大型语言模型的“上下文工程”:从提示词到智能系统的进化指南
论文标题:A Survey of Context Engineering for Large Language Models
arXiv:2507.13334 [pdf, ps, other] cs.CL
A Survey of Context Engineering for Large Language Models
Authors: Lingrui Mei, Jiayu Yao, Yuyao Ge, Yiwei Wang, Baolong Bi, Yujun Cai, Jiazhi Liu, Mingyu Li, Zhong-Zhi Li, Duzhen Zhang, Chenlin Zhou, Jiayi Mao, Tianze Xia, Jiafeng Guo, Shenghua Liu
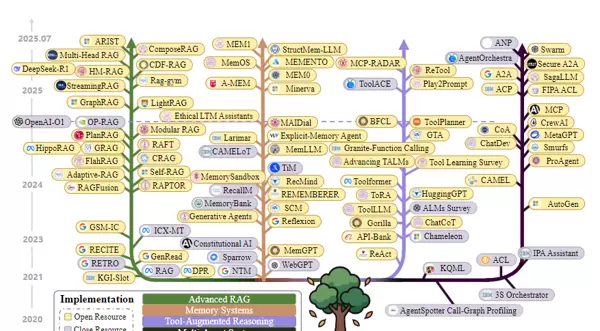
研究背景:LLM的“上下文困境”与解决需求
当我们和ChatGPT聊天时,有没有遇到过这样的情况:聊了几轮后,它突然忘记了前面说过的关键信息?或者让它写一篇长报告,前面逻辑清晰,后面却开始重复甚至跑偏?这背后藏着大型语言模型(LLMs)的一个核心难题——
上下文处理能力的局限
。
早期,我们靠“提示词工程(Prompt Engineering)”来优化LLM的输出,比如用“请一步一步思考”引导推理。但随着LLM应用从简单问答转向复杂任务(如智能客服、科研分析、多智能体协作),这种“静态提示词”的方式越来越不够用了:
-
当需要处理超长文档(如法律条文、学术论文)时,LLM的“注意力”会像人一样“走神”,中间的关键信息容易被忽略(即“中间遗忘”现象);
-
当需要结合外部知识(如最新新闻、企业内部数据)时,固定提示词无法动态更新信息;
-
当需要长期交互(如持续跟进用户需求)时,LLM缺乏“记忆”,每次对话都像“重新认识”用户。
这些问题指向一个核心:LLM的性能不仅取决于模型本身的参数,更取决于
如何设计、管理和优化输入给它的“上下文”
。于是,“上下文工程(Context Engineering)”应运而生——它不再是简单的提示词设计,而是一套系统优化LLM信息输入的方法论。
一段话总结:
本文是对
大型语言模型(LLMs)的上下文工程(Context Engineering)
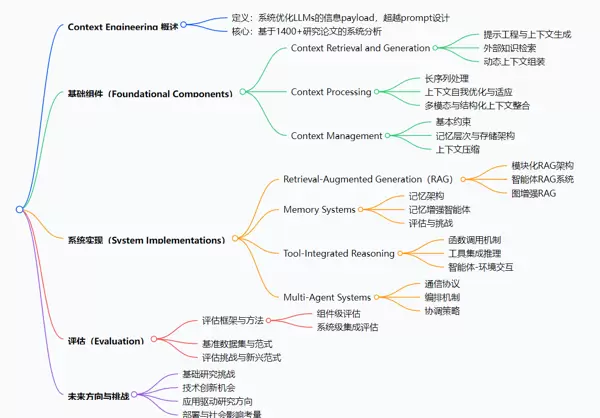
的综述,通过分析超过1400篇研究论文,提出上下文工程作为一门正式学科,超越简单的提示设计,涵盖LLMs信息 payload 的系统优化。其核心包括三大
基础组件
(上下文检索与生成、上下文处理、上下文管理)和四大
系统实现
(检索增强生成(RAG)、记忆系统、工具集成推理、多智能体系统)。研究发现,当前LLMs在复杂上下文理解上表现突出,但在长文本生成方面存在显著局限,这一不对称性是未来研究的关键缺口,同时提供了统一框架为研究者和工程师推进上下文感知AI提供指导。
主要作者及单位信息
本文由来自多所顶尖机构的研究者合作完成,包括:
-
中国科学院计算技术研究所
-
加州大学默塞德分校
-
昆士兰大学
-
北京大学、清华大学
-
中国科学院大学
核心作者团队包括Lingrui Mei、Jiayu Yao、Yuyao Ge等,研究得到了网络数据科学与技术重点实验室等机构的支持。
创新点:重新定义“上下文”,构建完整体系
这篇论文的最大亮点在于
将“上下文工程”确立为一门正式学科
,并首次提出了系统的分类框架。具体来说,它的创新体现在三个方面:
-
超越“提示词”的动态视角
:不再把上下文看作静态的“提示字符串”,而是将其定义为“动态结构化的信息组件集合”,这些组件可以来自提示词、外部知识、记忆、工具等(公式:(C=\mathcal{A}(c_1, c_2, …, c_n)))。
-
首次构建“基础组件+系统实现”的双层框架
:将上下文工程拆解为“基础组件”(处理信息的底层能力)和“系统实现”(基于组件的上层应用),理清了领域内零散技术的内在联系。
-
揭示关键研究缺口
:通过分析1400+篇论文,发现当前LLM存在“理解-生成不对称”——能很好地理解复杂上下文,但难以生成同等质量的长文本,这一发现为未来研究指明了方向。
研究方法:系统梳理+分类整合,让零散技术“有章可循”
论文采用“综述研究”方法,通过三步构建完整框架:
步骤1:明确研究范围
从LLM的“输入-输出”逻辑出发,聚焦“如何优化输入上下文以提升输出质量”,排除了模型训练、参数优化等不直接相关的内容。
步骤2:拆解核心能力为“基础组件”
将上下文工程的底层能力拆解为3大组件,每个组件包含具体技术:
-
上下文检索与生成
:负责“找信息”和“造信息”,包括提示词设计(如链-of-thought)、外部知识检索(如RAG)、动态组装(如自动优化信息组合)。
-
上下文处理
:负责“处理信息”,包括长文本处理(如Mamba架构)、自我优化(如LLM自我纠错)、多模态整合(如图文结合)。
-
上下文管理
:负责“管好信息”,包括记忆层次设计(如短期/长期记忆)、上下文压缩(如减少冗余信息)。
步骤3:整合组件为“系统实现”
基于基础组件,梳理出4类典型应用场景(系统实现):
-
检索增强生成(RAG)
:结合外部知识的生成(如用知识库回答问题)。
-
记忆系统
:让LLM拥有“长期记忆”(如记住用户偏好)。
-
工具集成推理
:让LLM调用工具(如计算器、API)解决问题。
-
多智能体系统
:多个LLM智能体协作(如分工完成复杂任务)。
主要贡献:为领域提供“地图”和“路标”
这篇论文的核心价值在于
为混乱的“上下文工程”领域提供了清晰的“导航系统”
:
-
理论层面
:首次给出“上下文工程”的正式定义和数学框架,让零散的技术(如RAG、记忆系统)有了统一的理论基础。
-
实践层面
:
-
研究者可以通过分类框架定位自己的研究方向,避免重复劳动;
-
工程师可以按“基础组件→系统实现”的路径搭建实用系统(如用RAG+记忆系统构建智能客服)。
-
未来方向
:明确指出“理解-生成不对称”是关键挑战,建议未来研究聚焦长文本生成优化、多模态整合等方向。
思维导图:
详细总结:
1. 引言与定义
-
上下文工程(Context Engineering)
被定义为一门正式学科,将LLMs的输入上下文C重新概念化为动态结构化的信息组件集合((c_1, c_2, …, c_n)),通过组装函数A整合,目标是最大化LLMs输出质量,同时受限于上下文长度限制((|C| ≤ L_{max}))。
-
与传统提示工程相比,其核心差异在于从静态提示字符串转向动态、结构化的信息组装,注重系统级优化(见表1)。
|
维度
|
Prompt Engineering
|
Context Engineering
|
|
模型
|
C = prompt(静态字符串)
|
(C = \mathcal{A}(c_1, c_2, …, c_n))(动态结构化组装)
|
|
目标
|
最大化(P_\theta(Y
|
prompt))
|
|
复杂度
|
字符串空间的手动/自动搜索
|
系统级优化(\mathcal{F} = {A, Retrieve, Select, …})
|
2. 为什么需要上下文工程
-
当前局限性
:LLMs的自注意力机制随序列长度呈二次计算开销,存在幻觉、对输入变化敏感等可靠性问题,提示工程方法主观且局限于任务优化。
-
性能提升
:通过检索增强生成等技术,实现18倍文本导航精度提升、94%成功率等显著改进,链-of-thought等结构化提示提升复杂推理能力。
-
资源优化
:通过智能内容过滤减少token消耗,动态上下文优化提升信息密度。
3. 基础组件
-
上下文检索与生成
:包括提示工程(零样本、少样本学习,链-of-thought等)、外部知识检索(RAG基础、知识图谱整合)、动态上下文组装(模板格式化、自适应组合)。
-
上下文处理
:解决长序列处理(如Mamba、LongNet等架构创新)、自我优化(Self-Refine等方法)、多模态与结构化信息整合(知识图谱嵌入、图神经网络)。
-
上下文管理
:应对有限上下文窗口,构建记忆层次(如MemGPT的类操作系统内存管理)、上下文压缩(如ICAE实现4倍压缩)。
4. 系统实现
-
检索增强生成(RAG)
:包括模块化架构(如FlashRAG的5个核心模块)、智能体RAG(动态检索与反思)、图增强RAG(利用知识图谱提升多跳推理)。
-
记忆系统
:分类为短期/长期记忆,实现持久交互(如MemoryBank基于艾宾浩斯遗忘曲线动态调整记忆强度),应用于个性化助手等场景。
-
工具集成推理
:函数调用机制(如Toolformer的API学习)、多工具协调(如ReAct的“思考-行动-观察”循环)、智能体-环境交互(如ReTool的强化学习优化)。
-
多智能体系统
:通信协议(如KQML、MCP)、编排机制(如3S orchestrator的先验/后验编排)、协调策略(解决事务完整性与上下文处理失败)。
5. 评估
-
框架与方法
:组件级评估(如长上下文处理的“needle in a haystack”范式)、系统级评估(如RAG的检索与生成质量)。
-
挑战
:传统指标不足(如BLEU不适合复杂推理)、记忆评估缺乏标准化、工具集成系统与人类能力差距大(如GPT-4在GTA基准完成率<50%,人类为92%)。
6. 未来方向
-
基础研究
:统一理论框架、解决理解与生成能力不对称(核心缺口)、多模态整合。
-
技术创新
:下一代架构(如Mamba的线性缩放)、复杂上下文组织(图问题解决)、智能上下文组装。
-
应用与部署
:领域专业化(医疗、科研)、大规模多智能体协调、伦理与安全考量。
关键问题:
-
问题
:上下文工程与传统提示工程的核心区别是什么?
答案
:两者的核心区别体现在多个维度,传统提示工程将上下文视为静态字符串(C = prompt),目标是最大化输出概率,复杂度限于字符串空间搜索;而上下文工程将上下文视为动态结构化组件的组装((C = \mathcal{A}(c_1, c_2, …, c_n))),目标是系统级优化信息函数以最大化预期奖励,具有状态性和模块化,可通过组件调试提升性能(见表1)。
-
问题
:上下文工程的基础组件包含哪些关键技术?
答案
:基础组件包括三大类:①
上下文检索与生成
,涵盖提示工程(如链-of-thought)、外部知识检索(如RAG)、动态组装(如自动提示优化);②
上下文处理
,包括长序列处理(如Mamba、LongNet)、自我优化(如Self-Refine)、多模态/结构化整合(如知识图谱嵌入);③
上下文管理
,涉及记忆层次(如MemGPT的内存分页)、上下文压缩(如ICAE的4倍压缩)。
-
问题
:当前上下文工程面临的最关键挑战及未来研究重点是什么?
答案
:最关键挑战是
LLMs理解复杂上下文的能力与生成复杂长文本的能力存在根本不对称
(核心缺口)。未来研究重点包括:建立统一理论框架、解决长文本生成的架构限制(如超越Transformer的二次复杂度)、多模态整合(如图与语言的对齐)、领域专业化应用(如医疗的安全评估)、确保大规模部署的安全性与伦理。
总结:从“玩提示词”到“建系统”的进化
这篇论文通过系统分析,将LLM的上下文处理从“零散技巧”升级为“系统学科”。它的核心结论包括:
-
上下文工程是优化LLM性能的核心,涵盖信息的检索、处理、管理和应用;
-
当前LLM擅长理解复杂上下文,但长文本生成能力薄弱,这是未来突破的关键;
-
提供的“基础组件+系统实现”框架,为研究者和工程师提供了统一的“方法论工具”。
简言之,这篇论文不仅总结了过去,更定义了未来——让LLM从“会聊天的工具”变成“能理解、会记忆、善协作的智能系统”。


 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏





