传统知识库与AI知识库的对比
传统的知识库往往只是“文档堆积”的集合,用户需要手动查找和筛选信息。例如,某金融机构的客服人员曾为了查询一条利率政策,在超过200页的文档中耗费了15分钟才找到相关内容。而AI知识库则通过智能化手段提升了可用性,使用户能够快速、准确地获取所需信息。高质量的数据是构建AI知识库的基础,只有结构清晰、内容准确的数据,才能被大模型高效理解与调用。
什么是AI知识库?从使用者视角出发
我们不妨从不同角色的使用场景来理解AI知识库的实际价值。
普通员工眼中的公司AI知识库
- 完善的知识库:涵盖公司介绍、产品说明、技术文档、规章制度等,支持员工随时检索。
- AI+知识库:在已有知识基础上,结合上下文语境,AI能提供更精准、符合情境的回答。
- AI Agent:基于知识库和业务流程,AI可主动完成特定任务,如自动填写工单、生成报告等。
这一路径看似理想,但现实中90%的企业连第一步都难以达成——要么缺乏文档,要么文档残缺不全,即便存在也形同虚设,无人查阅。实际上,AI知识库是企业数字化转型的延续,若没有扎实的数据基础,仅靠引入AI技术实现飞跃是不可能的。
业务团队的知识需求
对于一线业务人员而言,有效的知识支持应包括:
- 公司政策与市场动态
- 项目进展与业绩完成情况
- 各类操作手册:问题解决方案、客户沟通话术等
- 标准化流程(SOP)及AI驱动的数据流转机制
- 战略方向指引与执行反馈
这些内容构成了支撑日常运营的核心知识体系。
CEO层面的知识管理
从高层管理者的角度看,知识库不仅仅是信息存储工具,更是决策辅助系统:
- 客观信息:员工状态、项目进度、资源配置、组织氛围等。
- 决策支持:选题建议、人才梯队建设、风险应急机制、企业迭代策略,甚至包含对CEO个人成长的支持。
CEO关注的是资源投入的有效性:钱花在哪里?是否产生价值?如何提升效率?通过对数据的重新组织与可视化呈现,AI知识库可以帮助领导者直观看到资源流向,识别浪费环节,并优化投入结构。
小结:AI知识库的本质是Agent
从以上三个视角可以看出,真正有价值的并非静态的知识存储,而是基于知识的智能行动能力。因此,所谓的“AI知识库”本质上更接近于AI Agent——我们追求的不只是获取知识,更是利用知识+AI来协助完成任务、推动决策、提升效率。
AI知识库的核心技术:RAG
AI知识库项目属于AI工程的重要组成部分,而RAG(Retrieval Augmented Generation,检索增强生成)则是其核心技术之一。
RAG是一种融合信息检索与文本生成的技术框架,能够在生成回答时动态引用外部知识源,从而弥补大模型在特定领域或实时信息上的不足。
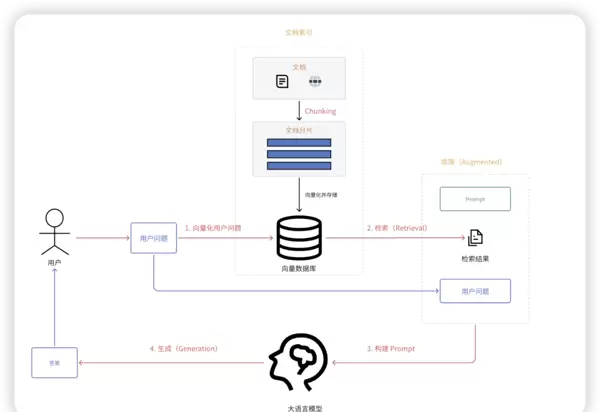
RAG解决的关键问题
- 缓解模型上下文长度限制:早期模型上下文窗口较小,需将知识切片存入向量数据库,通过RAG实现高效检索。尽管当前模型上下文已大幅扩展,RAG仍具备应用价值,未来可能演进而非被淘汰。
- 提高响应准确性:借助外部知识库补充专业或私有信息,减少模型“凭空猜测”的概率。
- 提供更新鲜的信息:连接实时数据源,确保输出内容紧跟最新变化。
- 降低成本:相比频繁重训练大模型,RAG通过外挂知识库的方式更具成本优势。
- 增强可解释性:生成结果可附带引用来源,提升可信度与审计能力。
- 减少幻觉现象:基于真实知识生成回答,显著降低虚构内容的风险。
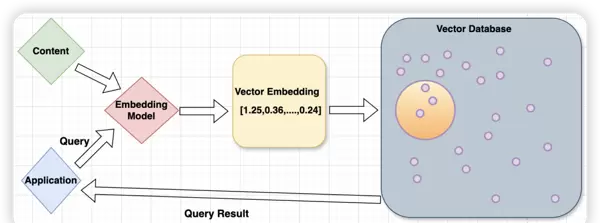
向量数据库的作用与本质
向量数据库用于存储、索引、查询和检索高维向量数据,特别适用于处理非结构化数据,如文本、图像、音频等。它能够实现传统数据库难以完成的语义相似性搜索和高级分析功能。
从本质上看,向量数据库其实相当于一个“小型模型”,其语义理解能力虽不及大模型,但在特定场景下具有明显优势——主要体现在成本控制和响应速度上。在单一垂直领域,采用微调的小模型替代向量库进行语义匹配,往往能取得更优效果。
经典RAG技术流程
其工作流程如下图所示:
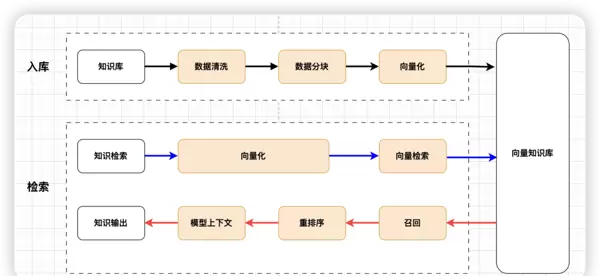
知识入库流程
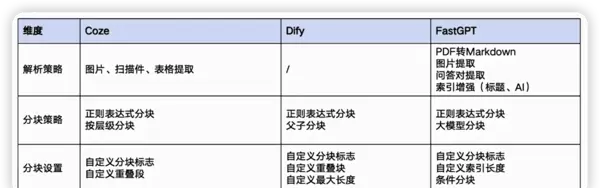
Step 1:数据清洗
目的:去除无关符号、广告内容及干扰信息,保留结构清晰的文档主体,便于后续分块处理。推荐使用Markdown等结构友好格式进行转换。
常用方法:
- 工程方式:编写正则表达式脚本自动化处理。
- AI辅助:利用大模型自动识别并转换非标准格式内容。
Step 2:数据分块
基本原则:
- 每个片段应为完整语义单元
- 长度适中,避免过长或过短
- 保持内容相关性和上下文连贯性
常见分块策略:
| 分块策略 |
说明 |
| 匹配表达式分块 |
依据特定符号(如换行符、句号、##标题标记)进行切割 |
| NLP分块 |
借助NLTK、spaCy等自然语言处理工具识别句子与段落边界 |
| 大模型分块 |
基于语义理解对文档进行智能切分,适合复杂文本结构 |
通常情况下,若前期清洗得当,直接使用符号分块即可满足大部分需求。
数据分块中的挑战与应对
| 难点 |
说明 |
解决思路 |
| 图文混排文档 |
如PPT、PDF中常含架构图、示意图等,若简单过滤图片会导致文字语义断裂;单独向量化图片则检索效果差。 |
对图片进行OCR识别或视觉理解,生成摘要文本,将其与原文一同存储和检索。 |
| 数据版本问题 |
同一文件存在多个版本,导致知识冲突或重复。 |
建立明确的知识更新机制与版本控制系统。 |
| 数据歧义 |
相同术语在不同文档中含义不同,易引发误解。 |
引入上下文标注、领域分类或元数据标签以区分语义。 |
构建高效的AI知识库体系,关键在于合理划分知识领域。应将不同专业方向的内容分别存储于独立的知识库中,以提升管理效率与检索精度。
针对复杂问题的检索需求,往往需要跨越多个知识库文档进行信息提取。为此,可采用分步检索策略,并结合GraphRAG技术实现更深层次的知识关联挖掘。
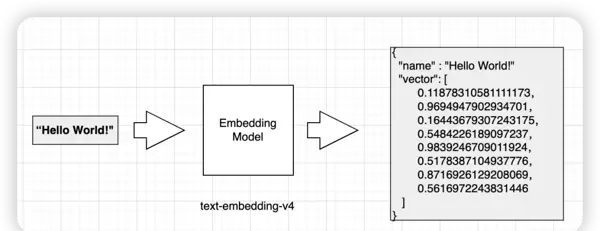
向量化处理阶段
在知识入库流程中,向量化是核心环节之一。该过程主要包括密集向量和稀疏向量两种方式:
密集向量表示:通过计算向量之间的距离来衡量语义相似度。语义越接近的内容,其向量空间中的距离也越小。
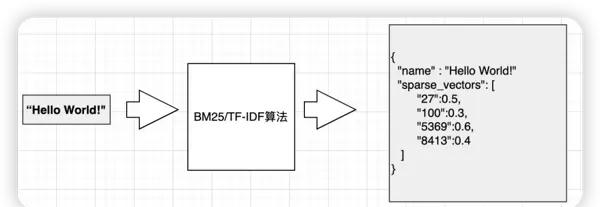
稀疏向量(用于全文检索):依据词语在语料库中的出现频率及其重要性赋予权重。如下图所示,大部分维度值为0,图示中已省略零值部分。
知识检索优化流程
Step1:检索前优化
为提升检索效果,需对原始查询内容进行改写与关键词优化。
问题重写:将用户提出的模糊或宽泛提问转化为具体、清晰的问题,便于后续精准匹配。
示例格式如下:
请将以下用户的原始提问改写为一个更加具体和清晰的问题,以便更好地进行检索和生成:用户提问:{{原始提问}}
假设用户在一个对话系统中先前提到: 我最近在学习Python编程。然后用户接着问: 我该如何开始? 在这个上下文中,系统可以将查询改写为: 我应该从哪些Python学习资源或项目开始?
Multi-Query扩展:将单一查询拆解为多个相关问题,从而拓宽检索范围,增强上下文覆盖能力。
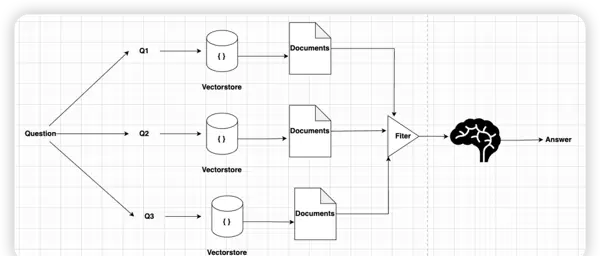
子问题分解(Sub-question):面对复杂问题时,将其拆解为若干个简单、可独立解答的子问题,逐个击破。
问题:Coze和Dify的区别?答案1:Coze基本介绍 -- 检索Coze知识库答案2:Dify基本介绍 -- 检索Dify知识库最终答案:结合答案1和答案2整理出二者的区别
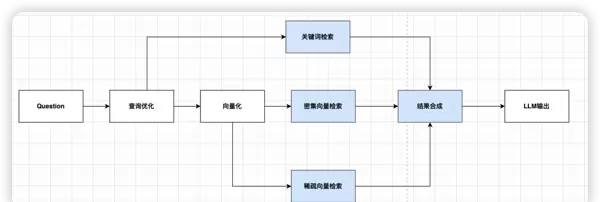
Step2:知识召回
采用多路召回机制,从不同路径并行获取候选结果,最终整合输出最优集合。
RRF倒数排序融合算法:在多路召回过程中,仅依赖各通道返回结果的排名顺序进行加权融合,有效提升整体排序质量。
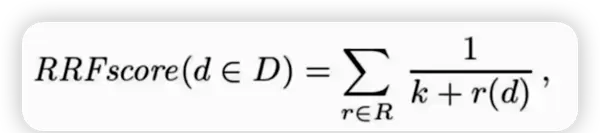
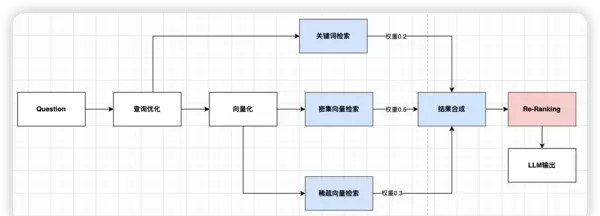
Step3:检索后优化——重排序
重排序是对初步召回结果进行精细化筛选的过程,通常借助ReRank模型完成“优中选优”,确保最相关的结果排在前列。
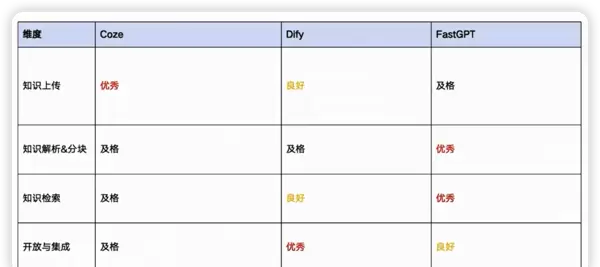
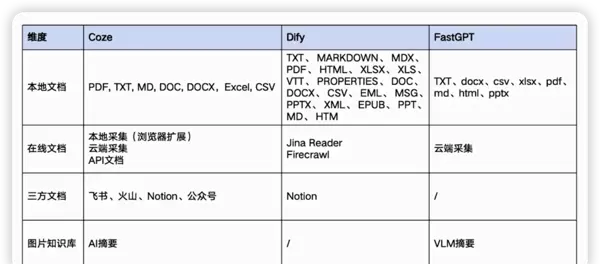
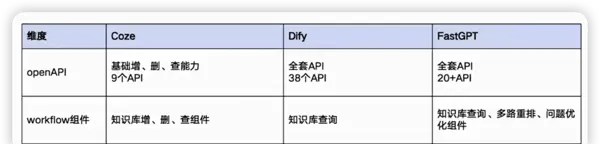
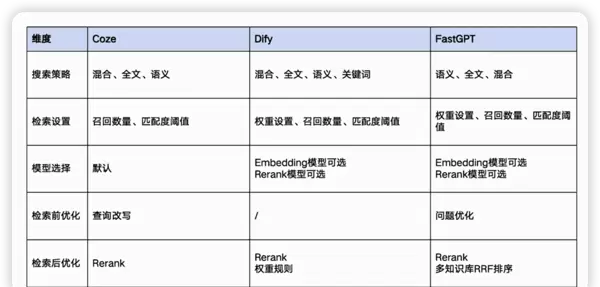
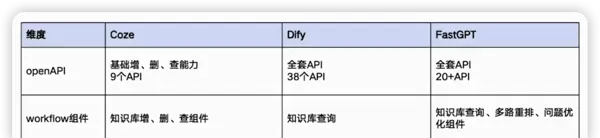
主流平台对知识库的支持现状
当前各大AI平台在知识库功能模块上已具备较为完善的支撑体系,涵盖以下几个方面:
- 知识上传:支持多种格式文件导入
- 知识解析与分块:自动识别结构化与非结构化内容,并进行合理切片
- 知识库集成:支持跨系统对接与统一调用接口
- 知识检索能力:提供基础及高级检索功能
RAG典型流程回顾
数据入库流程:数据清洗 → 数据分块 → 向量化处理 → 存入数据库
检索执行流程:用户问题向量化 → 向量检索 → 多路召回 → 结果重排序 → 基于上下文生成回答
总结
本次分享主要围绕AI知识库建设展开,重点强调了以下几点:
- 知识库项目是AI系统的核心基础设施
- 高质量数据是构建优秀知识库的最大挑战
- 所有知识库的最终目标并非仅仅存储知识,而是服务于智能Agent的决策与交互
未来将继续深入探讨实际应用案例,敬请期待。
知识库构建关键技术点图示汇总










你是一个AI语育模型助手。 你的任务是针对给定的用户问题生成五个不同版本的表述,以便从向量数据库中检索相关文档。 通过对用户问题生成多种角度的表述,你的目标是帮助用户克服基于距离的相似性搜索的一些局限性。 将这些替代问题用换行符分隔开。 原始问题:{question}


 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏





