深度学习环境解析与大作业执行指南
本文旨在为你梳理清楚此前配置的开发环境本质,并为即将开展的深度学习大作业提供一条清晰可行的操作路径。
一、我们之前究竟在配置什么?
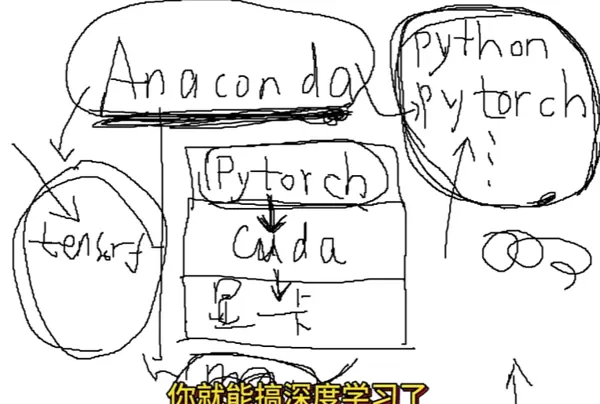
在动手写模型代码前,许多同学常被 CUDA、Anaconda、PyTorch 等术语困扰。面对命令行中不断弹出的报错信息,很容易陷入迷茫:“这一步到底是为了什么?”
其实,整个环境搭建过程就像在打造一个功能完备的专业厨房,每一层技术组件都对应着厨房中的不同角色与工具。
1. 技术层级结构详解
第 1 层:GPU(显卡)——【超级大厨】
作为硬件核心,GPU 相较于 CPU 更像是拥有数千只手的高效厨师,专精于大规模并行计算任务。它能极快地完成深度学习中最常见的矩阵运算,是训练神经网络的关键动力源。
第 2 层:显卡驱动(Driver)——【上岗资格证】
若无驱动程序,操作系统无法识别显卡,自然也无法调度其工作。使用 NVIDIA 显卡时需安装对应的官方驱动,并注意版本兼容性问题。
第 3 层:CUDA ——【特制刀具套装】
CUDA 是 NVIDIA 提供的通用并行计算平台,允许开发者绕过图形渲染流程,直接调用 GPU 进行数学运算。没有它,GPU 只能用于游戏或图形处理,无法参与深度学习训练。
第 4 层:cuDNN ——【切菜神技】
全称为 CUDA Deep Neural Network library,是专为深度神经网络优化的底层库。可类比为厨师掌握的“土豆丝连切不散”绝技,对卷积、池化等操作进行高度加速。据 NVIDIA 官方称,启用 cuDNN 后性能提升可达 30% 以上。
第 5 层:PyTorch / TensorFlow ——【菜谱与锅具组合】
这是你日常编写代码所依赖的深度学习框架。通过 Python 调用 PyTorch 接口,PyTorch 再向下调用 CUDA,最终由 GPU 执行计算任务。若不用这些框架,你将不得不使用 C++ 直接操控硬件,开发难度极大。
第 6 层:Anaconda ——【厨房管理系统】
Python 包管理长期存在依赖冲突问题。Anaconda 的价值在于支持创建多个独立的虚拟环境(即“厨房”),每个项目可拥有专属运行空间。
例如:
- 环境①:Python 3.9 + PyTorch 1.12
- 环境②:Python 3.7 + TensorFlow
- 环境③及以后:可用于普通脚本或其他用途
每个环境互不影响,项目结束只需删除对应文件夹即可彻底清理,保持系统整洁。
(此时正确记录 env 中包的路径尤为重要)
DP_learn
简而言之,你此前解决路径迁移和 SSL 报错等问题,目的就是成功建立这个“独立厨房”,并配齐所需的“锅具”(如 PyTorch),打通与“大厨”(GPU)之间的通信链路。
二、如何系统完成你的深度学习大作业?
尽管老师布置的任务要求繁多,但本质上遵循的是标准的深度学习流水线(Pipeline)流程。以下为具体实施步骤。
第一步:数据准备(Data Preparation)
任务说明: 使用病虫害图像数据集进行建模训练。
关键点 1:数据划分(Data Splitting)
切记:不能拿考试题来当练习题!必须将数据集划分为三个部分:
- 训练集(Train): 占比约 70%-80%,用于模型学习特征。
- 验证集(Val): 占比约 10%-20%,用于监控训练过程,判断是否出现过拟合。
- 测试集(Test): 占比约 10%,作为最终评估依据,模型在整个训练过程中不得接触此类数据。
代码实现常用方法:
sklearn.model_selection.train_test_split
或结合
torchvision.datasets.ImageFolder
与
random_split
关键点 2:数据增强(Data Augmentation)
为何需要?
若仅有几百张图片,模型极易陷入“死记硬背”状态(即过拟合)。因此需通过对图像进行旋转、翻转、裁剪、色彩调整等方式扩充数据多样性,促使模型具备泛化能力。
代码实现示例:
torchvision.transforms
transforms.Compose([
transforms.RandomHorizontalFlip(), # 随机水平翻转
transforms.RandomRotation(10), # 随机小幅旋转
transforms.ToTensor(), # 转换为张量格式
transforms.Normalize(...) # 标准化处理
])
第二步:模型选择与迁移学习(Transfer Learning)
任务目标: 基于预训练模型应用迁移学习策略。
核心原理(必读):
从零开始训练 VGGNet 或 ResNet 类模型,通常需要百万级数据(如 ImageNet)以及数周时间。而你的数据集规模较小,若强行从头训练,不仅耗时且效果不佳。
迁移学习(Transfer Learning)正是为此而生的技术方案——利用已在大型数据集上训练好的模型权重作为起点,在新任务上进行微调(fine-tune),从而大幅提升效率与准确率。
这正是“站在巨人的肩膀上”的体现。我们可以直接下载一个已在 ImageNet 数据集上完成训练的模型——它已经具备了识别基础特征的能力,比如线条、圆形、猫耳、狗鼻等。
具体操作步骤如下:
1. 模型载入
model = models.vgg16(pretrained=True)
2. 参数冻结(Freeze)
将模型中用于提取图像特征的前面若干层参数锁定,禁止在训练过程中更新。这些层已经具备较强的通用特征提取能力,无需重新学习。
3. 替换全连接层(Classifier)
移除原模型最后的全连接层(原本用于输出1000个类别),替换为适合你任务的新分类层。例如,若你的害虫分类任务仅包含5类,则新层应输出5个类别。
4. 仅训练最后一层
此时只对新添加的分类层进行训练,其余层保持冻结状态。这种方法不仅大幅缩短训练时间,还能取得良好的分类效果。
第三步:模型训练(Training)
CPU 与 GPU 的选择:
虽然可以使用 CPU 进行训练,但老师特别指出“使用 CPU 耗时较长”。如今你的环境已配置完毕,请务必启用 GPU 加速。
在代码中加入以下语句:
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device) # 将模型加载到显卡
# 训练时也需将输入数据转移到显卡: inputs, labels = inputs.to(device), labels.to(device)
一旦使用 GPU 执行迁移学习,整个训练过程可能只需几分钟即可完成。
第四步:模型评估与结果分析(Evaluation)
- 验证测试:将测试集数据输入模型,计算整体准确率(Accuracy)。
- 可视化训练过程:
- 绘制 Loss 曲线,观察训练过程中损失值是否持续下降;
- 绘制 Accuracy 曲线,查看验证集准确率是否逐步提升。
- 案例展示:挑选若干张预测正确和预测错误的图片进行展示与分析,有助于理解模型的判断逻辑与潜在问题。
特别建议
不必惊慌:
遇到环境配置报错是常见现象。今天你所经历的
CondaSSLError
未来仍可能出现类似情况,记住可以通过更换 pip 源或手动补全 DLL 文件来解决。
善用现有工具:
老师提到“依葫芦画瓢”,这确实是正确做法。无需从零开始手写 VGGNet 的每一个卷积层,直接调用预训练模型即可。
torchvision.models
这种做法不仅高效,也是工业界的通用标准。
关于 D 盘的配置意义:
本次实践中,你最重要的成果之一就是成功将开发环境部署到了 D 盘。这意味着今后你可以自由安装大型 Python 包(如 TensorFlow、OpenCV 等),而无需担忧 C 盘空间不足的问题。
祝你大作业顺利完成!当前环境已准备就绪,现在就可以正式开启你的模型训练之旅。


 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏





