经管之家App
让优质教育人人可得
立即打开


随着全球数据量以每两年翻一番的速度迅猛增长(据 IDC 预测,到 2025 年全球数据圈将达到 175ZB),大数据已不再仅仅是技术圈的热门词汇,而是演变为推动各行业转型升级的核心驱动力。从互联网广告的精准推送,到制造业中的设备预测性维护,大数据的应用场景不断拓展,深刻影响着社会运行机制与人们的生活方式。
大数据分析构成了一条完整的链路,涵盖数据采集、清洗处理、存储管理、深入挖掘以及最终的价值输出。这一过程并非线性推进,而是一个动态闭环。
数据预处理是整个流程的基础环节,通常占据项目总工作量的 60% 以上。高质量的数据是模型有效性的前提。
接下来是核心分析方法,主要包括描述性分析(发生了什么)、诊断性分析(为何发生)、预测性分析(未来可能发生什么)和规范性分析(应该采取何种行动)。
上述所有步骤都依赖于强大的技术支撑体系,如 Hadoop 分布式架构、Spark 快速计算引擎以及云计算平台的支持,这些构成了现代大数据处理的技术底座。
为更直观地理解大数据分析的实际应用,我们以某电商平台为例,开展一次完整的用户购买行为分析项目。目标是识别影响购买决策的关键因素,并构建预测模型,辅助营销策略制定。
本案例采用 Python 3 编程语言和 Jupyter Notebook 作为开发环境,便于代码编写与结果可视化。
# 数据处理库
import pandas as pd
import numpy as np
# 数据可视化库
import matplotlib.pyplot as plt
import seaborn as sns
# 机器学习库
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, roc_auc_score, confusion_matrix
# 设置中文显示
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 忽略警告信息
import warnings
warnings.filterwarnings('ignore')我们使用一份模拟生成的电商用户行为数据集,包含以下字段:用户 ID、页面浏览时长、浏览商品数量、是否加入购物车、是否收藏商品、最终是否完成购买等。
# 模拟数据生成 (在实际工作中,你会从数据库或数据湖加载数据)
np.random.seed(42) # 保证结果可复现
data_size = 10000
data = {
'user_id': np.arange(1, data_size + 1),
'browse_duration': np.random.exponential(scale=10, size=data_size) * np.random.choice([1, 2, 3], size=data_size, p=[0.5, 0.3, 0.2]),
'browse_items': np.random.poisson(lam=5, size=data_size) + 1,
'is_add_to_cart': np.random.binomial(n=1, p=0.3, size=data_size),
'is_favorite': np.random.binomial(n=1, p=0.15, size=data_size),
'user_segment': np.random.choice(['新用户', '老用户', '高价值用户'], size=data_size, p=[0.4, 0.5, 0.1]),
'purchase': np.random.binomial(n=1, p=0.2, size=data_size) # 目标变量
}
df = pd.DataFrame(data)
# 查看数据前几行
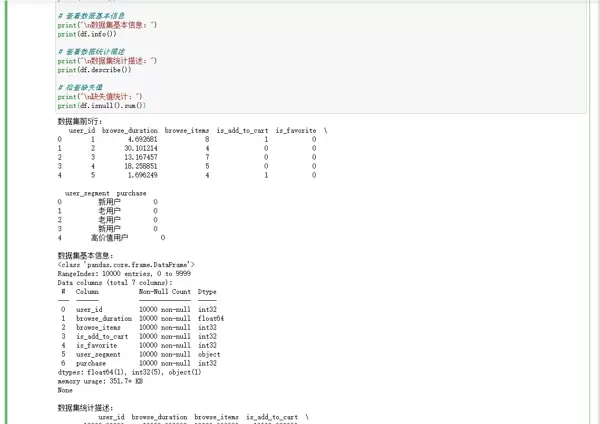
print("数据集前5行:")
print(df.head())
# 查看数据基本信息
print("\n数据集基本信息:")
print(df.info())
# 查看数据统计描述
print("\n数据集统计描述:")
print(df.describe())
# 检查缺失值
print("\n缺失值统计:")
print(df.isnull().sum())数据预处理说明:在当前示例中,数据已被设定为“清洁”状态。但在真实业务环境中,需执行缺失值填补、异常值检测、数据类型标准化等一系列操作,确保数据质量。
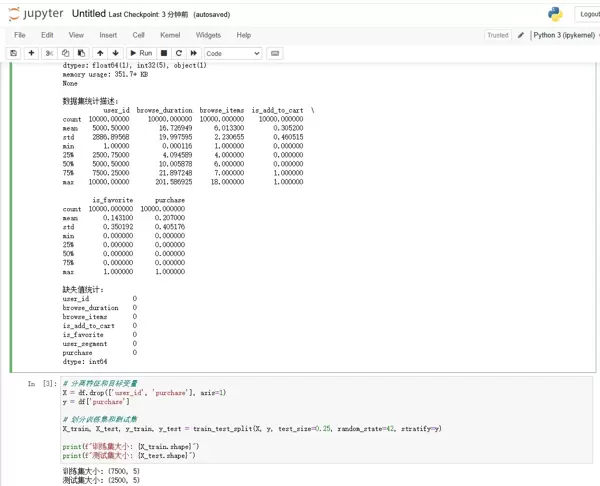
# 分离特征和目标变量
X = df.drop(['user_id', 'purchase'], axis=1)
y = df['purchase']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42, stratify=y)
print(f"训练集大小: {X_train.shape}")
print(f"测试集大小: {X_test.shape}")通过可视化手段对数据分布、变量关系进行探索,是发现潜在规律的重要阶段。
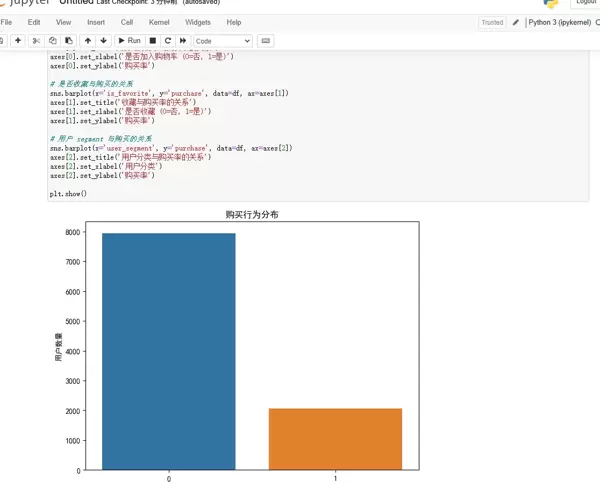
# 1. 目标变量分布
plt.figure(figsize=(8, 6))
sns.countplot(x='purchase', data=df)
plt.title('购买行为分布')
plt.xlabel('是否购买 (0=否, 1=是)')
plt.ylabel('用户数量')
plt.show()
purchase_rate = df['purchase'].mean() * 100
print(f"整体购买率: {purchase_rate:.2f}%")
# 2. 数值型特征与目标变量的关系
fig, axes = plt.subplots(1, 2, figsize=(16, 6))
# 浏览时长与购买的关系
sns.boxplot(x='purchase', y='browse_duration', data=df, ax=axes[0])
axes[0].set_title('浏览时长与购买行为的关系')
axes[0].set_xlabel('是否购买 (0=否, 1=是)')
axes[0].set_ylabel('浏览时长 (分钟)')
# 浏览商品数与购买的关系
sns.boxplot(x='purchase', y='browse_items', data=df, ax=axes[1])
axes[1].set_title('浏览商品数与购买行为的关系')
axes[1].set_xlabel('是否购买 (0=否, 1=是)')
axes[1].set_ylabel('浏览商品数')
plt.show()
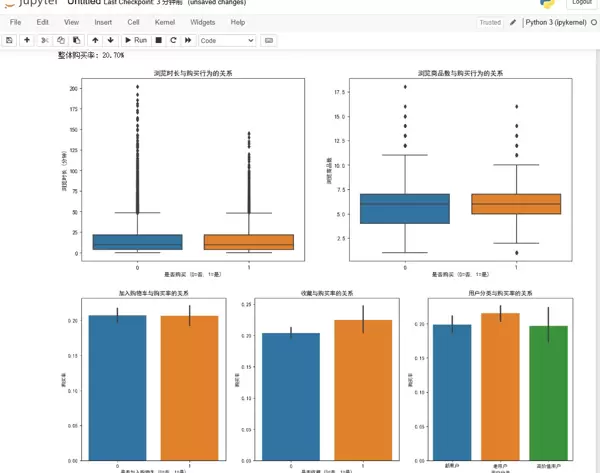
# 3. categorical特征与目标变量的关系
fig, axes = plt.subplots(1, 3, figsize=(18, 6))
# 是否加入购物车与购买的关系
sns.barplot(x='is_add_to_cart', y='purchase', data=df, ax=axes[0])
axes[0].set_title('加入购物车与购买率的关系')
axes[0].set_xlabel('是否加入购物车 (0=否, 1=是)')
axes[0].set_ylabel('购买率')
# 是否收藏与购买的关系
sns.barplot(x='is_favorite', y='purchase', data=df, ax=axes[1])
axes[1].set_title('收藏与购买率的关系')
axes[1].set_xlabel('是否收藏 (0=否, 1=是)')
axes[1].set_ylabel('购买率')
# 用户 segment 与购买的关系
sns.barplot(x='user_segment', y='purchase', data=df, ax=axes[2])
axes[2].set_title('用户分类与购买率的关系')
axes[2].set_xlabel('用户分类')
axes[2].set_ylabel('购买率')
plt.show()EDA 主要发现:
基于 EDA 的洞察,我们将关键行为特征纳入模型输入,构建用于预测购买行为的分类算法。
# 定义特征预处理步骤
# 数值型特征
numeric_features = ['browse_duration', 'browse_items']
numeric_transformer = Pipeline(steps=[
('scaler', StandardScaler()) # 标准化
])
# 分类型特征
categorical_features = ['is_add_to_cart', 'is_favorite', 'user_segment']
categorical_transformer = Pipeline(steps=[
('onehot', OneHotEncoder(drop='first', sparse_output=False)) # 独热编码
])
# 组合预处理步骤
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, numeric_features),
('cat', categorical_transformer, categorical_features)
])
# 构建模型 pipeline
# 我们使用随机森林分类器作为示例
model = Pipeline(steps=[
('preprocessor', preprocessor),
('classifier', RandomForestClassifier(n_estimators=100, random_state=42))
])
# 在训练集上训练模型
model.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = model.predict(X_test)
y_pred_proba = model.predict_proba(X_test)[:, 1] # 预测为正类的概率# 计算评估指标
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred)
roc_auc = roc_auc_score(y_test, y_pred_proba)
conf_matrix = confusion_matrix(y_test, y_pred)
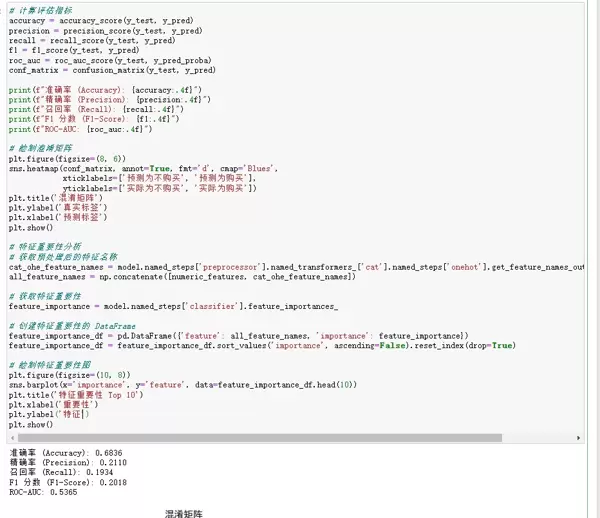
print(f"准确率 (Accuracy): {accuracy:.4f}")
print(f"精确率 (Precision): {precision:.4f}")
print(f"召回率 (Recall): {recall:.4f}")
print(f"F1 分数 (F1-Score): {f1:.4f}")
print(f"ROC-AUC: {roc_auc:.4f}")
# 绘制混淆矩阵
plt.figure(figsize=(8, 6))
sns.heatmap(conf_matrix, annot=True, fmt='d', cmap='Blues',
xticklabels=['预测为不购买', '预测为购买'],
yticklabels=['实际为不购买', '实际为购买'])
plt.title('混淆矩阵')
plt.ylabel('真实标签')
plt.xlabel('预测标签')
plt.show()
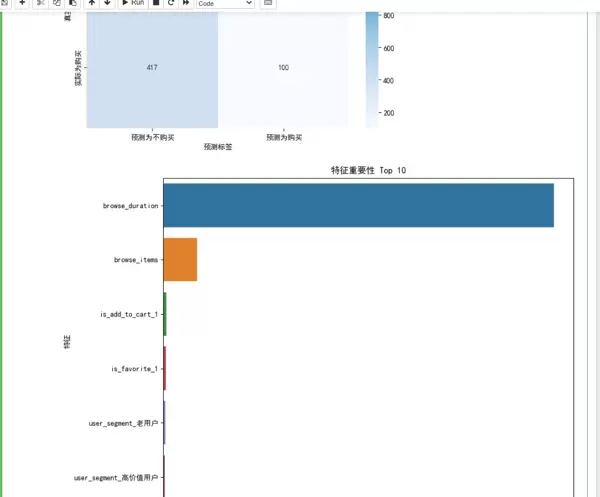
# 特征重要性分析
# 获取预处理后的特征名称
cat_ohe_feature_names = model.named_steps['preprocessor'].named_transformers_['cat'].named_steps['onehot'].get_feature_names_out(categorical_features)
all_feature_names = np.concatenate([numeric_features, cat_ohe_feature_names])
# 获取特征重要性
feature_importance = model.named_steps['classifier'].feature_importances_
# 创建特征重要性的 DataFrame
feature_importance_df = pd.DataFrame({'feature': all_feature_names, 'importance': feature_importance})
feature_importance_df = feature_importance_df.sort_values('importance', ascending=False).reset_index(drop=True)
# 绘制特征重要性图
plt.figure(figsize=(10, 8))
sns.barplot(x='importance', y='feature', data=feature_importance_df.head(10))
plt.title('特征重要性 Top 10')
plt.xlabel('重要性')
plt.ylabel('特征')
plt.show()评估结果与解读:
尽管分析流程清晰,但在实际落地过程中仍面临多重挑战:
数据安全与隐私保护:本例使用的是合成数据。而在现实场景中,用户浏览轨迹、交易记录等均属敏感信息,必须严格遵循 GDPR、网络安全法等相关法规,实施数据加密与匿名化处理。
打破数据孤岛:本次分析仅依赖单一维度的用户行为日志。若要提升模型精度,还需整合用户画像、商品属性、促销活动等多源异构数据,这要求企业内部实现跨部门的数据共享与协同机制。
专业人才短缺:完成此类项目需要分析师同时掌握编程技能、统计知识和业务理解力。企业应加强人才培养与引进,打造复合型数据团队。
数据价值落地难:模型输出了用户购买概率后,关键在于如何将其转化为行动。例如:向高概率用户发放定向优惠券促单,或对低兴趣用户推送个性化内容以激发需求。唯有将分析成果嵌入具体业务流程,才能真正释放数据价值。
面向未来,大数据分析将持续演进,主要呈现以下方向:
本文通过一个电商用户行为分析的完整案例,展示了从原始数据到可执行洞察的全过程。代码实践不仅验证了理论框架的有效性,也揭示了数据背后蕴含的商业逻辑。在数据驱动的时代背景下,掌握从数据中提取价值的能力,已成为个人职业发展和企业战略升级的核心竞争力。大数据的旅程远未结束,更多可能性等待我们共同发掘。

 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏




