科研制图指南:从理论到实践的全面解析
随着生态学与地学研究的深入发展,科研成果的可视化呈现已经成为学术表达和成果转化的重要组成部分。当前,不仅对图像的科学性和规范性有更高的要求(例如,SCI期刊对分辨率、色彩模式、矢量格式的标准),还需要通过高质量的图形来传达复杂的逻辑关系(如空间分布规律、多变量关联、机器学习模型的可解释性)。然而,许多研究者面临着“技术断层”的挑战:一方面,传统的绘图工具难以满足批量处理、个性化设计和跨平台兼容的需求;另一方面,尽管Python绘图生态系统(如Matplotlib、Seaborn、Cartopy等)功能强大,但由于缺乏针对生态学和地学场景的系统教学,研究者常常因为样式不统一、分辨率不达标、空间数据叠加错误等问题而错失成果展示的机会,甚至影响论文的发表。
本指南旨在构建一个从“理论标准-工具实操-场景落地”的完整学习路径:不仅帮助读者理解科研制图的基本规范(如RGB/CMYK转换、矢量图与位图的区别、FDR显著性校正的可视化逻辑),还重点介绍Python在生态学和地学领域的实际应用(如遥感分类结果制图、多Y轴气候水文图、SHAP模型解释图),最终使读者能够将数据转化为符合顶级期刊要求且兼具科学性和美观性的学术图表。
本指南具有以下特点:
- 场景高度适配:所有案例均来自生态学和地学的真实研究,避免了通用教学与特定领域需求之间的脱节。
- 技术体系完整:从基础环境的搭建(如conda环境锁定、Jupyter工作流)到高级技能(如多面板整合、批量化导出、Git版本管理),再到后期处理工具(如Inkscape、Illustrator),涵盖了科研制图的全过程。
- 长效辅助交流:提供直播授课和全套资料,确保学习过程中的持续支持。
第一章:导论与SCI图像标准、环境搭建
1.1 SCI图像规范
讨论了分辨率与DPI(300 vs 600 vs 1200)的要求,RGB与CMYK色彩模式的转换,矢量图(PDF、SVG)与位图(TIFF、PNG)的区别,以及常见的错误示例,如字体不一致、图例遮挡、JPEG压缩等问题。

1.2 Python科研绘图生态
介绍了常用的Python绘图库,包括Matplotlib(底层/可控)、Seaborn(统计范式)、Plotly(交互)、Cartopy(制图)、PyVista(3D)、SHAP(可解释性),以及图像后处理工具Inkscape和Illustrator。强调了质量标准,如项目内的统一配色、字体、网格和标注风格,以及常见的错误,如不同库的默认样式混用、位图编辑代替矢量编辑。
1.3 环境搭建
详细讲解了如何使用conda环境锁定(env.yml)、pip-tools,以及Jupyter+VS Code的工作流。
第二章:Matplotlib高质量图核心
2.1 样式管理与rcParams
讨论了如何统一字体(英文:Arial/Times;中文:思源/苹方)、字号层级、线型与色板,以及科研配色和色盲友好色板的选择。
2.2 单图 & 多子图布局
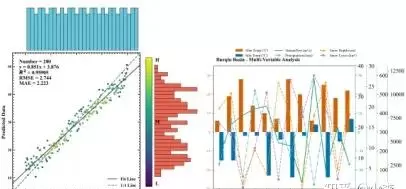
介绍了折线图、散点图、误差带的绘制方法,以及子图对齐、Panel A/B/C自动标注、GridSpec控制比例、共享坐标轴、单位与小数位标准化等技巧。

2.3 输出高分辨率图像
讲解了矢量图的优先使用原则,位图仅用于栅格底图,透明背景PNG,TIFF无压缩,以及保存两种版本(审稿版RGB、发版版CMYK)的方法,还包括嵌入/转曲字体的技巧。
第三章:Seaborn与高级统计可视化
3.1 基础统计图
介绍了箱线图+雨点图/violin图组合、显著性标记、样本量n标注,以及误差呈现的一致性(SD/SE/CI)和对数坐标时的变换说明。

3.2 分布与相关性
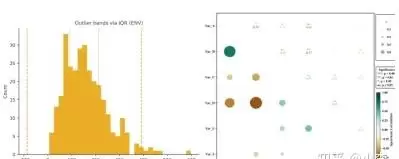
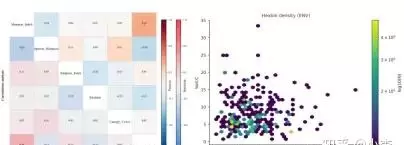
讲解了热图(相关系数+FDR)、jointplot(边缘分布)、置信椭圆的绘制方法,以及相关矩阵排序与聚类、显著性以符号或遮罩表达的技巧。
3.3 分布对比与趋势
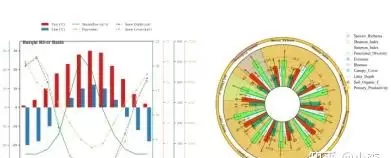
介绍了山脊图展示密度、分组柱状图+热力图组合呈现强度与结构的方法。
第四章:空间数据与生态制图
4.1 空间数据处理
讨论了GeoTIFF与Shapefile的叠加、栅格与矢量的区别、坐标与分辨率对齐的方法,以及先重投影后裁剪、属性表最小化、图层顺序与透明度控制的技巧。
4.2 Cartopy美化
介绍了指北针和比例尺的添加、分区标注的方法。
4.3 高级空间图
讲解了遥感分类结果图(LULC)、多Y轴气候水文图、三维三角网格曲面图与二维等高线的绘制方法。
第五章:高级相关性分析与可视化
5.1 相关性图谱
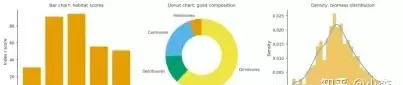
通过案例分析,介绍了方块面积相关性热图、关联气泡图、层次聚类相关热图的绘制方法。
5.2 统计显著性校正
讲解了FDR多重检验校正可视化的应用。
5.3 多维相关性图
介绍了主成分分析的应用案例,包括散点矩阵、分组矩阵、PCA/NMDS结果图的绘制方法。
第六章:机器学习案例分析与SHAP可视化
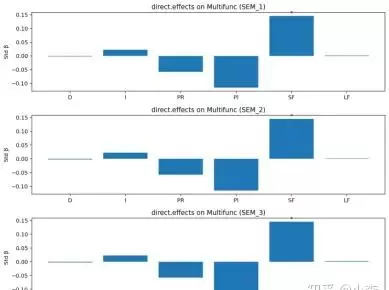
6.1 生态案例应用与分析
讨论了随机森林算法的应用,包括特征选择与参数优化,以及条形特征重要性排序图的绘制方法。
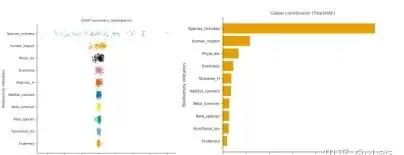
6.2 SHAP可视化
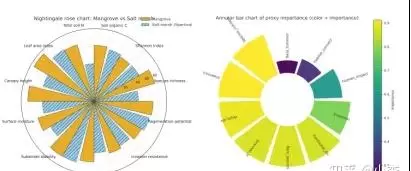
介绍了南丁格尔玫瑰图展示模型权重、头部特征SHAP散点图、SHAP依赖图(单特征)、双特征交互效应SHAP图,以及特征重要性总览与依赖组合图的绘制方法。
6.3 集成分析图
该部分包括了从数据到特征提取,再到模型构建及最终评估的整个流程图。此外,还提供了一个详细的模型对比表,以便于直观地比较不同模型的性能。
第七章:多源融合与多面板整合
7.1 综合布局设计
在这一章节中,我们将探讨如何通过结合流程图、空间图和统计图来实现信息的有效传达。同时,还会介绍多面板分栏排版的方法,以提升视觉效果和信息组织的效率。
7.2 Pillow图像拼接技术
利用Python的Pillow库,可以实现图像的高效合成,并支持矢量图形的输出,确保图像质量的同时,满足各种出版需求。

第八章:批量化与自动化工作流
8.1 自动批量导出功能
本节详细介绍了如何实现文件的自动批量导出,包括批量命名、格式转换等操作,特别是RGB到CMYK的自动转换过程,这对于印刷行业尤为重要。
8.2 版本管理与可复现性
为了确保研究的可复现性和结果的可追溯性,我们推荐使用Git进行科研绘图代码的版本管理。这不仅有助于团队协作,还能有效记录每一次修改的历史,便于后期的审核和调整。


 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏





