我们可以通过函数来描述现实世界中的各种现象。在机器学习中,最基本的模型是线性函数,但其表达能力有限。为了处理更复杂的关系,需要引入非线性变换。
激活函数的作用就是将原本的线性输出转化为非线性输出,从而让模型具备拟合复杂模式的能力。

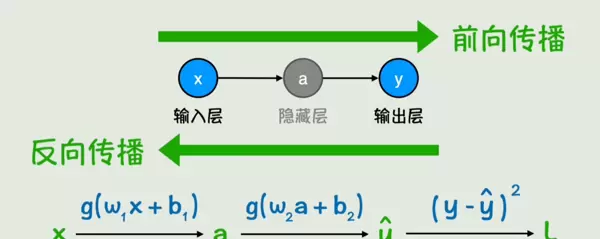
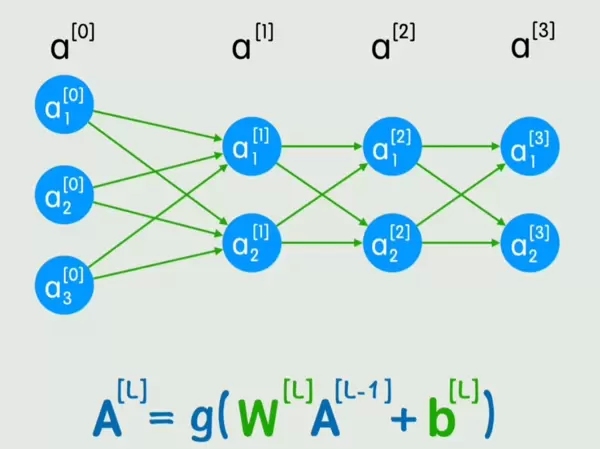
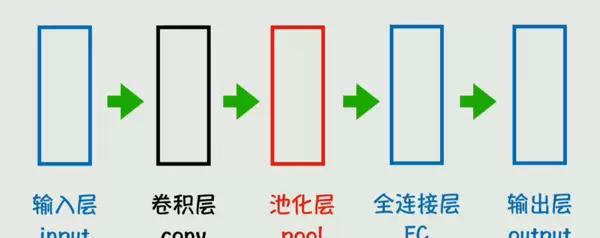
一个典型的神经网络由多个基本组件构成:输入层接收数据,输出层给出结果,中间包含若干隐藏层,每一层由多个神经元组成。
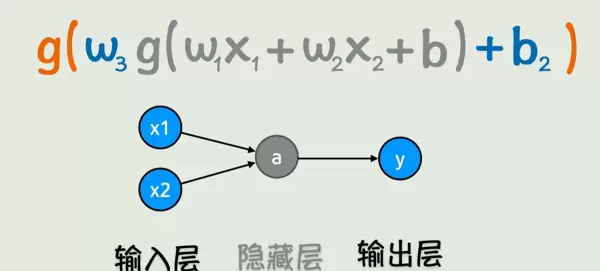
整个结构通过前向传播过程完成计算:从输入 x 开始,逐层计算,最终得到输出 y。
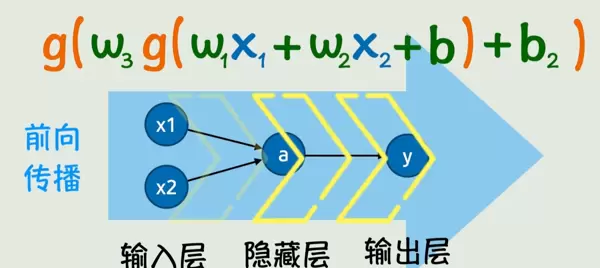
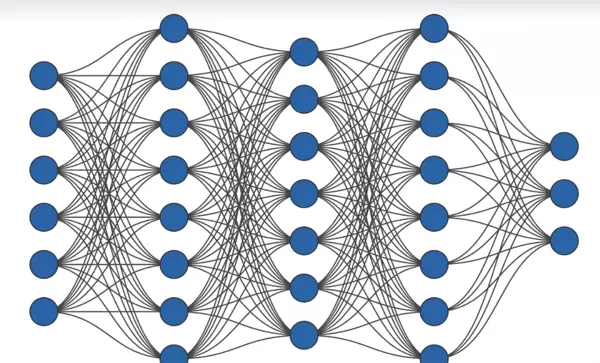
随着网络层数和每层神经元数量的增加,神经网络能够表达极为复杂的非线性映射关系。
2、计算神经网络的参数
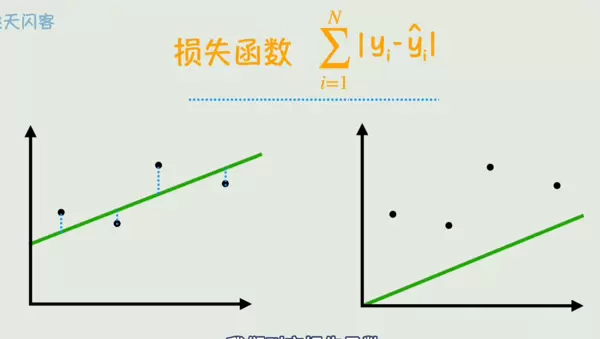
最基础的线性模型形式为 y = wx + b,其中 w 是权重,b 是偏置项。关键问题在于:什么样的参数组合才是最优的?
答案在于“拟合效果”——即模型预测值与真实值之间的接近程度。这种差距通常用损失函数来量化。
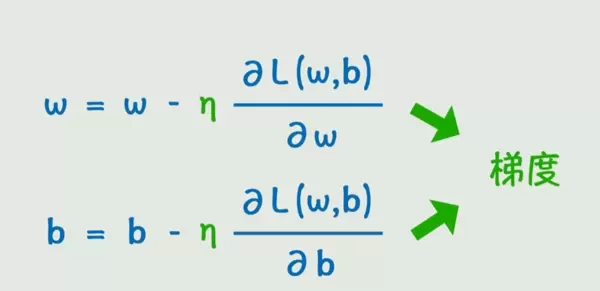
为了让模型不断优化,我们需要调整参数 w 和 b,使其朝着降低损失函数的方向更新。这一过程依赖于两个核心概念:学习率与梯度。
反向传播算法则负责计算损失函数对每一个参数的梯度,为参数更新提供方向依据。
3、调教神经网络的方法
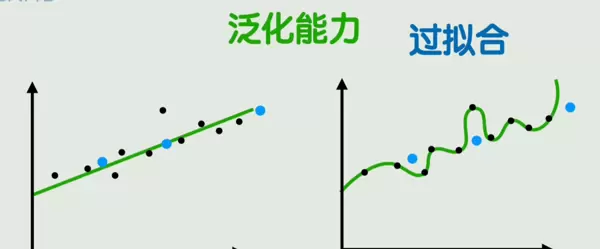
过拟合是指模型在训练数据上表现极佳,但在新样本上性能显著下降的现象。与此相对的是泛化能力,也就是模型在未见过的数据上的适应能力。
为了提升泛化性,常用策略包括数据增强——通过对原始数据进行变换生成新的训练样本,从而扩充数据集多样性。
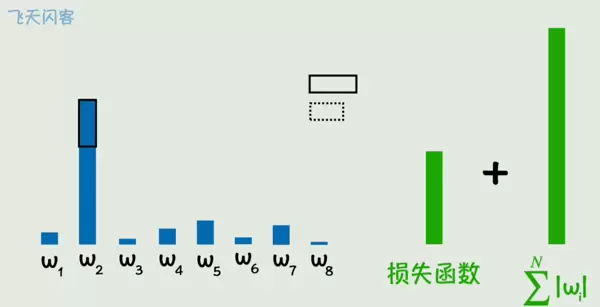
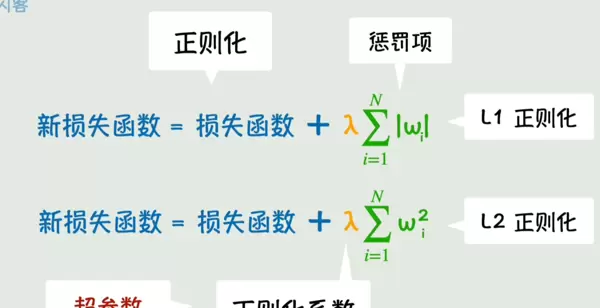
正则化方法则通过在损失函数中加入对参数大小的惩罚项,抑制参数过度增长,防止模型过于复杂。
另一种有效手段是 Dropout,它在训练过程中随机忽略部分神经元,相当于每次训练都在不同的子网络上进行,有助于减少对特定路径的依赖。

4、从矩阵到 CNN
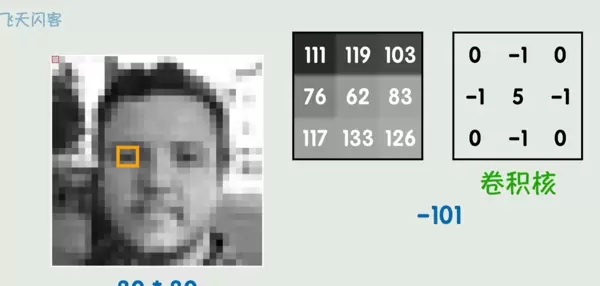
卷积神经网络(CNN)在图像处理领域表现出色,其核心操作是卷积运算。

卷积核的引入不仅大幅减少了可训练参数的数量,还能有效捕捉局部特征,如边缘、纹理等。
随后的池化层用于压缩数据维度,在保留主要特征的同时降低计算负担。
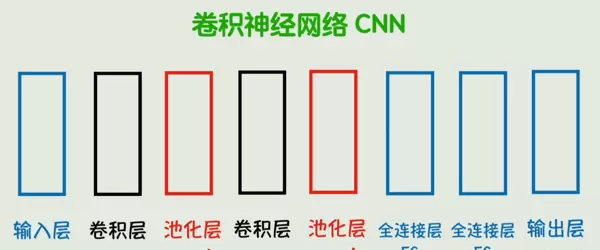
这些结构共同构成了卷积神经网络(CNN),成为处理视觉任务的重要工具。
5、从词嵌入到 RNN
为了让计算机理解自然语言,首先需要将词语转换为数值型向量,这个过程称为编码。
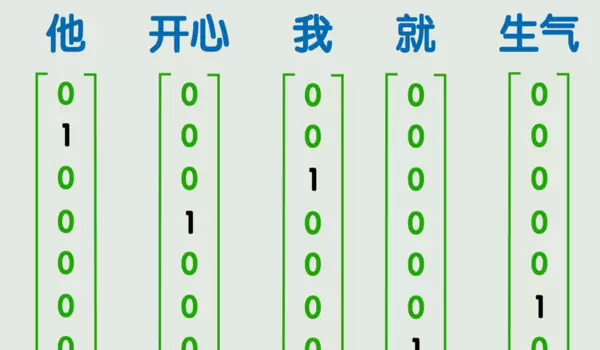
一种简单方式是 onehot 编码,但它存在高维稀疏问题,并且无法表达词与词之间的语义关联。
相比之下,词嵌入(word embedding)能将词语映射到低维稠密向量空间中,利用向量间的点积或余弦相似度衡量语义相近程度。

所有词向量组成的矩阵被称为嵌入矩阵,它是许多语言模型的基础组件。

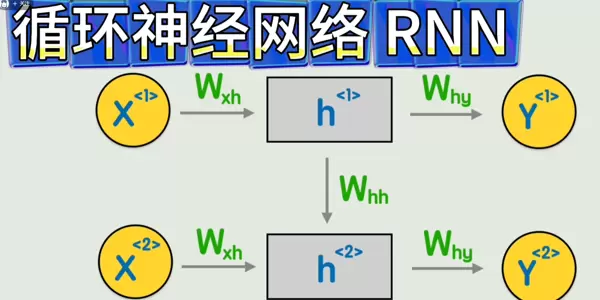
循环神经网络(RNN)在此基础上进一步建模序列信息,能够处理具有时间或顺序依赖性的文本数据。
6、简单又强大的 Transformer
Transformer 模型的核心在于注意力机制。它首先为每个词计算三个向量:查询向量(q)、键向量(k)和值向量(v)。
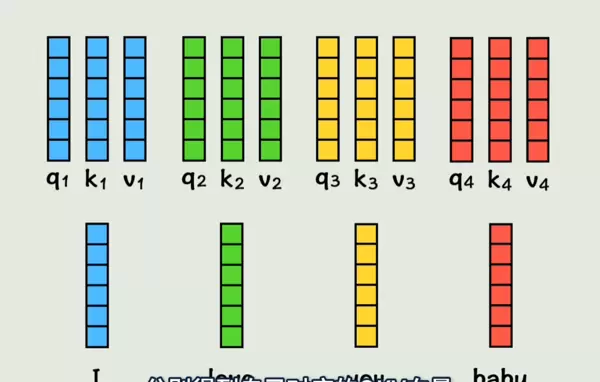
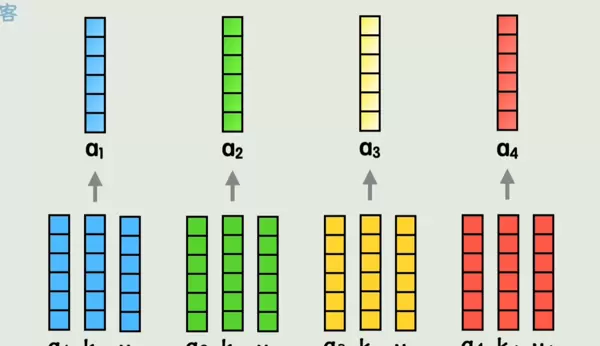
通过注意力机制,模型可以根据上下文对各个词进行加权求和,生成新的、融合了位置和语境信息的词表示。
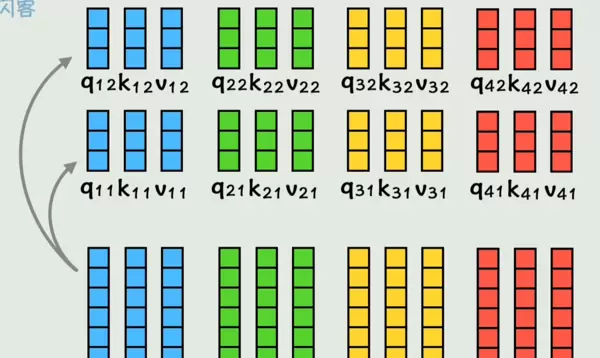
为进一步增强表达能力,多头注意力机制允许模型从不同子空间同时关注多种类型的依赖关系,即每个词会参与多个 qkv 的计算。


 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏





