企业专利丛林数据(2015-2024)
在推动新技术商业化的过程中,企业常常面临一种被称为“专利丛林”的复杂现象。这种现象表现为某一技术领域中存在大量相互交织的专利网络,形成对后续创新者的进入壁垒。专利丛林的密集程度通常通过该领域内由企业间专利引用关系所构成的“三角阻碍”数量来衡量,进而反映企业在技术创新过程中可能遭遇的专利阻碍及其相关成本。
研究专利丛林密度对于理解其对企业创新活动的影响具有重要意义。它不仅影响企业创新的数量与质量,还可能重塑整个行业的创新结构,尤其在高新技术产业中表现得尤为突出。深入分析这一问题,有助于为知识产权保护政策的制定提供实证支持,优化专利制度设计,从而更好地激励技术创新,助力国家实现高水平的科技自主与自强目标。

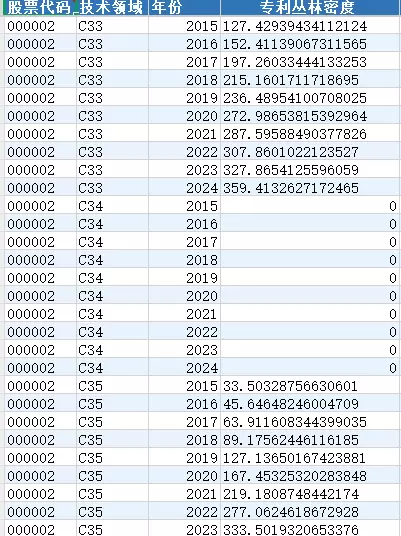
本数据集借鉴张美扬等(2024)的研究方法,基于企业之间专利的相互引用关系识别并构建“三角阻碍”结构。首先,在技术领域层面,利用领域内的三角阻碍总数和专利总量计算出该领域的专利丛林密度;随后,进一步将该指标映射至企业层面,生成可操作的企业级专利丛林密度变量。
具体而言,数据覆盖时间为2015年至2024年,涵盖中国全部A股上市公司。原始信息经由数据皮皮侠团队人工采集与系统整理,确保内容真实、准确、可用。最终数据以Excel格式呈现,便于用户进行统计分析与模型构建。
主要数据指标包括:
数据来源说明:本数据由数据皮皮侠团队独立整理完成,所有内容均经过核实,保证真实性与有效性。
参考文献:
张美扬, 龙小宁. 专利丛林:科技创新中的绿荫还是荆棘? [J]. 金融研究, 2024, (05): 169-187.


 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏





