过去两年,你或许频繁接触到这样的信息浪潮:
- 一台服务器售价高达300万元?只因内置8张H100 GPU。
- 训练一次大模型竟需耗费上亿人民币?
- 云计算巨头纷纷布局“算力调度”业务?
- 全球多国相继推出“AI国家战略”?
新闻中充斥着各种术语:AI、大模型、GPU、云原生……它们究竟是什么关系?是相互替代,还是存在上下游关联?能否用一句话说清楚?
不妨将当前的AI技术体系类比为一家米其林三星餐厅:
| 角色 |
对应概念 |
职责类比 |
技术定位 |
| 最终端的精美菜品 |
人工智能(AI) |
呈现的价值成果 |
应用与愿景 |
| 顶级主厨 |
大模型(LLM) |
掌握核心配方 |
智能核心 |
| 厨房炉具与自动化设备 |
GPU |
高效烹饪体系 |
算力底座 |
| 餐厅管理与食材供应系统 |
云原生(Cloud Native) |
流程调度 |
算力管理基础设施 |
一句话总纲:
GPU 提供算力 → 云原生调度算力 → 大模型实现智能 → 人工智能走向真实世界价值落地
这并非彼此竞争的技术,而是一条“垂直贯通”的技术链条。

01|GPU:深度学习时代的“暴力计算”引擎
GPU的本质,是并行算力的工业化产线。
CPU如同逻辑大师,擅长处理复杂流程,但任务吞吐量有限——串行能力强,并行能力弱。
而GPU则像一支训练有素的万人方阵,专精于同时执行海量简单的运算任务,尤其是矩阵加乘操作。
大模型训练的核心正是:
海量数据 × 矩阵乘法 × 持续迭代优化
以GPT系列模型为例:
- 参数规模可达10万亿级别
- 单次训练所需算力达ExaFLOPS级(百亿亿次浮点运算)
若使用CPU进行训练:
完成GPT-4级别的训练 ≈ 数十年等待
而采用数千张H100 GPU组成的服务器集群:
可在几周内完成训练
因此,GPU被誉为:
AI时代的“石油”
谁掌控了GPU资源,谁就掌握了智能演进的速度优势。
02|云原生:驾驭算力洪流的“控制系统”
拥有GPU,并不等于具备AI能力。它更像拥有一群难以驯服的猛兽,亟需一套精密管理系统。
面对万级GPU集群,关键问题浮现:
- 如何让10000张GPU协同工作?
- 出现硬件故障时能否自动容错?
- 如何根据负载变化动态扩缩容?
- 能否让用户像使用水电一样便捷地调用算力?
这正是云原生(Cloud Native)发挥价值的场景。
| 能力 |
核心技术 |
解决的问题 |
| 资源抽象 |
容器(Docker) |
标准化应用运行环境 |
| 智能调度 |
Kubernetes(K8s) |
决定哪块GPU何时启用、如何补位 |
| 微服务架构 |
Service Mesh |
实现复杂系统的模块化与自治 |
| 自动化DevOps |
CI/CD |
支持无中断更新和快速迭代 |
一句话概括云原生:
将分散的GPU集群整合为一个“可调度、弹性强、高可用”的超级算力工厂。
其终极目标接近于:
≈「自来水式算力」
即:随需取用、成本可控、运维简化,且规模越大越稳定。
03|大模型:从统计拟合到“智能涌现”
为何“大”才能“聪明”?
因为更多参数意味着更强的表达能力。这些参数如同神经网络中的突触连接,当数量跨越临界阈值后,便可能触发:
智能涌现(Emergent Intelligence)
也就是说,即使未被明确教导,模型也能自发掌握推理、编程、创作甚至幽默感。
| 时代 |
技术范式 |
能力 |
瓶颈 |
| 传统 AI |
规则引擎 |
仅能机械执行预设指令 |
依赖人工编写规则,扩展性差 |
| 机器学习 |
特征工程 |
特定领域表现优异 |
特征设计高度依赖专家经验 |
| 深度学习 |
神经网络 |
感知能力显著提升 |
通用理解仍不足 |
| 大模型(LLM) |
Transformer |
实现泛化与生成能力跃迁 |
算力与数据成本极高 |
大模型本质上是一种:
跨模态知识引擎 + 泛化推理系统
一旦接收人类意图,即可生成:
- 文本、图像、音频、视频
- 软件代码、数学证明
- 商业策略建议
- 科研分析报告、法律草案等专业内容
它不只是回答问题,更能代替人类完成实际任务。
04|人工智能:顶层愿景与现实世界的接口
人工智能(AI)是整个技术体系的顶层目标与最终价值出口。
它并非单一技术,而是正在重塑产业与社会的:
「智能基础设施」
典型应用场景包括:
- 医疗诊断与新药研发
- 自动驾驶系统
- 金融风控模型
- 教育辅助工具
- 公共安全应急指挥
- 工业质检与预测性维护
- 内容生成、虚拟助手、机器人控制等
AI正逐渐演变为:
如电力般普及的通用生产力技术(General Purpose Technology)
尽管当前大模型是最高效的AI实现路径,但它并非全部。AI还包括:
- 强化学习
- 多智能体系统(Agents)
- 具身智能(Embodied AI)
- 知识推理与符号逻辑体系
未来的AI不仅是“会说话的模型”,更是:
能够感知、决策并采取行动的智能体。
技术链路全景图
用最简洁的一句话总结整条技术链条:
要推动AI改变世界 → 必须依靠大模型
要运行大模型 → 必须依赖海量GPU
要高效利用GPU集群而不崩溃或过度烧钱 → 必须借助云原生
由此构成一个清晰的技术金字塔:
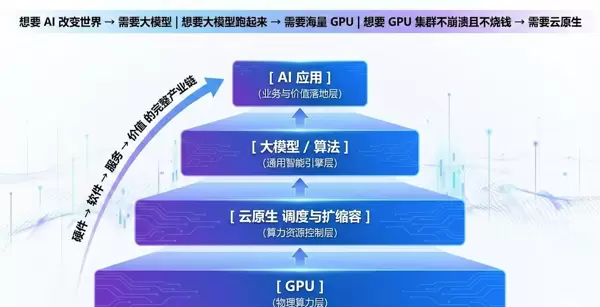
这些层次并非并列关系,而是:
从硬件 → 软件 → 服务 → 价值输出 的完整产业链条
为什么这条技术链成为国家与科技巨头的战略焦点?
因为每一层都关乎:
国家竞争力与产业主导权
| 层级 |
决定因素 |
产业战略价值 |
| GPU |
制造能力、供应链安全、自主可控 |
最易被“卡脖子”的稀缺资源 |
| 云原生 |
算力调度效率、大规模集群管理能力 |
决定算力能否成为普惠基础设施 |
| 大模型 |
算法积累、数据规模与质量 |
构建通用智能的竞争壁垒 |
| AI 应用 |
行业落地能力、生态建设 |
实现真实生产力转化的关键环节 |
总结一句:
谁掌握GPU、云原生与大模型三大支柱,谁就有能力定义AI的未来方向。
结语:驱动时代演进的底层逻辑
技术的发展从来不是孤立事件。当前我们所见的AI爆发,实则是多个层级协同进化结果。
硬件突破释放算力潜能,软件架构提升资源效率,模型创新激发智能表现,最终通过应用场景反哺社会价值。
这条垂直贯通的技术链条,正在成为新一轮科技革命的核心骨架。
当智能逐渐演变为新的基础设施,算力如同水电一般实现按需供给,模型能力也像操作系统一样普及于各类场景,这已不再是简单的工具迭代。它标志着一场生产方式的深刻跃迁。
在这场变革背后,有四大支柱支撑着人工智能的蓬勃发展:
GPU —— 提供强大的算力基础,驱动复杂计算高效运转;
云原生 —— 构建灵活的资源调度体系,保障系统稳定与弹性扩展;
大模型 —— 汇聚海量知识与智能,成为认知能力的核心载体;
AI 应用 —— 实现技术落地,将智能真正融入产业与生活。
它们共同串联起这个时代最关键的底层逻辑:
算力 → 模型 → 服务 → 价值
未来十年的竞争焦点,并不在于某个应用是否短暂走红,而在于谁能以更快的速度、更稳的架构、更低的成本,完整打通这一链条。
技术的演进从不为炫技而存在,其真正的意义,在于持续推动世界向前迈进。


 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏







