训练营介绍
2025年昇腾CANN训练营第二季正式开启,依托CANN开源开放的全场景能力,推出面向不同开发阶段人群的系列课程,涵盖零基础入门、码力强化特辑及真实开发者案例解析等内容,助力开发者高效掌握算子开发核心技术。参与并取得Ascend C算子中级认证者,将获得专属精美证书;完成社区指定任务还有机会赢取华为手机、平板、开发板等丰富奖品。

引言:AI训练中的“隐形杀手”
在人工智能模型开发过程中,“运行缓慢”尚可优化,但更令人头疼的是“计算结果错误”。尤其是在从FP32向FP16/BF16混合精度迁移时,因数值动态范围缩小,极易引发以下三类问题:
- 上溢(Overflow):数值超出最大表示范围(如超过65504),导致结果变为异常状态。
INF
下溢(Underflow):极小值被截断为0,造成梯度信息丢失。
NaN(Not a Number):出现非数字值,一旦产生便会迅速扩散至整个网络结构,引发全面失效。
INF - INF
0 / 0
尤其在拥有数百层结构的Transformer模型中,定位一次偶然出现的异常数值无异于大海捞针。本文将为你提供两套高效的排查手段——软件探针(Hooks)与硬件陷阱(Overflow Check),助你精准捕捉这些“幽灵”问题。
一、核心原理图示:追踪异常数值传播路径
精度异常往往具有瞬时性和隐蔽性——可能仅在第1000次迭代中的某个特定算子中短暂出现,却足以破坏后续所有计算流程。
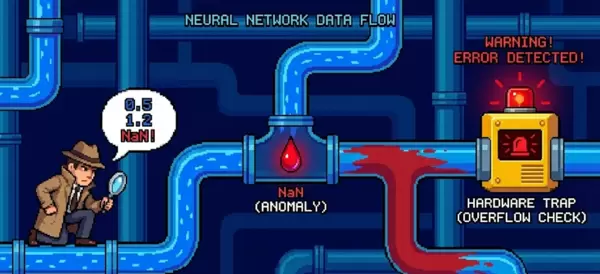
二、软件级监控:基于PyTorch Hook的实战方法
PyTorch提供了强大的钩子机制
register_forward_hook
和
register_backward_hook
,可在不修改原始模型代码的前提下,实时监控每一层模块的输入与输出张量状态。
2.1 构建“NaN检测”Hook函数
我们需要实现一个能够识别Tensor中是否存在
NaN
或
Inf
的Hook函数,用于及时发现异常数据。
import torch
def check_numerics_hook(module, inputs, outputs):
# 检查输出是否异常
# outputs 可能是 Tensor 或 Tuple
if isinstance(outputs, torch.Tensor):
tensors = [outputs]
else:
tensors = outputs
for i, t in enumerate(tensors):
if torch.isnan(t).any() or torch.isinf(t).any():
print(f" [Alert] Found NaN/Inf in module: {module.__class__.__name__}")
print(f" - Output index: {i}")
print(f" - Max: {t.max()}, Min: {t.min()}")
# 可以在这里 dump 数据以便后续分析
# torch.save(t, f"debug_{module.__class__.__name__}_out.pt")
# 激进策略:直接报错停止
raise ValueError("Numerical explosion detected!")
# 注册到模型的所有子模块
def register_hooks(model):
for name, layer in model.named_modules():
layer.register_forward_hook(check_numerics_hook)
使用方式说明:
model = MyLLM().npu()
register_hooks(model) # 注入探针
# 正常训练... 一旦出现 NaN,程序会立刻抛出异常并定位到具体 Layer
output = model(input)
三、硬件级防护:利用NPU溢出检测机制
尽管软件Hook灵活性高,但存在性能损耗,且只能观测到层间的数据流动。若算子内部中间结果发生溢出(例如
Exp
),则Hook无法捕获此类问题。
昇腾AI Core内置了浮点状态寄存器,可自动记录计算过程中的溢出事件。通过ACL接口配置,即可启用这一“硬件级异常捕获”功能。
3.1 启用溢出检测(PyTorch环境)
在
torch_npu
中设置相应的
NPU 配置项
以开启溢出检测功能。
import torch
import torch_npu
# 开启溢出检测模式
torch_npu.npu.set_compile_option(
jit_compile=False, # 建议关闭 JIT 以便更准确地定位
overflow_check=True
)
# 训练循环
try:
loss.backward()
# 在 Step 结束时检查是否溢出
if torch_npu.npu.get_npu_overflow_flag():
print("NPU Overflow detected in this step! Skipping update.")
optimizer.zero_grad() # 丢弃本次更新,防止权重被污染
# 可选:降低 Learning Rate 或调整 Loss Scale
else:
optimizer.step()
except RuntimeError as e:
print(f"Runtime Error: {e}")
3.2 进阶技巧:精确定位至具体算子
当全局检测发现存在溢出信号后,如何进一步锁定是哪个算子引发的问题?昇腾平台提供了强大的Dump功能。
可通过配置
acl.json
(或使用环境变量方式):
{
"dump": {
"dump_path": "./dump_data",
"dump_mode": "all", // dump 所有算子
"dump_op_switch": "on"
}
}
执行训练任务后,利用msprof或MindStudio工具分析Dump生成的数据,系统将自动标记出状态异常的算子节点。
四、精度对齐验证:与CPU/GPU基准结果对比
有时模型并未出现溢出,但输出结果存在偏差(例如NPU输出为3.5,而GPU为3.9),此时需进行逐层精度比对。
核心步骤:
- 固定随机种子(Seed),确保参数初始化一致。
- 使用相同的输入数据进行推理。
- 分别在CPU/GPU与NPU设备上运行模型,并通过Hook记录各层输出。
- 计算每层输出之间的Cosine Similarity或Max Diff指标。
推荐工具:
昇腾官方提供Pytorch Model Accuracy Analyzer工具(通常集成于MST即MindStudio Toolkit中),支持自动化完成上述比对流程,并生成Excel格式报告,对误差超过预设阈值(如1e-3)的层进行高亮标注。
五、总结:构建多层级精度调试体系
精度问题的排查是对开发者综合能力的全面考验。建议采用以下分层策略:
- 宏观层面:观察Loss曲线变化趋势,判断是否出现发散迹象。
- 中观层面:借助PyTorch Hook快速定位NaN首次出现的网络层级。
- 微观层面:结合NPU硬件溢出检测与Dump分析,深入挖掘算子内部异常。
- 基准参照:始终以FP32精度下的CPU/GPU运行结果作为黄金标准(Golden Data)进行校验。
掌握这套完整的“数值侦探”方法论后,面对突如其来的Loss NaN现象,你将不再惊慌失措,而是能有条不紊地追溯根源,精准定位问题所在。


 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏





