文章目录
- 最致命的幻觉:前视偏差(未来函数)
- 幸存者偏差:你回测的股票,今天已经是巨头了
- 数据挖掘偏差:你不是找因子,你是在调参骗自己
- 交易成本与滑点:回测的杀手
- 让我们把所有东西放在一起:幻觉策略 vs 真实策略
一、最致命的幻觉:前视偏差(未来函数)
未来函数是所有回测灾难的主要元凶。
为了让你了解它有多危险,我们用一个极其简单的例子。
你想测试一个“低价买入”的策略,于是你编写:
signal = data['Close'] < data['Close'].rolling(30).mean()
这看起来很合理,对吧?
30 日均线是过去 30 天的平均价。这也被称为 MA(Moving Average,移动平均线),即“过去 N 天价格的平均值”。例如 30 日 MA,就是把过去 30 天的收盘价相加再除以 30。
它的作用是:将每天波动的价格平滑化,让你看到“最近一个月的整体趋势”。
但你忘记了:
rolling(30).mean() 只能在当天收盘后才能知道。
如果你用它来决定当天是否买入,你在作弊。
为了让你感受到“偷看未来”的巨大差异,我直接给你对比代码。
幻觉回测:当日信号吃当日收益
用“当天收盘价”去产生“当天的交易信号”,然后还让这个信号买入“当天的收盘价”。这在日线回测中就是明显的未来函数。
我们看看典型的错误代码:
import yfinance as yf
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
df = yf.download("AAPL", start="2020-01-01", end="2025-01-01", auto_adjust=True)
# 未来函数:rolling(30).mean() 用到了“当天收盘价”
ma30 = df['Close'].rolling(30).mean()
# 未来函数:用当天的信号去吃当天的收益
signal_fake = df['Close'] > ma30
returns = df['Close'].pct_change()
# 致命未来函数:当日信号 × 当日收益
equity_fake = (1 + returns * signal_fake).cumprod()
画一下曲线:
equity_fake.plot(figsize=(12,6))
plt.title("Illusion Strategy: Backtesting with Future Data")
plt.show()
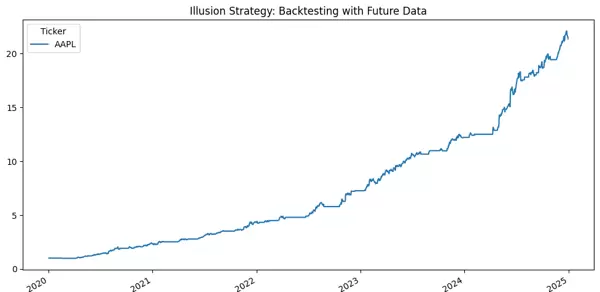
你看到的会是这样一条曲线:
- 几乎没有回撤
- 趋势抓得完美
- 黑天鹅都像提前预知
- 整体平滑得像“自动印钱机”
为什么?
因为这段代码假设:
- 你每天在收盘前提前知道收盘价,然后用这个信息下单。
- 你不是在做量化,你是在当神。
当然赚钱。
真实回测:只用“昨天能看到的数据”来做决策
正确的写法只有一个要点:
今天的仓位,只能根据昨天收盘前已经发生的事情决定。
这意味着两件事:
- rolling(30) 必须 shift(1),确保只用到昨天的收盘价
- 交易信号也必须 shift(1),确保用的是“昨天的信号”执行“今天的交易”
正确代码:
# 正确:滚动均线必须只用到 t-1 的价格
ma30_real = df['Close'].rolling(30).mean().shift(1)
# 正确:今天的信号基于昨天的 MA
signal_real = df['Close'] > ma30_real
# 准确:今日交易依据昨日信号
equity_real = (1 + returns * signal_real.shift(1)).cumprod()
equity_real.plot(figsize=(12,6))
plt.title("实际策略:避免前瞻偏差")
plt.show()
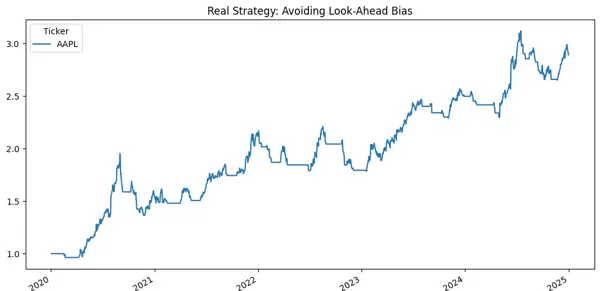 与真实的回测比较,你会发现:
曲线显著更加波动
出现真实的资金回撤
可能会错过趋势
可能在错误时间买入
可能经历多年的横盘整理
收益不够稳定
换句话说,它最终成为:
一种普通人可以实施的策略。
一种接近现实情况的策略。
而非“全知视角 + 采用当日收盘价”的作弊手段。
为何两者差距如此之大?
原因非常简单:
虚构回测 = 当日收盘价生成信号 + 当日收盘价买入
→ 这假设你在看到 K 线收盘后能返回收盘价下单。
实际回测 = 前一日数据生成信号 + 当日开盘或全天收益
→ 这是在现实中你能做到的真实情况。
总结来说:
差距不仅在于一个 shift,更在于“是否使用了未来的数据进行交易”。
第二部分、幸存者偏差:你回测的股票,现在已是行业巨头
此类偏差比未来函数更为隐蔽。
你并未窥探“未来的价格”,
而是窥探了:
哪些企业能够生存、壮大、成为行业领袖。
如果你使用“当前仍活跃的明星企业”来回测十年前的市场,
实际上你假设了:
十年前你已知晓苹果不会消亡、微软不会倒闭、英伟达不会停滞、特斯拉不会破产。
这显然是作弊行为。
为了让这种偏差显得更加明显,我们用一个
完全可执行
的方法重新展示:
虚构回测:用“现今存活的胜利者”测试十年前的情况
这是初学者最常见的错误:
打开 yfinance
选择一批现在的科技巨头
回测 2010-2020
发现一切美好得如同印钞机
查看代码:
import yfinance as yf
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 这些是 2025 年依然风光无限的巨头 —— 典型的幸存者
survivors = [
"AAPL","MSFT","AMZN","GOOG","META",
"NVDA","TSLA","BRK-B","JPM","V","MA"
]
data_surv = yf.download(
survivors,
start="2010-01-01",
end="2020-01-01",
auto_adjust=True
)["Close"]
ret_surv = data_surv.pct_change().mean(axis=1).fillna(0)
equity_surv = (1 + ret_surv).cumprod()
equity_surv.plot(figsize=(12,6))
plt.title("虚构回测:用‘今日的幸存者’回测十年前的情况")
plt.show()
与真实的回测比较,你会发现:
曲线显著更加波动
出现真实的资金回撤
可能会错过趋势
可能在错误时间买入
可能经历多年的横盘整理
收益不够稳定
换句话说,它最终成为:
一种普通人可以实施的策略。
一种接近现实情况的策略。
而非“全知视角 + 采用当日收盘价”的作弊手段。
为何两者差距如此之大?
原因非常简单:
虚构回测 = 当日收盘价生成信号 + 当日收盘价买入
→ 这假设你在看到 K 线收盘后能返回收盘价下单。
实际回测 = 前一日数据生成信号 + 当日开盘或全天收益
→ 这是在现实中你能做到的真实情况。
总结来说:
差距不仅在于一个 shift,更在于“是否使用了未来的数据进行交易”。
第二部分、幸存者偏差:你回测的股票,现在已是行业巨头
此类偏差比未来函数更为隐蔽。
你并未窥探“未来的价格”,
而是窥探了:
哪些企业能够生存、壮大、成为行业领袖。
如果你使用“当前仍活跃的明星企业”来回测十年前的市场,
实际上你假设了:
十年前你已知晓苹果不会消亡、微软不会倒闭、英伟达不会停滞、特斯拉不会破产。
这显然是作弊行为。
为了让这种偏差显得更加明显,我们用一个
完全可执行
的方法重新展示:
虚构回测:用“现今存活的胜利者”测试十年前的情况
这是初学者最常见的错误:
打开 yfinance
选择一批现在的科技巨头
回测 2010-2020
发现一切美好得如同印钞机
查看代码:
import yfinance as yf
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 这些是 2025 年依然风光无限的巨头 —— 典型的幸存者
survivors = [
"AAPL","MSFT","AMZN","GOOG","META",
"NVDA","TSLA","BRK-B","JPM","V","MA"
]
data_surv = yf.download(
survivors,
start="2010-01-01",
end="2020-01-01",
auto_adjust=True
)["Close"]
ret_surv = data_surv.pct_change().mean(axis=1).fillna(0)
equity_surv = (1 + ret_surv).cumprod()
equity_surv.plot(figsize=(12,6))
plt.title("虚构回测:用‘今日的幸存者’回测十年前的情况")
plt.show()
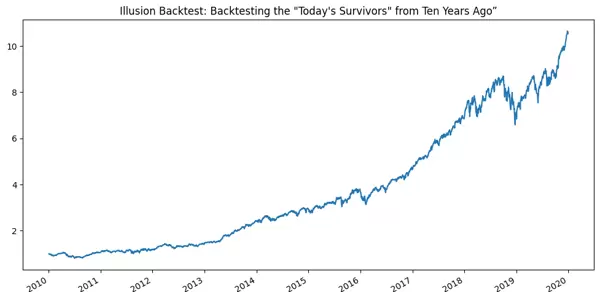 曲线必定:
平稳上升
轻微回撤
越来越强劲
完美得仿佛“长期持有科技股非常简单”
但这只是幻象。
因为你排除了所有:
曾经辉煌
后来消亡
被移出指数
被收购、退市
濒临破产的小企业
你只留下了“胜利者”,
自然看起来很好。
真实回测:每年重新选取“当时存在的公司”
现实世界不是“胜利者的俱乐部”,
而是“每天都有公司消亡、兴起、变成垃圾股”。
为了让你看到真实的丑陋,我们用一个简明但贴近现实的方法模拟:
将 S&P 500 股票视为“宇宙集”(yfinance 可获取)
每年随机挑选 30 家作为“当年市场上的公司”
→ 模拟退市、替换、IPO、崩溃
→ 极大程度地还原现实世界的混乱
对每年的股票池分别回测,再拼接成整体
可执行代码如下:
equity_real = pd.Series(dtype=float)
prev_equity = 1.0
for year in range(2010, 2020):
tickers = pick_yearly_stocks(universe)
df_year = yf.download(
tickers,
start=f"{year}-01-01",
end=f"{year+1}-01-01",
auto_adjust=True
)["Close"]
ret_year = df_year.pct_change().mean(axis=1).fillna(0)
# 关键:逐年累积收益,拼接成完整曲线
year_curve = prev_equity * (1 + ret_year).cumprod()
prev_equity = year_curve.iloc[-1]
曲线必定:
平稳上升
轻微回撤
越来越强劲
完美得仿佛“长期持有科技股非常简单”
但这只是幻象。
因为你排除了所有:
曾经辉煌
后来消亡
被移出指数
被收购、退市
濒临破产的小企业
你只留下了“胜利者”,
自然看起来很好。
真实回测:每年重新选取“当时存在的公司”
现实世界不是“胜利者的俱乐部”,
而是“每天都有公司消亡、兴起、变成垃圾股”。
为了让你看到真实的丑陋,我们用一个简明但贴近现实的方法模拟:
将 S&P 500 股票视为“宇宙集”(yfinance 可获取)
每年随机挑选 30 家作为“当年市场上的公司”
→ 模拟退市、替换、IPO、崩溃
→ 极大程度地还原现实世界的混乱
对每年的股票池分别回测,再拼接成整体
可执行代码如下:
equity_real = pd.Series(dtype=float)
prev_equity = 1.0
for year in range(2010, 2020):
tickers = pick_yearly_stocks(universe)
df_year = yf.download(
tickers,
start=f"{year}-01-01",
end=f"{year+1}-01-01",
auto_adjust=True
)["Close"]
ret_year = df_year.pct_change().mean(axis=1).fillna(0)
# 关键:逐年累积收益,拼接成完整曲线
year_curve = prev_equity * (1 + ret_year).cumprod()
prev_equity = year_curve.iloc[-1]
equity_real = pd.concat([equity_real, year_curve])
绘制图表:
equity_real.plot(figsize=(12,6))
plt.title("实际回测:包括退市、更换和亏损股票的股票池。")
plt.show()
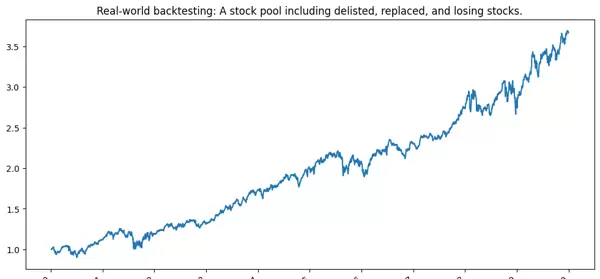
虽然看起来很相似,但看看Y轴的比例就能看出差异。
这条曲线会:
波动
混乱
有些年份不盈利
甚至长期表现不如幸存者池。
但这就是现实世界。
并非每家公司都能成为苹果、英伟达、特斯拉。
大多数公司的最终命运,并非“巨头”,而是:
破产
被收购
长期停滞不前
萎缩成垃圾股
如果你的回测只包含赢家,那不是策略,而是历史过滤器。
为什么幸存者偏差会使回测结果更好看?
因为你假设了一种不切实际的能力:
我能提前十年预知谁会成为巨头。
如果你真有这种能力,你也不会在这里编写Python代码。
幸存者偏差不仅仅是“数据不干净”的问题,
而是你无意中将未来的信息混入了历史。
真实的回测结果虽然难看,
但更加真实。
三、数据挖掘偏差:你不是寻找因子,而是在调整参数自欺欺人
最常见的错误做法:
尝试100个参数
尝试100种窗口
尝试100个阈值
最后选择历史上“最赚钱的那个”。
你以为你发现了因子。
实际上你只是从10,000个噪音中挑选了一个幸运儿。
为了让你感受这种荒谬性,我给你一个小实验:
我们用纯随机数构建一个“因子”——完全没有金融意义。
但你仍然可以找到“盈利的策略”。
实验:纯随机因子也能生成一条“异常出色”的曲线
以下是一段可运行的代码(你可以真正运行一次):
import yfinance as yf
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 1. 下载数据
df = yf.download(
"AAPL",
start="2015-01-01",
end="2025-01-01",
auto_adjust=True
)
df = df[["Close"]] # 仅保留收盘价
df["ret"] = df["Close"].pct_change().fillna(0)
# 2. 构建纯随机“因子”
np.random.seed(42)
df["factor"] = np.random.randn(len(df))
# 分位数排名(看起来像“信号”)
df["signal"] = (df["factor"].rank(pct=True) > 0.5).shift(1)
df["signal"] = df["signal"].fillna(False).astype(int)
# 3. 回测:随机信号决定是否持仓
df["strategy_ret"] = df["ret"] * df["signal"]
# 4. 累计收益曲线
df["equity_strategy"] = (1 + df["strategy_ret"]).cumprod()
df["equity_buyhold"] = (1 + df["ret"]).cumprod()
# 5. 绘制图表
plt.figure(figsize=(12, 6))
df["equity_strategy"].plot(label="随机因子策略")
df["equity_buyhold"].plot(label="持有AAPL", linestyle="--")
plt.title("随机噪声因子回测与持有AAPL对比")
plt.ylabel("权益曲线")
plt.xlabel("日期")
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()
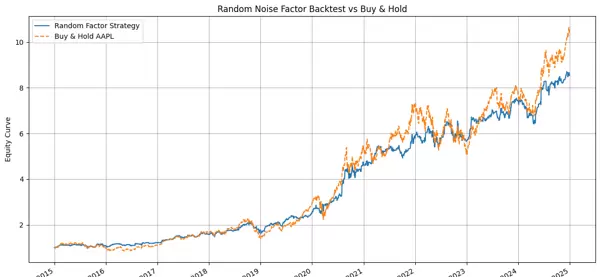
你会看到什么?
你会看到一个
令人不安的结果:
曲线并不是水平的
曲线甚至可能稳定上升
有时还能跑赢指数
完全像是一个“稍微聪明的策略”
但你知道真相:
这是
纯·随·机·噪·声。
因子根本不存在。
模式根本不存在。
收益完全是历史的巧合。
为什么纯随机也能“盈利”?
因为当你尝试足够多的噪声时:
总有一条噪声会恰好形成漂亮的曲线,这就像中彩票的概率一样。
而你以为那是“因子发现”。
实际上你只是:
对历史“调整参数”
对噪声“刷榜”
对过拟合“制造幻觉”
换句话说:
你不是在寻找因子,而是在欺骗自己。
四、交易成本与滑点:回测的致命因素
绝大多数“漂亮的回测”在现实中只有一个结局:
被交易成本和滑点直接摧毁。
你在回测中看到的年化30%,
在真实市场中通常只剩下5%,甚至是负数。
为什么?
因为在回测中交易是免费的。
现实中则不然。
成本如何摧毁策略?
成本的本质是:
你只要稍微移动,就需要支付费用。
新手常见的错误:
- 信号快速波动 → 每天调整仓位三次
- 频繁更换仓位 → 手续费激增
- 交易量巨大 → 自己推高价格(编写代码的人将自己视为市场冲击力 0 的幽灵)
结果显而易见:
接下来,我们将通过一段代码,直观展示这个“死亡现场”。
构建一个“无成本 vs 包含成本”的对比
我们首先创建一个信号(比如前面章节的动量信号):
为了简化,这里使用随机信号替代(仅展示成本影响,不涉及策略逻辑)。
import yfinance as yf
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 下载数据
df = yf.download(
"AAPL",
start="2015-01-01",
end="2025-01-01",
auto_adjust=True
)
df["ret"] = df["Close"].pct_change().fillna(0)
# 伪造一个信号:一半时间持仓、一半时间空仓
np.random.seed(0)
df["signal"] = (np.random.rand(len(df)) > 0.5).astype(int)
df["signal"] = df["signal"].shift(1).fillna(0) # 避免未来函数
不含成本的策略收益(幻想版本)
df["strategy_ret"] = df["ret"] * df["signal"]
df["equity_nocost"] = (1 + df["strategy_ret"]).cumprod()
这表示你的“幻想回测”效果。
加入现实世界中的成本
假设:
- 每次换仓成本 = 千分之二(0.2%)
- 对于量化来说已经相当乐观了
cost = 0.002 # 0.2%
# 换仓信号:持仓状态变化的次数
df["turnover"] = (df["signal"] != df["signal"].shift(1)).astype(int)
# 每次交易都需要支付成本
df["cost"] = df["turnover"] * cost
# 实际收益 = 策略收益 - 成本
df["strategy_ret_after_cost"] = df["strategy_ret"] - df["cost"]
df["equity_cost"] = (1 + df["strategy_ret_after_cost"]).cumprod()
绘制对比图表
plt.figure(figsize=(12,6))
df["equity_nocost"].plot(label="无成本 (幻想)")
df["equity_cost"].plot(label="包含成本 (现实)")
plt.legend()
plt.title("交易成本对策略的毁灭性影响")
plt.show()
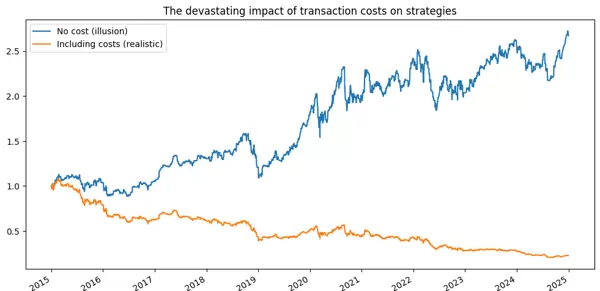
无成本版本:
含成本版本:
- 直接崩溃
- 没有任何统计优势
- 所有收益都被成本吞噬
- 有时甚至比“完全不交易”更糟糕
一句话总结:
高频换手策略 = 为券商工作。
你以为你在赚钱,
实际上你只是在:
专业量化如何处理成本?
真正的量化团队根本不会使用上述“千分之二手续费”模型,因为它过于乐观。
专业机构会模拟:
- 滑点模型(交易冲击、吃单深度、盘口模型)
- 交易量限制(不能超过某只股票流动性的 5%)
- 下单方式(VWAP、TWAP、POV、冰山单)
- 冲击函数(你买入越积极,价格上升越快)
- 交易延迟(从信号到下单再到成交之间的时间差)
- 隔夜风险
如果你的策略不符合流动性限制,在真实的市场中几乎注定失败。
五、让我们将所有因素综合起来:
幻想策略 vs 现实策略
你现在应该了解四种主要的幻想:
这四个错误加在一起,会产生一条“完美的曲线”。
真实的曲线是什么样的?
通常像一张心电图。
如果你将幻想曲线和真实曲线放在一起,你会首次感到恶心:
因为你将意识到:
所有看似“轻松赚钱”的回测,背后都隐藏着某种作弊行为。
量化不是寻找漂亮的曲线,
量化是在排除所有幻想后,
仍能保留一些真实信号。


 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏






