经管之家App
让优质教育人人可得
立即打开


信息检索技术的发展历程,本质上是人类不断推动机器理解语言深层语义的探索过程。从最初的布尔逻辑、倒排索引(Inverted Index),到如今广泛应用的向量搜索(Vector Search),每一次技术跃迁都在重新定义数据交互的方式与边界。当前,随着大语言模型(LLM)的迅猛发展以及检索增强生成(RAG)架构的广泛采用,向量搜索已从学术研究中的边缘课题,逐步演变为支撑企业级AI系统的核心基础设施。
传统的关键词检索依赖于字面匹配(Lexical Matching),虽然在精确查找场景中表现良好,但其存在显著的“词汇鸿沟”问题——难以处理同义词、多义词及上下文相关的语义变化。例如,当用户搜索“犬类护理”时,若文档仅使用“狗”或“幼崽”等表达,则传统引擎可能无法有效召回相关内容,除非依赖人工构建的大规模同义词库 1。相比之下,向量搜索通过深度学习模型将非结构化数据(如文本、图像、音频、视频)映射为高维空间中的数值点(即嵌入,Embedding),并以几何距离衡量语义相似性。这种机制使得查询“canine”能够自然关联到“dog”或“wolf”,从根本上突破了符号层面匹配的局限。
然而,将向量搜索应用于工业级场景面临巨大挑战。在十亿甚至百亿级向量规模下实现毫秒级响应,对计算资源和算法效率提出了极高要求。为此,近似最近邻(ANN)算法如分层导航小世界(HNSW)和倒排文件索引(IVF)应运而生,并催生了Pinecone、Milvus、Weaviate等专用向量数据库生态。同时,为了弥补纯向量检索在精确匹配方面的不足,混合搜索(Hybrid Search)与晚期交互(Late Interaction/ColBERT)等高级架构逐渐成为构建高性能AI系统的主流范式。
本文将从数学基础、核心索引算法、数据库架构对比、高级检索策略及未来趋势等多个维度,深入剖析向量搜索技术。内容涵盖HNSW的图遍历原理、量化压缩带来的精度权衡、BEIR基准测试的实际表现,以及面向Agentic RAG(代理式检索增强生成)的下一代系统设计挑战。
要真正掌握向量搜索的本质,必须理解其背后的数学框架。与传统数据库中处理的标量数据不同,向量数据是在高维空间中存在的几何实体,其价值在于能将抽象的语义概念转化为可度量的空间位置关系。
在向量搜索体系中,一个向量不仅是浮点数的集合,更是信息在潜在语义空间(Latent Semantic Space)中的坐标表示。所谓嵌入(Embedding),是指利用神经网络模型将离散的高维输入(如单词、句子或像素矩阵)转换为低维且稠密的连续向量的过程。
向量表示的思想并非近年才出现。早在20世纪60年代中期,信息检索领域已有初步探索;Gerard Salton及其康奈尔大学团队于1978年发表的开创性论文中,就已提出稀疏与稠密向量的概念,为现代语义搜索奠定了理论基础。
早期方法如词袋模型(Bag-of-Words)和TF-IDF生成的是高度稀疏的向量,其维度等于整个词汇表的大小(常达数万维),且绝大多数元素为零。这类表示无法捕捉词语顺序或语义间的关联性。
而现代嵌入技术(如Word2Vec、BERT以及OpenAI的text-embedding-3)则生成稠密向量,通常具有几百至几千个维度(如384、768、1536甚至3072维)。在此类模型中,语义相近的内容在向量空间中彼此靠近。一个经典案例是向量算术可以体现类比关系:

这一现象说明模型不仅编码了词汇含义,还隐含地学习了性别、身份等级等高层语义特征。
向量的维度是一个关键的设计参数。理论上,维度越高,所能承载的语义信息越丰富,越能区分细微的语义差异。但随之而来的是存储开销的线性增长和计算复杂度的指数上升(即“维度灾难”)。例如,OpenAI的
text-embedding-3-large模型支持高达3072维的嵌入输出,但在实际应用中,开发者常出于成本考虑,采用截断或降维技术来使用较低维度的版本。
一旦数据被转化为向量形式,搜索任务便转化为计算查询向量与候选向量之间的“距离”。选择合适的相似度度量标准至关重要,该标准必须与嵌入模型训练时所使用的保持一致,否则检索结果将失去语义合理性。
欧几里得距离衡量的是两点之间的直线距离,其计算公式如下:
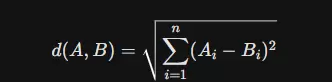
特性
在向量相似性度量中,不同的方法适用于不同场景。欧几里得距离衡量的是两个向量之间的绝对空间距离,其值越小代表越相似。该度量方式对向量的模长敏感,因此在模长具有明确物理或统计意义的应用中表现良好。例如,在部分异常检测模型中,远离数据密集区域的点可被识别为异常点。然而,在高维文本嵌入场景下,由于“维度灾难”现象,所有向量间的欧氏距离趋于接近,导致区分能力下降。
余弦相似度则关注两向量间的方向夹角,通过计算夹角余弦值来判断相似程度,结果范围从-1(方向完全相反)到1(方向一致)。由于它不考虑向量长度,属于模长无关的度量方式,特别适合用于文本语义分析等任务。在自然语言处理领域,文档长度不应影响主题归类,因此使用余弦相似度更为合理——无论是关于“量子物理”的长篇论文还是简短摘要,只要语义一致,其方向就应相近。主流嵌入模型如OpenAI的系列模型,通常都针对余弦相似度进行了优化设计。
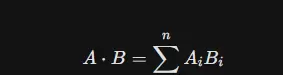
点积是另一种常见度量,定义为两个向量对应元素乘积之和。其数值同时受方向和模长影响,常用于推荐系统中,其中向量长度可能反映用户活跃度或物品受欢迎程度(Popularity)。一个关键数学洞察是:当向量经过归一化处理(即模长为1)后,点积与余弦相似度在数值上完全等价。但由于点积无需执行开方和除法操作,计算效率更高,因此许多高性能向量数据库(如Milvus、Faiss)在处理已归一化的向量时,实际采用点积进行近似检索以提升性能。
| 度量标准 | 核心关注点 | 归一化向量表现 | 典型应用场景 | 计算复杂度 |
|---|---|---|---|---|
| 欧几里得 | 绝对距离 | 与余弦成反比 | 图像处理、空间数据 | 中 |
| 余弦相似度 | 方向(夹角) | 等同于点积 | 文本语义搜索、NLP | 高 (需除以模长) |
| 点积 | 方向 + 模长 | 等同于余弦 | 推荐系统、矩阵分解 | 低 |
若将嵌入视为向量搜索的燃料,则索引算法无疑是驱动整个系统的引擎。对于小规模数据集(如数万条记录),暴力搜索(Flat Search)是一种可行方案——即逐一计算查询向量与所有存储向量的距离。这种方法能实现100%召回率,但时间复杂度为$O(N)$,随着数据量增长至千万甚至十亿级别,响应延迟将无法接受。为此,工业界普遍转向**近似最近邻(ANN, Approximate Nearest Neighbor)**算法,在牺牲极小精度(如从100%降至99%)的前提下,换取数量级级别的速度提升。
HNSW(Hierarchical Navigable Small World)目前被广泛认为是内存内向量搜索中最高效的算法之一,它在查询速度、召回率以及对数据分布的适应性方面达到了优异平衡。
HNSW的设计灵感源自“六度分隔”理论(Small World)和跳表(Skip List)结构,构建了一个多层级的图网络:
搜索过程始于最顶层,算法贪婪地选择离查询向量最近的节点跳跃前进;当当前层无法找到更优邻居时,便逐层“降落”至下一层,并以前一层所得最优节点作为起点继续搜索。这种机制使得搜索可以在高层快速跨越广阔空间,逐步聚焦目标区域,最终在底层完成精细匹配。
MHNSW的性能高度依赖以下关键参数:
efSearch尽管HNSW表现出色,但仍存在一些限制:
向量图中插入节点的操作较为简单,但删除节点则复杂得多,必须对断开的边进行重新连接,以保持图结构的导航能力(Navigability)。在高并发写入与频繁删除的场景下,图的整体质量可能出现退化。最新研究表明,在动态更新过程中可能会出现“不可达点”(Unreachable Point)现象——即某些节点在被删除后,无法再通过贪婪遍历访问到,从而导致检索召回率下降。
倒排文件索引(Inverted File Index, IVF)采用了一种截然不同的策略,其核心思想是利用聚类技术缩小搜索范围,是处理大规模向量数据的经典方法之一。
训练与聚类阶段:
首先,系统会在向量空间中训练一个粗糙量化器(Coarse Quantizer),通常使用K-Means算法将整个空间划分为K个簇(Cluster),每个簇由一个中心点(Centroid)表示。
构建倒排列表:
数据库中的每一个向量都会被分配至距离最近的簇,并存储在该簇对应的倒排列表中。这种结构类似于文本搜索引擎中的倒排索引,只不过这里的“关键词”变成了簇中心的ID。
查询执行流程:
nprobe参数 nprobe 的作用:
nprobe 控制着搜索的精度与效率之间的平衡。当 nprobe=1 时,只搜索最近的一个簇,速度最快但可能遗漏位于边界区域的目标;而当 nprobe=K(K为总簇数)时,则等同于暴力全量扫描。
nprobe=1nprobe=Knprobe 设置为总簇数的1%到10%即可在保证高召回率的同时维持良好的性能。nprobe当向量规模达到十亿级别时,原始浮点向量的存储开销极为庞大。例如,10亿个1536维的float32向量将占用约6TB内存(1B × 1536 × 4B)。为了在有限内存中容纳更多数据,量化技术成为必不可少的手段。
PQ是一种有损压缩方法。它将一个长向量切分为 $m$ 个子向量,并对每个子空间独立执行K-Means聚类。原始向量不再保存,取而代之的是各子向量所属簇中心的编码(Code)。
标量量化(SQ):
将32位浮点数转换为8位整数(int8)或更低精度格式。这种方式通常能减少75%的内存占用(即4倍压缩),同时带来的精度损失极小,已成为多数向量数据库的标准优化选项。
二进制量化(BQ):
这是一种极端压缩方式,将每个维度映射为1比特:若值大于0则记为1,否则为0。例如,一个1024维向量经BQ处理后仅需128字节存储。
汉明距离计算:
BQ使用异或(XOR)操作和位计数(Popcount)指令来高效计算汉明距离,其运算速度比传统浮点距离计算快数十倍。
2025年趋势展望:
随着嵌入模型维度不断上升(如达到3072维),高维带来的信息冗余部分抵消了BQ造成的精度损失。Elasticsearch等系统正逐步引入“BBQ”(Better Binary Quantization)技术,并在重排序阶段融合原始向量信息,实现了检索速度与准确性的协同提升。
针对无法完全载入内存的超大规模向量集,微软提出的DiskANN算法及其衍生版本(如Vamana图)提供了一种基于SSD的解决方案。
基本原理:
将经过压缩的向量(用于导航)保留在内存中,而将完整精度的原始向量存储在高速NVMe SSD上。
搜索流程:
利用内存中的压缩索引快速定位候选邻居集合,然后通过异步IO从磁盘读取对应原始向量,完成最终的距离计算与结果重排序。
应用价值:
该方案使得单台服务器能够以较低成本支持十亿级向量的实时检索,显著降低了硬件总体拥有成本(TCO)。
随着向量搜索需求的快速增长,市场上涌现出多种技术路线。从系统架构角度,可将其划分为两大类:专用向量数据库(Native Vector DBs)和具备向量能力的通用数据库(Vector-capable General DBs)。
此类数据库从底层存储引擎到查询优化器均围绕向量运算设计,通常具备卓越的性能表现及面向AI的特定功能支持。
定位:作为开源领域中的“重型武器”,Milvus专为处理十亿级(Billion-scale)向量数据而设计,适用于高规模场景。
架构优势:具备真正的云原生分布式架构,将接入层、协调服务、执行节点(Worker)与存储层彻底解耦。支持多种索引类型,包括HNSW、IVF和DiskANN,并提供GPU加速能力,提升计算效率。
适用场景:适合拥有强大运维能力的大型互联网企业或AI公司,尤其在对吞吐量和响应延迟有极致要求的环境中表现突出。
局限性:部署依赖多个外部组件,如Etcd、MinIO以及Pulsar/Kafka等,导致整体架构较为复杂,学习成本较高。
定位:一款AI原生(AI-Native)的开源数据库,强调模块化设计与开发者友好体验。
特色功能:不仅支持向量存储,还内置“向量化模块”(Vectorizers),可直接接收文本或图像输入,并由数据库调用模型完成向量生成。同时支持GraphQL接口,允许以面向对象的方式组织数据结构(Class/Object)。
混合搜索能力:集成BM25算法,支持高度灵活的混合检索配置,实现语义与关键词搜索的协同优化。
适用场景:非常适合需要快速构建端到端RAG应用、重视数据建模灵活性及多模态搜索能力的开发团队。
定位:基于Rust语言开发的高性能开源向量数据库,注重系统安全与运行效率。
架构优势:得益于Rust语言的内存安全保障与高效性能,Qdrant在资源利用方面表现出色。除支持HNSW外,特别针对带过滤条件的向量搜索进行了深度优化——通过在图遍历过程中动态应用Payload Filtering,有效解决了传统预过滤或后过滤带来的性能瓶颈。
适用场景:适用于对查询性能和资源利用率敏感的应用场景,例如推荐系统或匹配引擎,尤其是需要复杂元数据过滤的业务系统。
许多企业在技术选型时更倾向于在现有数据库基础上扩展向量能力,而非引入全新的专用数据库组件,从而降低架构复杂度与维护成本。
实现方式:依托Lucene库实现HNSW索引,为搜索引擎注入向量检索能力。
优势:被誉为“混合搜索”的标杆产品。其具备业界领先的倒排索引机制(基于BM25)和成熟的文本处理能力。结合Reciprocal Rank Fusion (RRF) 方法融合向量结果,在多项基准测试中展现出优异的相关性表现,开箱即用效果显著。
劣势:由于是基于Java构建的通用搜索平台,在纯向量搜索的查询速率(QPS)和延迟控制上,通常不及采用C++或Rust编写的专用向量数据库。
实现方式:以插件形式为PostgreSQL添加向量数据类型及IVFFlat、HNSW等索引支持。
优势:实现“单一事实来源”(Single Source of Truth)。开发者可在一条SQL语句中联合使用关系型操作(如JOIN)与向量相似度计算。对于中小规模应用(一般低于1亿向量),该方案具有成本低、架构简洁的优势。
劣势:在超大规模数据集下,受限于PostgreSQL的单进程模型,其索引构建速度和查询性能无法媲美分布式专用向量数据库,扩展性相对有限。
| 特性 | Pinecone | Milvus | Weaviate | Qdrant | Elasticsearch | Pgvector |
|---|---|---|---|---|---|---|
| 类型 | 托管 SaaS | 开源 / 分布式 | 开源 / 模块化 | 开源 / 高性能 | 搜索引擎 | DB 扩展 |
| 核心算法 | 专有图算法 | HNSW, IVF, DiskANN | HNSW, Flat | HNSW | HNSW (Lucene) | IVFFlat, HNSW |
| 混合搜索 | 支持 (Sparse-Dense) | 支持 | 原生 BM25 | 支持 | 业界标杆 | SQL 组合 |
| 扩展性 | Serverless 自动伸缩 | 分布式集群 | 分片集群 | 分布式 | 分片集群 | 垂直/读写分离 |
| 主要场景 | 企业级 SaaS, 快速落地 | 超大规模, 本地部署 | RAG 应用, 灵活性 | 高性能过滤, 边缘 | 日志+搜索 | 关系型+向量 |
| 元数据过滤 | 专有优化 | 位图/分区 | 预过滤优化 | Payload索引 | DSL 过滤 | SQL WHERE |
仅实现向量存储并不足以应对复杂的现实需求。为了在多样化场景中提供高质量的检索结果,必须引入更先进的检索架构设计。
尽管向量搜索在捕捉语义关联方面表现优异,但在处理精确匹配任务时存在明显短板。例如,在查找特定错误码“Error 505”、人名或产品型号时,向量模型可能将其关联至“系统故障”或“崩溃”等概念,却遗漏了实际包含该关键词的文档。
混合搜索正是为弥补这一缺陷而生,旨在融合两种检索范式的优势:
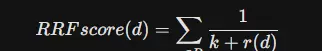
RRF(Reciprocal Rank Fusion)不依赖于具体的相似度得分,因为不同模型的分数范围不一致——例如BM25的得分是无界的,而余弦相似度则限制在0到1之间,难以直接融合。相反,RRF基于文档在各个排序列表中的位置进行融合。这种机制具备极强的鲁棒性,在BEIR基准测试中,混合搜索方法的表现几乎始终优于单独使用任一检索方式。
在实际场景中,用户常结合元数据执行搜索,例如“查找2023年发布的关于AI的论文”。此时,过滤操作与向量搜索的执行顺序至关重要。
该策略先通过向量搜索获取Top K结果(如前100条),再对这些结果应用过滤条件(如年份=2023)。
风险:若这Top 100条结果中没有一篇发布于2023年,即使数据库中存在符合条件的文档,最终返回结果也为零,导致召回率严重下降。
此方法首先根据元数据筛选出满足条件的文档子集(如所有2023年的文档),然后仅在该子集内进行向量搜索。
挑战:对于HNSW这类图结构索引,预过滤意味着在遍历过程中必须跳过不符合条件的节点。如果符合条件的节点分布稀疏,或被大量无效节点包围,贪婪搜索可能陷入局部死循环,无法继续推进,造成搜索提前终止。这一现象被称为“连接性断裂”。
现代向量数据库(如Qdrant、Azure AI Search)引入了“适应性过滤”或“严格后过滤”机制。以Azure为例:
strictPostFilter系统可动态扩展搜索范围,直到获得足够数量的符合过滤条件的结果;或者在构建HNSW图时即考虑元数据的连通性,确保特定过滤条件下图的可达性,例如采用Acorn算法来增强子集内的连接稳定性。
传统向量检索多采用双编码器(Bi-Encoder)架构,即将查询和文档各自编码为一个固定长度的向量。这种方式要求将整个文档的语义压缩进单一向量,不可避免地引发信息瓶颈问题。
**ColBERT(Contextualized Late Interaction over BERT)** 提出了全新的范式:
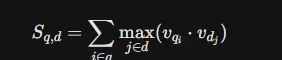
以OpenAI的CLIP(Contrastive Language-Image Pre-training)为代表的技术,实现了文本与图像在统一向量空间中的映射。
衡量向量搜索系统的优劣,不仅要看QPS(每秒查询数)和响应延迟,更关键的是检索质量。
BEIR(Benchmarking Information Retrieval)是当前评估信息检索模型泛化能力的核心框架,涵盖18个多样化领域数据集,如生物医学、金融、新闻和问答系统。
核心发现:
工程实践中并不存在绝对最优配置。通过调节HNSW参数:
efSearch可以在召回率与响应速度之间灵活调整,形成一条权衡曲线。高召回通常伴随更高延迟,系统设计需根据具体业务需求选择合适的工作点。
通过调整参数,可以绘制出一条性能曲线,反映出不同配置下的系统表现:
低延迟区:
efSearch高召回区:
efSearch长尾延迟问题:
高平均召回率并不能完全反映真实体验。正如案例55所示,部分“长尾查询”(Tail Queries)可能表现出极差的响应性能,造成用户体验断崖式下降。因此,在评估系统整体表现时,必须关注P95或P99级别的延迟下所对应的召回能力。
向量搜索正处于高速演进阶段,以下几项技术趋势将主导未来数年的架构发展方向。
随着嵌入模型维度逐步提升至3072维甚至更高,存储开销成为瓶颈,推动行业采用更高效的压缩方案。二进制量化(Binary Quantization)将浮点向量转换为比特表示,实现高达32倍的压缩比,显著降低内存与带宽消耗。
发展趋势:结合“重排序”机制——即先利用BQ快速筛选Top N结果,再使用原始高维向量进行精细排序——可在保障精度的同时大幅提升效率。Elasticsearch的BBQ实验结果显示,其检索速度较乘积量化(PQ)提升2到4倍,预示着单机支撑百亿级向量将成为现实。
当前主流的HNSW算法在面对频繁的数据删除和更新操作时存在明显短板,容易引发图结构退化和“脏数据”堆积,影响检索稳定性。
发展趋势:下一代索引技术将聚焦于“实时图”(Real-time Graph)的构建与维护,引入智能垃圾回收策略及局部图重构机制,有效解决节点不可达等问题,从而更好地服务于高频交易、实时个性化推荐等强时效性场景。
随着AI代理(Agent)技术的发展,传统的一次性检索模式正被打破。复杂任务中,一个智能体可能需要经历多次检索、推理、再检索的过程(即多跳检索),才能完成最终回答。
影响分析:此类行为极大增加了后端向量搜索的并发压力。一次用户交互可能触发数十次底层查询请求,这对系统的延迟控制和吞吐能力提出空前挑战。未来的向量数据库或将深度融合轻量级推理逻辑,甚至直接在数据库内部运行Agent决策流程,实现更高效的协同处理。
向量搜索已完成从实验室原型到大规模生产部署的跨越,成为连接人类意图与机器数据理解的关键桥梁。对企业架构师而言,核心问题已不再是“是否采用”,而是“如何设计”合适的向量架构。
是选择Milvus这类支持百亿级规模的分布式重型系统,还是偏好Postgres配合pgvector插件以保持整体架构简洁?是追求纯向量带来的深层语义匹配,还是结合关键词搜索以兼顾精确控制?这些问题的答案,取决于对业务场景的深入洞察——包括对延迟的敏感程度、对召回完整性的容忍范围,以及数据本身的模态特性。
随着二进制量化的成熟落地,以及Agentic RAG应用的爆发式增长,未来的向量数据库将更加轻量、高效且具备一定智能性。它们不再只是被动的数据仓库,而将演变为AI系统中负责长期记忆管理和动态知识获取的核心组件。

 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏




