯性与逻辑一致性。实验对比表明,该框架在复杂推理任务中更能保留文本的语义细节,尤其在处理跨时间推理或角色动机相关的查询时展现出更高的解释能力。这说明E²RAG在结构设计上的突破不仅提升了语言模型的推理效果,也增强了其在语义理解层面的应用潜力。
整体框架图
信息来源:
https://arxiv.org/pdf/2506.05939
推荐学习书籍 《CDA一级教材 》适合CDA一级考生备考,也适合业务及数据分析 岗位的从业者提升自我。完整电子版已上线CDA网校,累计已有10万+在读~ ! 

 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏