RPA简介与应用场景
1、什么是RPA?
RPA(Robotic Process Automation),即机器人流程自动化,是一种利用软件技术通过模仿人类在图形用户界面的操作,以自动化方式执行预设任务流程的技术。可以将其视为“软件机器人”,能够代替人们完成鼠标点击、键盘输入及数据复制粘贴等工作。
2、为什么选择Python实现RPA?
- 简单易学:Python语言简洁明了,特别适合编程新手。
- 生态丰富:Python具备众多强大的库支持RPA开发,例如Selenium、BeautifulSoup和PyAutoGUI等。
- 高度灵活:Python允许根据具体需求编写自定义逻辑,其灵活性往往超出许多商业RPA工具的范围。
3、典型应用场景
RPA技术广泛应用于各种场景,包括但不限于:
- 自动化地从互联网上搜集信息并生成报告
- 网页表单的自动填充
- 文件的自动下载
- 跨系统间的数据自动输入与同步
下载Python
前往Python官方网站:https://www.python.org/downloads/ 下载适用于您操作系统的最新版本(Windows、macOS或Linux)。建议安装过程中选择 "Add Python to PATH" 选项,以便简化环境变量的设置过程。
使用快捷键Win+R(Windows系统)或直接打开终端(macOS/Linux系统),然后输入以下命令来验证Python是否安装成功:
python --version
或者在某些情况下可能需要使用:
python3 --version
推荐使用PyCharm作为开发环境。
模块的下载和使用
1、安装DrissionPage:
在命令行中执行以下命令以安装DrissionPage模块,这里使用阿里云镜像加速下载:
pip install DrissionPage -i https://mirrors.aliyun.com/pypi/simple/
2、使用实例:
# 导入DrissionPage中的Chromium类
from DrissionPage import Chromium
# 创建一个Chromium浏览器实例
browser = Chromium()
# 从浏览器实例中获得一个可操作的标签页
tab = browser.get_tab()
# 在标签页中导航至指定URL
tab.get("https://www.baidu.com/")
3、代码逐解:
from DrissionPage import Chromium 这行代码的作用是从DrissionPage库中导入Chromium类,用于操控基于Chromium内核的浏览器(如Chrome或Edge)。
browser = Chromium() 此行创建了一个新的浏览器实例,启动了一个实际的浏览器进程,可以通过browser变量管理多个标签页。
tab = browser.get_tab() 浏览器通常包含多个标签页,此方法获取其中一个标签页,通常是当前活动的标签页或是新创建的一个。通过tab变量可以执行具体的网页操作。
tab.get("https://www.baidu.com/") 该行让浏览器加载并显示指定的网页,执行后,浏览器将打开百度首页。
4、运行效果:
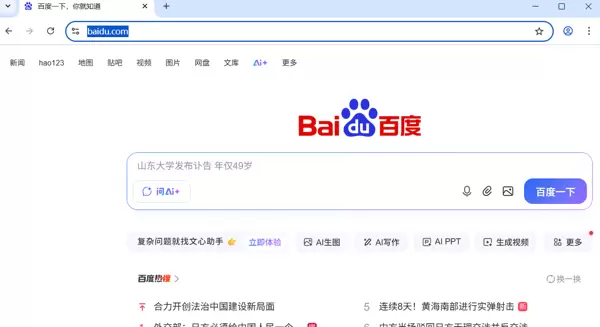
页面的定位与抓取
要定位和抓取网页上的特定内容,首先需要打开浏览器的开发者工具。这可以通过鼠标右键点击页面任意位置选择“检查”或者按下F12键实现。之后,点击开发者工具中的元素选择器图标(通常看起来像一个鼠标指针) ,然后在页面上点击想要抓取的内容。如图所示:
,然后在页面上点击想要抓取的内容。如图所示: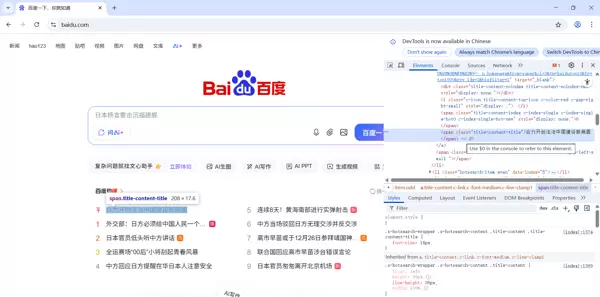
接着,在开发者工具的元素面板中右键点击目标元素,选择“复制”->“复制XPath”。这样就可以得到该元素的XPath路径,用于后续的脚本编写。例如: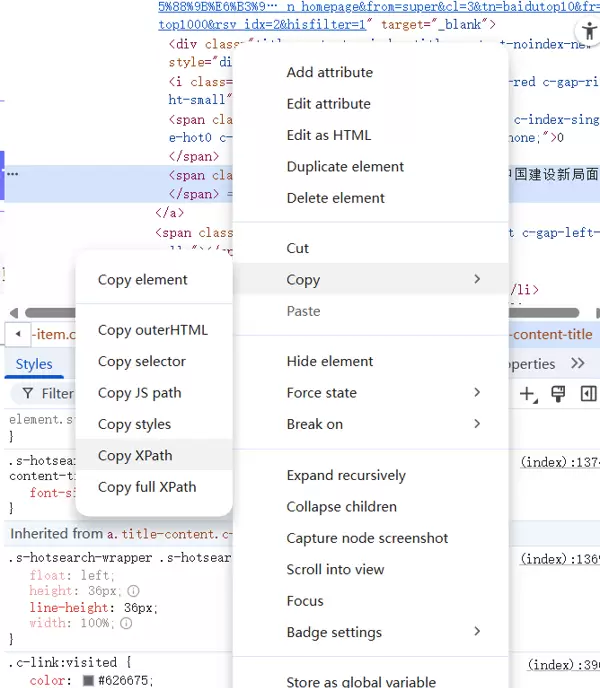
下面是如何使用XPath定位器在标签页中查找指定的网页元素,并打印出其文本内容的示例代码:
# 使用XPath定位器在标签页中查找指定的网页元素
element = tab.ele('xpath://*[@id="hotsearch-content-wrapper"]/li[1]/a/span[2]')
# 获取并打印定位到的元素的文本内容
print(element.text)
运行上述代码后,输出结果如图所示: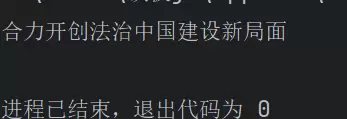
获取多条热搜
要获取前几条热搜的信息,可以通过观察它们的XPath路径找到规律。例如,前三条热搜的XPath分别是:
//[@id="hotsearch-content-wrapper"]/li[1]/a/span[2]
//[@id="hotsearch-content-wrapper"]/li[3]/a/span[2]
//[@id="hotsearch-content-wrapper"]/li[5]/a/span[2]
从这些例子可以看出,所有热搜项都位于
标签下,因此可以总结出所有热搜的XPath为:
//[@id="hotsearch-content-wrapper"]/li/a/span[2]
以下是获取所有热搜的完整代码示例:
从 DrissionPage 库导入 Chromium 模块,并创建一个页面对象。
from DrissionPage import Chromium
page = Chromium()
获取当前打开的标签页,并访问百度首页。
tab = page.get_tab()
tab.get("https://www.baidu.com/")
提取页面上的热点搜索内容。因为这里涉及到多个 XPath 路径,所以需要使用 .eles() 方法来获取一个包含所有匹配元素的列表。
context = tab.eles('xpath://*[@id="hotsearch-content-wrapper"]/li/a/span[2]')
遍历上述列表中的每个元素,并打印出它们的文本内容。
for a in context:
print(a.text)

六、高级功能
1. 表单自动化填写
定位到搜索框并输入“Python RPA教程”。
search_input = tab.ele('xpath://*[@id="kw"]')
search_input.input('Python RPA教程')
接着,找到搜索按钮并触发点击事件。
search_btn = tab.ele('xpath://*[@id="su"]')
search_btn.click()
2. 元素加载等待
首先,确保已经导入了必要的模块,并初始化了一个 Chromium 实例。
from DrissionPage import Chromium
page = Chromium()
然后,获取一个标签页实例,并导航至指定的网页。
tab = page.get_tab()
tab.get('https://example.com')
为了确保页面上的某个元素已加载完成,可以设置一个最大等待时间(例如10秒),在此期间检查该元素是否出现。
element = tab.wait.ele_displayed('xpath://some/element', timeout=10)
此外,也可以通过引入时间模块来实现简单的延时等待。
import time
time.sleep(3) # 延迟3秒


 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏





