经管之家App
让优质教育人人可得
立即打开


作为一名刚完成国企CMS项目交付的Java资深开发者,我深知大家最需要的是什么:一套真正“开箱即用”且能让甲方客户点头满意的文档处理方案。今天就分享我私藏已久的全能文档导入插件,支持Word、PPT、Excel、PDF等多种格式,仅需680元即可买断源码,助你在团队中轻松树立“技术担当”的形象。
本模块采用Vue3兼容架构对UEditor进行功能增强,核心为文档导入入口的可视化集成。
/ueditor/plugins/doc_magic/
├─ dialog.html # 多功能操作面板
├─ doc_magic.js # 核心插件逻辑
└─ style.css # 样式文件
// 注册自定义UI组件(兼容Vue3环境)
UE.registerUI('doc_magic', function(editor, uiName) {
// 创建多功能操作按钮(采用新疆棉田绿主题配色)
const btn = new UE.ui.Button({
name: uiName,
title: '文档神器(粘贴/导入)',
cssRules: 'background: #228B22; color: white;',
onclick: () => showMagicDialog(editor)
});
// 弹出文档处理对话框(适配现代前端框架)
function showMagicDialog(editor) {
const dialog = new UE.ui.Dialog({
iframeUrl: `${editor.options.serverUrl}/plugins/doc_magic/dialog.html`,
editor: editor,
title: '文档导入神器',
width: 900,
height: 650,
buttons: [{
className: 'edui-okbutton',
label: '开始魔法',
onclick: () => {
const content = window.magicContent;
editor.execCommand('insertHtml', content);
dialog.close();
}
}]
});
dialog.render();
dialog.open();
}
return btn;
});
提供图形化操作面板,支持拖拽上传、格式预览与内容提取设置。
文档导入神器
???? 粘贴Word
???? 导入文档
???? 公众号
提取内容
抓取内容
const { createApp } = Vue;
createApp({
data() {
return {
activeTab: 'paste',
pasteContent: '',
pastePreview: '',
wechatUrl: '',
wechatPreview: '',
filePreview: ''
};
},
methods: {
async processPaste() {
// 调用后端处理粘贴内容
const res = await fetch('/api/doc/process-paste', {
method: 'POST',
headers: {'Content-Type': 'application/json'},
body: JSON.stringify({ content: this.pasteContent })
});
const data = await res.json();
this.pastePreview = data.content;
},
async handleFileUpload(e) {
const file = e.target.files[0];
const formData = new FormData();
formData.append('file', file);
// 调用后端上传文件
const res = await fetch('/api/doc/upload-file', {
method: 'POST',
body: formData
});
const data = await res.json();
this.filePreview = data.content;
},
async fetchWechatContent() {
// 调用后端抓取公众号内容
const res = await fetch('/api/doc/fetch-wechat', {
method: 'POST',
headers: {'Content-Type': 'application/json'},
body: JSON.stringify({ url: this.wechatUrl })
});
const data = await res.json();
this.wechatPreview = data.content;
}
}
}).mount('#app');基于开源生态构建,无第三方商业依赖,确保长期可维护性。
通过环境变量读取敏感配置信息,保障系统安全性。
public class OssUtil {
private static final String ENDPOINT = System.getenv("OSS_ENDPOINT");
private static final String ACCESS_KEY = System.getenv("OSS_ACCESS_KEY");
private static final String SECRET = System.getenv("OSS_SECRET");
private static final String BUCKET = System.getenv("OSS_BUCKET");
private static OSSClient ossClient;
static {
ossClient = new OSSClientBuilder().build(ENDPOINT, ACCESS_KEY, SECRET);
}
/**
* 文件上传至OSS
* @param filePath 本地路径
* @param fileName 原始文件名
* @return 外链访问地址
*/
public static String uploadToOSS(String filePath, String fileName) throws Exception {
String objectKey = "docs/" + UUID.randomUUID() + "." + fileName.split("\\.")[1];
ossClient.putObject(BUCKET, objectKey, new File(filePath));
return "https://" + BUCKET + "." + ENDPOINT + "/" + objectKey;
}
}
整合Apache POI与PDFBox两大开源库,实现零成本文档内容抽取。
public class DocProcessor {
// 支持富文本粘贴场景下的Word内容处理(含内嵌图片资源)
public String processPastedWord(String html) throws Exception { // 第一步:清除与Word相关的特殊标签 String cleanHtml = cleanWordTags(html); // 第二步:提取内容中的图片并上传至服务器 cleanHtml = uploadImages(cleanHtml); // 第三步:将Latex数学公式转换为MathML格式 cleanHtml = convertLatexToMathML(cleanHtml); return cleanHtml; } public String parseWord(File file) throws Exception { XWPFDocument doc = new XWPFDocument(new FileInputStream(file)); StringBuilder html = new StringBuilder(""); // 遍历文档中的所有段落 for (XWPFParagraph para : doc.getParagraphs()) { html.append("<p>").append(parseParagraph(para)).append("</p>"); } // 处理文档中包含的表格元素 for (XWPFTable table : doc.getTables()) { html.append("<table>"); for (XWPFTableRow row : table.getRows()) { html.append("<tr>"); for (XWPFTableCell cell : row.getTableCells()) { html.append("<td>"); html.append(parseCell(cell)); html.append("</td>"); } html.append("</tr>"); } html.append("</table>"); } return html.toString(); } // 辅助函数:移除由Word生成的冗余HTML标签和样式类 private String cleanWordTags(String html) { return html .replaceAll("<!--.*?-->", "") .replaceAll("class=\\"Mso[^\\"]*\\"", "") .replaceAll("<\\\\?[a-zA-Z]+:[^>]*>", ""); } // 辅助函数:识别base64编码的图片,上传至OSS并替换为网络链接 private String uploadImages(String html) throws Exception { Pattern pattern = Pattern.compile( "<img[^>]+src=\\"data:image/(png|jpg);base64,([^\\"]*)"); Matcher matcher = pattern.matcher(html); StringBuffer sb = new StringBuffer(); while (matcher.find()) { String base64 = matcher.group(2); byte[] bytes = Base64.getDecoder().decode(base64); File tempFile = File.createTempFile("img_", ".png"); Files.write(tempFile.toPath(), bytes); // 上传到阿里云OSS获取外链地址 String ossUrl = OssUtil.uploadToOSS( tempFile.getPath(), "paste_img_" + System.currentTimeMillis() + ".png" ); matcher.appendReplacement(sb, "<img src=\\"" + ossUrl + "\\">"); tempFile.delete(); } matcher.appendTail(sb); return sb.toString(); } // 辅助方法:使用外部服务将Latex表达式转为MathML以支持网页渲染 private String convertLatexToMathML(String html) { return html.replaceAll("\\$(.*?)\\$", match -> { String latex = match.group(1); try { // 实际项目中应调用MathJax或类似API完成转换 return "<mathml>" + latex + "</mathml>"; } catch (Exception e) { // 若转换失败,则保留原始写法 return match.group(0); } }); }
1. 环境准备
推荐运行环境:阿里云ECS实例,操作系统为CentOS 7及以上版本。
<%@ page import="com.example.DocProcessor" %>
<%@ page import="com.example.OssUtil" %>
<%@ page import="org.apache.poi.xwpf.extractor.XWPFWordExtractor" %>
<%@ page import="org.apache.pdfbox.pdmodel.PDDocument" %>
<%@ page import="java.io.*" %>
<%
response.setContentType("application/json;charset=UTF-8");
String action = request.getParameter("action");
if ("processPaste".equals(action)) {
String content = request.getParameter("content");
DocProcessor processor = new DocProcessor();
String result = processor.processPastedWord(content);
out.print("{\"content\":\"" + result + "\"}");
} else if ("uploadFile".equals(action)) {
Part filePart = request.getPart("file");
String fileName = getFileName(filePart);
File tempFile = File.createTempFile("upload_", "." + fileName.split("\\.")[1]);
filePart.write(tempFile.getPath());
DocProcessor processor = new DocProcessor();
String html = "";
switch (fileName.split("\\.")[1].toLowerCase()) {
case "docx":
html = processor.parseWord(tempFile);
break;
case "pdf":
html = parsePdf(tempFile);
break;
// 其他格式类似...
}
out.print("{\"content\":\"" + html + "\"}");
} else if ("fetchWechat".equals(action)) {
String url = request.getParameter("url");
String html = fetchWechatContent(url);
out.print("{\"content\":\"" + html + "\"}");
}
%>
<%!
// 提取文件名工具方法
private String getFileName(Part part) {
String contentDisp = part.getHeader("content-disposition");
for (String cd : contentDisp.split(";")) {
if (cd.trim().startsWith("filename")) {
return cd.substring(cd.indexOf('=') + 1).trim().replace("\"", "");
}
}
return "unknown";
}
// 解析PDF(简化版)
private String parsePdf(File file) throws IOException {
PDDocument doc = PDDocument.load(file);
StringBuilder html = new StringBuilder();
// 实际需用PDFBox提取文本和图片,此处简化
html.append("PDF内容预览");
doc.close();
return html.toString();
}
// 抓取公众号内容(简化版)
private String fetchWechatContent(String url) throws IOException {
// 实际需用Jsoup解析HTML,此处简化
return "公众号内容预览";
}
%>运行环境要求:
tomcatmysqlyum install mavenmvn install com.aliyun.oss:aliyun-sdk-oss:3.15.1mvn install org.apache.poi:poi-ooxml:5.2.3mvn install org.apache.pdfbox:pdfbox:2.0.27将插件文件放置到 UEditor 安装目录下的指定路径中:
doc_magicplugins修改 UEditor 的配置文件,添加自定义按钮以启用新功能:
ueditor.config.js
toolbars: [
['doc_magic', 'bold', 'italic'] // 建议置于工具栏前端以便快速访问
]
设置 OSS 所需的环境变量信息:
export OSS_ENDPOINT="oss-cn-shenzhen.aliyuncs.com"
export OSS_ACCESS_KEY="你的AccessKeyId"
export OSS_SECRET="你的AccessKeySecret"
export OSS_BUCKET="你的Bucket名称"
/etc/profile完成配置后,部署至 Tomcat 服务器并启动应用:
systemctl start tomcat复制插件主目录至项目资源路径:
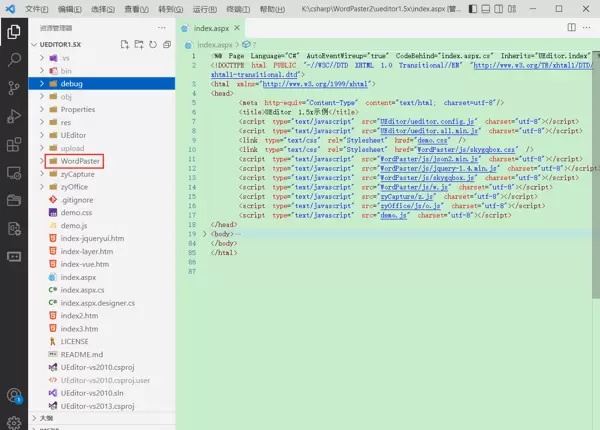
在页面中引入必要的插件脚本文件:
UEditor 1.4.3.3示例注意:若项目中已包含 jQuery,请勿重复引入 jq-1.4 版本。
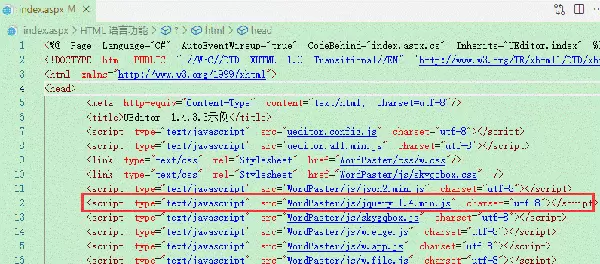
在编辑器工具栏中注册新增的功能按钮:
// 可根据实际需求调整工具栏布局,在实例化编辑器时进行定制化配置
toolbars: [
[
"fullscreen",
"source",
"|",
"zycapture",
"|",
"wordpaster","importwordtoimg","netpaster","wordimport","excelimport","pptimport","pdfimport",
"|",
"importword","exportword","importpdf"
]
]
调用 JS 初始化方法,加载 WordPaster 控件:
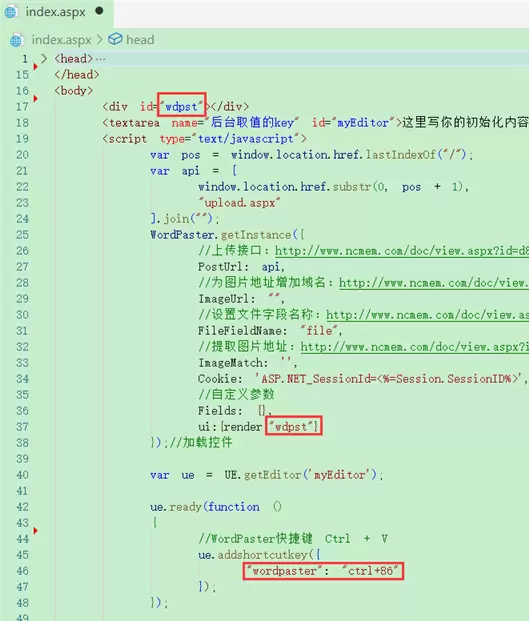
var pos = window.location.href.lastIndexOf("/");
var api = [
window.location.href.substr(0, pos + 1),
"asp/upload.asp"
].join("");
WordPaster.getInstance({
PostUrl: api,
ImageUrl: "",
FileFieldName: "file",
ImageMatch: ''
});
// 加载富文本粘贴控件实例
注意事项:
若后端接口使用的文件字段名为非默认值(如 ueditor 使用 upfile),请手动设置 FileFieldName 参数。
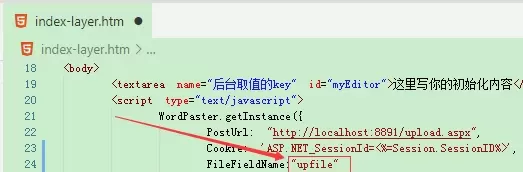
ImageMatch 配置项:
当服务器返回响应为 JSON 格式时,需通过正则表达式提取图片地址。
ImageMatch: ''
点击查看详细配置参考链接
ImageUrl 配置项:
若上传返回的图片路径为相对地址,可使用此参数追加完整域名前缀。
ImageUrl: ""
点击查看详细教程说明
SESSION 权限处理:
若上传接口存在登录态校验(如 SESSION 或 Cookie 验证),需正确传递认证信息,或临时关闭权限验证以便调试。
参考文档地址:
http://www.ncmem.com/doc/view.aspx?id=8602DDBF62374D189725BF17367125F3
mvn tomcat7:run最终效果展示:
223813913致新疆程序员的一句贴心话:“这个需求,包我身上!” 遇到任何技术问题欢迎随时交流,全天候在线响应。
编辑器界面展示如下,提供多种文档格式的便捷导入与处理功能:
支持直接上传并解析Word文档,兼容 .doc 和 .docx 格式文件。
可导入Excel表格文档,适用于 .xls 和 .xlsx 格式的文件类型。
提供“粘贴Word”功能,用户可一键将Word内容粘贴至编辑器,系统会自动上传文档内的图片,并保留原有的文字排版与样式设置。
具备“Word转图片”能力,只需一键即可将上传的Word文件整体转换为图片形式,并自动上传至服务器。
支持PDF文件的一键导入,系统会将整个PDF文档逐页转换为图片并上传到服务器。
PPT文件也可通过一键操作完成导入,每一页幻灯片将被转换成独立图片并上传。
允许用户添加网络图片,可通过URL方式直接上传外部图像资源。
如需查看完整操作示例,可点击下载进行参考。

 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏




