经管之家App
让优质教育人人可得
立即打开


1. 使用LlamaIndex快速搭建RAG系统
首先展示代码内容:
《黑神话:悟空》的故事可分为六个章节,名为“火照黑云”、“风起黄昏”、“夜生白露”、“曲度紫鸳”、“日落红尘”和“未竟”,并且拥有两个结局,玩家的选择和经历将影响最终的结局。
每个章节结尾,附有二维和三维的动画过场,展示和探索《黑神话:悟空》中的叙事和主题元素。
游戏的设定融合了中国的文化和自然地标。例如重庆的大足石刻、山西省的小西天、南禅寺、铁佛寺、广胜寺和鹳雀楼等,都在游戏中出现。游戏也融入了佛教和道教的哲学元素。
# 导入所需的核心模块
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.llms.deepseek import DeepSeek
from dotenv import load_dotenv
import os
# 加载环境配置信息
load_dotenv()
# 初始化中文嵌入模型
embed_model = HuggingFaceEmbedding(model_name="BAAI/bge-small-zh")
# 配置并创建DeepSeek语言模型实例
llm = DeepSeek(
model="deepseek-chat",
api_key=os.getenv("DEEP_SEEK_API_KEY")
)
# 读取本地文档数据
documents = SimpleDirectoryReader(input_files=["../90-文档-Data/黑悟空/设定.txt"]).load_data()
# 基于文档内容构建向量索引结构
index = VectorStoreIndex.from_documents(
documents,
embed_model=embed_model
)
# 将索引与大模型结合,生成可查询的问答引擎
query_engine = index.as_query_engine(llm=llm)
# 执行实际问题查询
print(query_engine.query("黑神话悟有多少章节"))
运行结果如下:
《黑神话:悟空》共有六个章节。该段代码实现了一个基于文档内容的问答系统,主要流程包括:
简而言之,这是一个让AI根据提供的《黑神话:悟空》设定资料自动回答相关问题的技术示例。
2. 利用LangChain实现本地化问答功能
LangChain 提供了多种组件来构建基于本地或网络文档的问答系统。以下是其典型使用方式:
# 第一步:获取网页文档内容
import os
from dotenv import load_dotenv
load_dotenv() # 加载API密钥等配置
from langchain_community.document_loaders import WebBaseLoader # 需安装 langchain-community
loader = WebBaseLoader(
web_paths=("https://zh.wikipedia.org/wiki/黑神话:悟空",)
)
docs = loader.load()
# 第二步:对文档进行分块处理
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
all_splits = text_splitter.split_documents(docs)
# 第三步:配置文本嵌入服务
from langchain_huggingface import HuggingFaceEmbeddings # 需安装 langchain-huggingface
embeddings = HuggingFaceEmbeddings(
model_name="BAAI/bge-small-zh-v1.5",
model_kwargs={'device': 'cpu'},
encode_kwargs={'normalize_embeddings': True}
)
# 第四步:创建内存中的向量数据库
from langchain_core.vectorstores import InMemoryVectorStore
vector_store = InMemoryVectorStore(embeddings)
vector_store.add_documents(all_splits)
# 第五步:定义用户提出的问题
question = "黑悟空有哪些游戏场景?"
# 第六步:在向量库中检索相关片段,并准备上下文以供后续回答使用
上述流程展示了如何借助 LangChain 框架完成从网页抓取、文本分割、向量化存储到语义检索的全过程,为后续结合大模型生成答案打下基础。
# 1. 加载文档
import os
from dotenv import load_dotenv
# 加载环境变量
load_dotenv()
from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader(
web_paths=("https://zh.wikipedia.org/wiki/黑神话:悟空",)
)
docs = loader.load()
# 2. 分割文档
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
all_splits = text_splitter.split_documents(docs)
# 3. 设置嵌入模型
from langchain_huggingface import HuggingFaceEmbeddings
embeddings = HuggingFaceEmbeddings(
model_name="BAAI/bge-small-zh-v1.5",
model_kwargs={'device': 'cpu'},
encode_kwargs={'normalize_embeddings': True}
)
# 4. 创建向量存储
from langchain_core.vectorstores import InMemoryVectorStore
vectorstore = InMemoryVectorStore(embeddings)
vectorstore.add_documents(all_splits)
# 5. 创建检索器
retriever = vectorstore.as_retriever(search_kwargs={"k": 3})
网页抓数据→分割成小块→转成向量存储→提问时找相关片段→让大模型基于片段回答整个流程是先从
# 6. 创建提示模板
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_template("""
基于以下上下文,回答问题。如果上下文中没有相关信息,
请说"我无法从提供的上下文中找到相关信息"。
上下文: {context}
问题: {question}
回答:""")
# 7. 设置语言模型和输出解析器
# from langchain_ollama import ChatOllama
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
3. 基于 LCEL 协议实现RAG
LCEL优势在于:

# 7. 构建提示模板(续)
prompt = ChatPromptTemplate.from_template("""
基于以下上下文,回答问题。如果上下文中没有相关信息,
请说"我无法从提供的上下文中找到相关信息"。
上下文: {context}
问题: {question}
回答:"""
)
# 8. 使用大语言模型生成答案
from langchain_deepseek import ChatDeepSeek # pip install langchain-deepseek
llm = ChatDeepSeek(
model="deepseek-chat", # DeepSeek API 支持的模型名称
temperature=0.7, # 控制输出的随机性
max_tokens=2048, # 最大输出长度
api_key=os.getenv("DEEPSEEK_API_KEY") # 从环境变量加载API key
)
answer = llm.invoke(prompt.format(question=question, context=docs_content))
print(answer)
# 使用 DeepSeek 模型进行语言处理
from langchain_deepseek import ChatDeepSeek
# 初始化 LLM 模型,使用环境变量中的 API 密钥
llm = ChatDeepSeek(model="deepseek-chat", api_key=os.getenv("DEEPSEEK_API_KEY"))
# 8. 构建基于 LCEL 的处理链
# 利用类似 Unix 管道的数据流机制,将多个处理步骤串联成一个完整流程
chain = (
{
# context 键:通过检索器获取文档列表,并将其内容合并为一段上下文文本
"context": retriever | (lambda docs: "\n\n".join(doc.page_content for doc in docs)),
# question 键:使用 RunnablePassthrough 直接传递原始问题字符串
"question": RunnablePassthrough()
}
# 将包含上下文和问题的字典传入提示模板
| prompt
# 调用大模型对格式化后的提示进行推理
| llm
# 最终通过字符串解析器提取纯文本回答
| StrOutputParser()
)
# 验证链中各阶段的输入与输出结果
question = "测试问题"
# 第一步:执行检索操作
retriever_output = retriever.invoke(question)
print("检索器输出:", retriever_output)
# 第二步:整合所有检索到的文档内容
context = "\n\n".join(doc.page_content for doc in retriever_output)
print("合并文档输出:", context)
# 第三步:构造最终发送给模型的提示语
prompt_output = prompt.invoke({"context": context, "question": question})
print("提示模板输出:", prompt_output)
# 第四步:调用语言模型生成响应
llm_output = llm.invoke(prompt_output)
print("LLM输出:", llm_output)
# 第五步:解析模型返回的结果为可读文本
final_output = StrOutputParser().invoke(llm_output)
print("最终输出:", final_output)
# 9. 实际查询执行
question = "介绍一下黑悟空"
response = chain.invoke(question) # 可替换为异步方式调用
借助 LCEL 协议,整个处理流程——包括“检索上下文、构建提示词、调用语言模型、解析输出”——被封装成一条可直接调用的链式结构。当调用 chain.invoke(question) 时,数据会按照预定义的流水线自动流动,最终返回基于维基百科内容的答案。
# 1. 文档加载
from langchain_community.document_loaders import WebBaseLoader
import os
# 从指定网页抓取内容
loader = WebBaseLoader(
web_paths=("https://zh.wikipedia.org/wiki/黑神话:悟空",)
)
docs = loader.load()
# 2. 对文档进行分块处理
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 设置每个文本块大小为1000字符,重叠部分为200字符
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
all_splits = text_splitter.split_documents(docs)
# 3. 配置嵌入模型
from langchain_huggingface import HuggingFaceEmbeddings
embeddings = HuggingFaceEmbeddings(
model_name="BAAI/bge-small-zh-v1.5",
model_kwargs={'device': 'cpu'}, # 使用 CPU 进行计算
encode_kwargs={'normalize_embeddings': True} # 归一化向量表示
)
# 4. 创建向量数据库存储
from langchain_deepseek import ChatDeepSeek
from langchain_core.vectorstores import InMemoryVectorStore
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.documents import Document
from typing import List
from typing_extensions import TypedDict
from dotenv import load_dotenv
import os
# 初始化向量存储并添加文档片段
vector_store = InMemoryVectorStore(embeddings)
vector_store.add_documents(all_splits)
# 构建用于RAG的提示模板
prompt = ChatPromptTemplate.from_template(
"""根据以下上下文回答问题。
上下文: {context}
问题: {question}"""
)
# 定义应用的状态结构
class State(TypedDict):
question: str
context: List[Document]
answer: str
# 实现检索功能:根据用户问题查找相关文档
def retrieve(state: State):
retrieved_docs = vector_store.similarity_search(state["question"])
return {"context": retrieved_docs}
# 生成回答步骤:结合上下文与问题,调用大模型生成答案
def generate(state: State):
load_dotenv()
# 确保已配置 DeepSeek API 密钥
if not os.environ.get("DEEPSEEK_API_KEY"):
raise ValueError("请设置环境变量 DEEPSEEK_API_KEY,例如: os.environ['DEEPSEEK_API_KEY'] = 'your-api-key'")
llm = ChatDeepSeek(model="deepseek-chat", api_key=os.getenv("DEEPSEEK_API_KEY"))
# 将检索到的文档内容拼接为字符串
docs_content = "\n\n".join(doc.page_content for doc in state["context"])
messages = prompt.invoke({"question": state["question"], "context": docs_content})
response = llm.invoke(messages)
return {"answer": response.content}
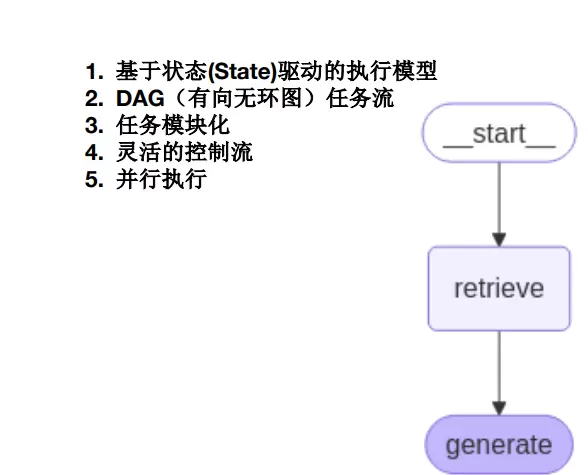
# 使用 LangGraph 构建有状态的工作流图
from langgraph.graph import START, StateGraph # 需提前安装: pip install langgraph
graph = (
StateGraph(State)
.add_sequence([retrieve, generate])
.add_edge(START, "retrieve")
.compile()
)
# 执行实际查询示例
# 注意:运行前必须确保已正确设置 DEEPSEEK_API_KEY 环境变量
# os.environ["DEEPSEEK_API_KEY"] = "your-deepseek-api-key"
question = "黑悉空有哪些游戱场景?"
response = graph.invoke({"question": question}) # type: ignore
print(f"\n问题: {question}")
print(f"答案: {response['answer']}")
 通过将 RAG 流程拆解为“检索”与“生成”两个独立阶段,并借助 State 对数据进行统一管理,langgraph 实现了高度结构化的工作流设计。其核心机制是:首先从网页文档中提取与用户提问相关的信息片段,随后由大模型基于这些检索结果生成最终回答,从而显著提升输出内容的准确性与上下文相关性。相较于传统的链式调用方式,langgraph 提供了更清晰的流程控制能力,并具备良好的可扩展性——例如可以灵活加入多轮检索、内容审核或其他处理节点。
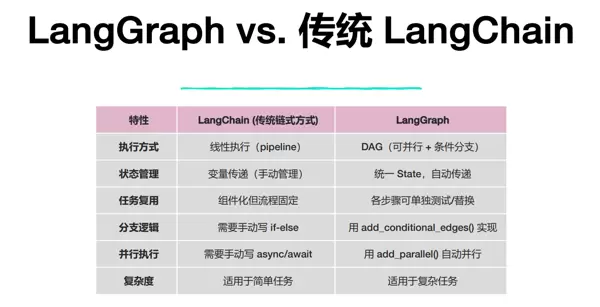
以下是 langchain 与 langgraph 的对比图示:
通过将 RAG 流程拆解为“检索”与“生成”两个独立阶段,并借助 State 对数据进行统一管理,langgraph 实现了高度结构化的工作流设计。其核心机制是:首先从网页文档中提取与用户提问相关的信息片段,随后由大模型基于这些检索结果生成最终回答,从而显著提升输出内容的准确性与上下文相关性。相较于传统的链式调用方式,langgraph 提供了更清晰的流程控制能力,并具备良好的可扩展性——例如可以灵活加入多轮检索、内容审核或其他处理节点。
以下是 langchain 与 langgraph 的对比图示:
首先加载必要的环境变量并构建文档集合,用于后续的语义检索:
import os
from dotenv import load_dotenv
# 加载环境变量
load_dotenv()
docs = [
"黑神话悟空的战斗如同武侠小说活过来一般,当金箍棒与妖魔碰撞时,火星四溅,招式行云流水。悟空可随心切换狂猛或灵动的战斗风格,一棒横扫千军,或是腾挪如蝴蝶戏花。",
"72变神通不只是变化形态,更是开启新世界的钥匙。化身飞鼠可以潜入妖魔巢穴打探军情,变作金鱼能够探索深海遗迹的秘密,每一种变化都是一段独特的冒险。",
"每场BOSS战都是一场惊心动魄的较量。或是与身躯庞大的九头蟒激战于瀑布之巅,或是在雷电交织的云海中与雷公电母比拼法术,招招险象环生。",
"驾着筋斗云翱翔在这片神话世界,瑰丽的场景令人屏息。云雾缭绕的仙山若隐若现,古老的妖兽巢穴中藏着千年宝物,月光下的古寺钟声回荡在山谷。",
"这不是你熟悉的西游记。当悟空踏上寻找身世之谜的旅程,他将遇见各路神仙妖魔。有的是旧识,如同样桀骜不驯的哪吒;有的是劲敌,如手持三尖两刃刀的二郎神。",
"作为齐天大圣,悟空的神通不止于金箍棒。火眼金睛可洞察妖魔真身,一个筋斗便是十万八千里。而这些能力还可以通过收集天外陨铁、悟道石等材料来强化升级。",
"世界的每个角落都藏着故事。你可能在山洞中发现上古大能的遗迹,云端天宫里寻得昔日天兵的宝库,或是在凡间集市偶遇卖人参果的狐妖。",
"故事发生在大唐之前的蛮荒世界,那时天庭还未定鼎三界,各路妖王割据称雄。这是一个神魔混战、群雄逐鹿的动荡年代,也是悟空寻找真相的起点。",
"游戏的音乐如同一首跨越千年的史诗。古琴与管弦交织出战斗的激昂,笛萧与木鱼谱写禅意空灵。而当悟空踏入重要场景时,古风配乐更是让人仿佛穿越回那个神话的年代。"
]使用 Sentence-BERT 类型的模型对文档进行向量化处理,便于后续语义匹配:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
doc_embeddings = model.encode(docs)
print(f"文档向量维度: {doc_embeddings.shape}")采用 FAISS 构建本地向量数据库,支持高效的近似最近邻搜索:
import faiss # pip install faiss-cpu
import numpy as np
dimension = doc_embeddings.shape[1]
index = faiss.IndexFlatL2(dimension)
index.add(doc_embeddings.astype('float32'))
print(f"向量数据库中的文档数量: {index.ntotal}")针对用户提出的问题,先编码成查询向量,再从向量库中找出最相关的前三条文档:
question = "黑神话悟空的战斗系统有什么特点?"
query_embedding = model.encode([question])[0]
distances, indices = index.search(
np.array([query_embedding]).astype('float32'),
k=3
)
context = [docs[idx] for idx in indices[0]]
print("\n检索到的相关文档:")
for i, doc in enumerate(context, 1):
print(f"[{i}] {doc}")将检索出的内容整合进提示模板中,明确要求模型依据所提供信息作答,并标注出处编号:
prompt = f"""根据以下参考信息回答问题,并给出信息源编号。
如果无法从参考信息中找到答案,请说明无法回答。
参考信息:
{chr(10).join(f"[{i+1}] {doc}" for i, doc in enumerate(context))}
问题: {question}
答案:"""调用 DeepSeek 的 API 接口完成最终的回答生成任务:
from openai import OpenAI
client = OpenAI(
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com/v1"
)生成的答案: {response.choices[0].message.content}
检索阶段:将问题转化为向量形式,在向量数据库中搜索相似的文档,并提取出相关的上下文信息。
生成阶段:把提取到的上下文与原始问题整合为一条完整的提示词(prompt),交由大模型(如DeepSeek)根据该提示生成最终答案。
文档处理流程:首先准备原始文档,随后将其转换为向量表示,最后存入向量数据库(例如Faiss)中以供后续检索使用。
参考链接:极客时间RAG训练营

 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏




