数据清洗与转换处理
前言
通过编写SHELL脚本,能够实现对输入文件的逐行、逐字段读取,并针对特定字段执行批量操作,如加密、解密或格式转换等处理任务。
提示:这里可以添加本文要记录的大概内容:
一、处理目标
利用SHELL脚本对原始数据文件进行加工,主要目的是将
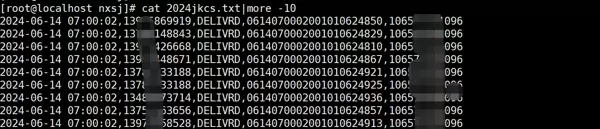
原文件2024jkcs.txt
中的每一行记录进行处理后,输出至新的结果文件中:
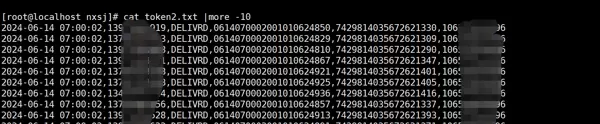
token2.txt
二、具体处理流程
1. 原始数据文件:2024jkcs.txt
该文件为待处理的源数据,使用AWK命令将其内容整理为以逗号作为分隔符的标准格式。
2. SHELL脚本实现
以下是用于处理数据的完整脚本示例:
[root@localhost nxsj]# cat x.sh
#!/bin/bash
# 定义输入文件和输出文件
input_file="2024jkcs.txt"
output_file="token2.txt"
# 逐行读取输入文件
while IFS=',' read -r date mobile status id number
do
# 使用 java 程序获取 part3 的转换结果
result=$(java -jar msgid.jar "$id")
# 将结果插入到适当位置,并写入输出文件
echo "$date,$mobile,$status,$id,$result,$number" >> "$output_file"
done < "$input_file"
echo "处理完成,结果已保存到 $output_file"
2. 脚本逻辑解析
- 逐行读取:采用while循环结合read命令,按行加载输入文件2024jkcs.txt的内容。
- 字段分割:设置IFS=',',指定逗号为字段分隔符,确保每行数据可被正确拆分。
- 变量映射:每行数据被分解为以下五个变量:
- date:表示日期信息
- mobile:存储手机号码
- status:记录状态码
- id:消息ID,是核心处理字段
- number:数字类字段
- 关键处理步骤:调用Java程序msgid.jar对“id”字段(即原文件中第四个以逗号分隔的字段)进行转换,结果存入变量result中。
- 输出生成:将原始各字段与新增的处理结果合并,按顺序输出并追加至目标文件token2.txt,最终形成包含新字段的完整记录。
2. 输出结果文件:token2.txt
经过脚本处理后生成的目标文件内容如下所示:
总结
整个数据处理流程实现了从原始文本读取、字段解析、外部程序调用转换到结果输出的自动化操作。通过SHELL脚本与Java工具的结合,提升了数据清洗与转换的效率与准确性。



 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏





