炼石成丹:大语言模型微调实战系列(三)模型评估篇
作者:AWS Team
发布日期:2024年12月23日
分类:人工智能
背景介绍
随着生成式人工智能技术的不断进步,大语言模型(LLM)在多个行业中的应用逐渐深入。然而,在模型广泛应用的同时,如何科学、有效地评估其性能成为了一个关键挑战。尤其是针对经过微调优化的模型,更需要一套系统化、可重复执行的自动化评估机制,以保障输出质量与实际表现的一致性。
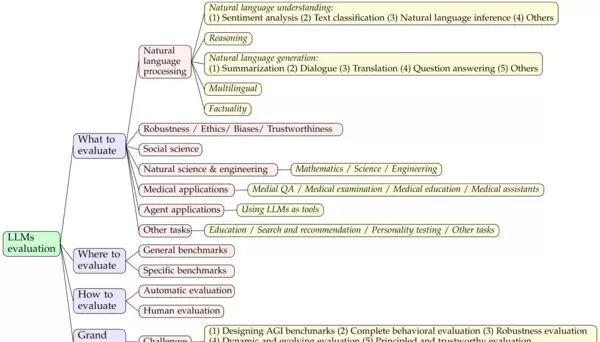
上图来源于论文《A Survey on Evaluation of Large Language Models》(https://arxiv.org/pdf/2307.03109),展示了当前大语言模型评估领域的整体结构框架。可以看出,评估体系已从最初的语言理解与生成能力,逐步扩展至涵盖鲁棒性、伦理合规性、可信度等多个维度,并进一步延伸到社会科学、自然科学、医疗健康、教育等专业应用场景中。例如数学推理、科学问答和临床辅助诊断等复杂任务,均已纳入主流评估范畴。
企业级模型评估的需求与方式
对于企业在实际研发过程中对模型进行质量把控,建立高效的评估流程至关重要。目前主流的评估方法主要分为两类:人工评估与自动评估。
人工评估虽然具备覆盖场景广、判断准确、反馈细致等优势,但存在成本高、周期长、难以规模化等问题;相比之下,自动评估具有高效、低成本、标准化程度高的特点,能够有效减少主观偏差,支持持续集成与迭代测试,更适合用于频繁更新的大模型开发流程中。

基于亚马逊云科技的自动化评估解决方案
为了帮助企业实现高效、灵活且可扩展的大语言模型自动化评估,我们构建了一套依托亚马逊云科技基础设施的整体方案。该方案通过将 Promptfoo 工具与 Amazon Bedrock 服务深度整合,实现了从数据输入、模型推理、结果评估到可视化分析的端到端自动化流程。同时,借助 Amazon Bedrock 提供的多样化基础模型选择,支持跨模型的横向对比与差异化分析。
方案执行流程
- 数据输入阶段:用户将测试数据集上传至 S3 存储桶,触发 Lambda 函数自动启动评估任务。
- 评估执行阶段:Promptfoo 从 S3 加载测试用例,调用 Amazon Bedrock 上的不同模型(如 Nova、Llama 等)进行推理并完成自动评分。
- 结果处理阶段:评估结果被自动存储并同步展示在可视化仪表板上,支持多维度的数据分析与结果比对。
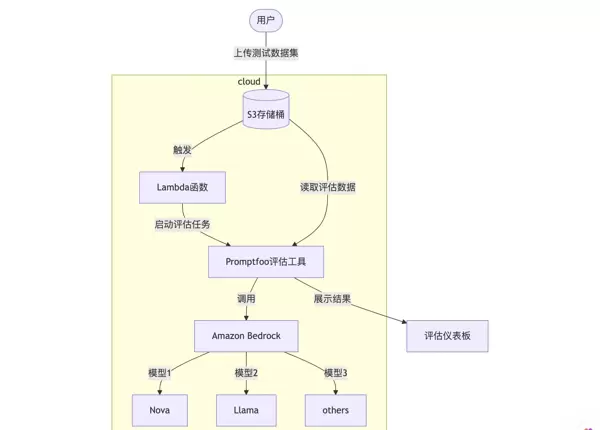
系统架构概览
本方案采用模块化设计,具备良好的可维护性和横向扩展能力。整体架构融合了对象存储、无服务器计算、安全权限管理以及机器学习服务平台,形成一个闭环的评估工作流。
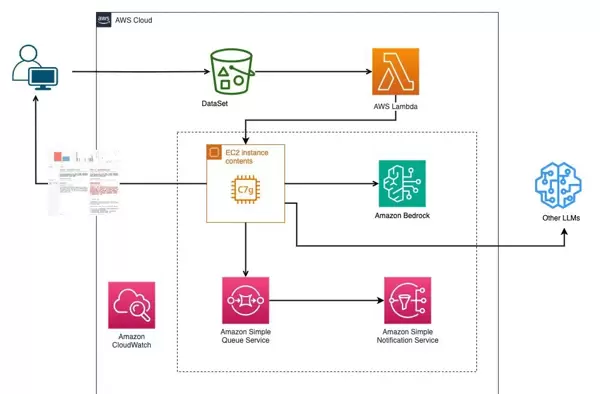
这一自动化评估框架不仅满足了企业在不同阶段对模型性能监测的需求,还提供了一个标准化、可复用的技术路径,显著提升了模型开发、调优与部署的效率。
环境部署步骤
1. 基础环境准备
使用 Amazon CloudFormation 模板一键部署所需的基础架构资源。该过程将自动配置包括 EC2 实例、IAM 角色、安全组在内的核心组件,确保运行环境的安全与稳定。
2. 项目代码获取
克隆 GitHub 上的开源项目仓库,获取完整的评估代码与配置文件:
git clone <https://github.com/tsaol/finetuning-on-aws/tree/main/model-evaluation/chatbot-evals>
cd chatbot-evals
3. 模型配置设置
以具体案例为例,我们将对两款主流大语言模型——Claude Sonnet 3.5 与 Llama 3.2 进行对比评估。以下是对应的配置示例:
providers:
- id: bedrock:anthropic.claude-3-5-sonnet-20240620-v1:0
label: sonnet 3.5
config:
region: 'us-west-2'
temperature: 0.7
max_tokens: 4096
- id: bedrock:meta.llama3-8b-instruct-v1:0
label: llama3.2 11b
config:
region: 'us-west-2'
temperature: 0.7
max_tokens: 4096
4. 测试数据集定义
测试用例可通过 CSV、JSON 或 YAML 格式进行定义。以下是一组示例 FAQ 数据,存放于项目的 dataset 目录下(详见 https://github.com/tsaol/finetuning-on-aws/blob/main/model-evaluation/chatbot-evals/dateset/faq.yaml):
- vars:
user_input: "只剩一个心脏了还能活吗?"
- vars:
user_input: "樟脑丸是我吃过最难吃的硬糖有奇怪的味道怎么还有人买"
- vars:
user_input: "马上要上游泳课了,昨天洗的泳裤还没干,怎么办"
在当前生成式人工智能快速发展的背景下,构建一个系统化、自动化的评估方案对于确保大语言模型的质量至关重要。本文介绍了一种基于亚马逊云科技平台的模型评估方法,通过设定明确的测试用例与评分标准,实现了对不同大语言模型性能的客观量化分析。
评估配置采用 YAML 格式进行定义,其中指定了使用的大语言模型及评估规则。具体配置如下:
默认测试项中设置的服务提供方为:
bedrock:anthropic.claude-3-5-sonnet-20241022-v2:0
评估断言(assert)部分采用了“llm-rubric”类型,其核心评估维度包括以下五项,每项满分为10分:
- 是否给出了合理解释
- 回答内容是否正确
- 是否符合常理
- 是否具备逻辑性
<5>是否全程使用中文作答
promptfoo eval
最终得分以各项评分的平均值作为 score,若总平均分超过9分,则判定为通过(pass 为 true)。该指标被设定为 LLM 类型的评估度量标准(metric),从而实现自动化打分与判断。
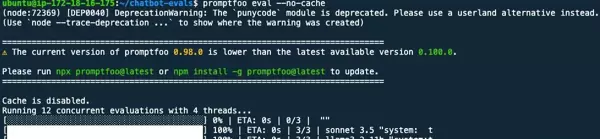
评估任务以并行方式执行推理过程。在所有推理完成后,系统将汇总结果并展示,便于进一步分析和比对。
从评估结果可以看出:
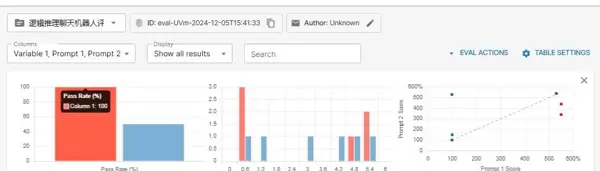
在通过率方面,Claude Sonnet 3.5 表现出色,达到100%的通过率;而 Llama 3.2 的通过率仅为50%。这一显著差异主要体现在以下几个关键维度:
响应质量对比
准确性:Claude Sonnet 3.5 在各类问题上的回答更加精准,并保持高度一致性。
逻辑性:面对复杂或需要推理的问题时,Claude Sonnet 3.5 展现出更强的逻辑推导能力。
中文表达能力:该模型能够完全使用规范中文进行输出,而 Llama 3.2 在语言流畅性和规范性上存在一定不足。
性能稳定性分析
从柱状图数据可见,Claude Sonnet 3.5 的各项得分波动较小,整体表现稳定;相比之下,Llama 3.2 在不同测试用例中的表现起伏较大,显示出较低的稳定性,有待优化。
具体用例分析

通过对未通过用例的深入分析,评估工具借助大模型自身的判断能力,清晰指出问题所在。结合可视化界面和详细的评分机制,我们能够迅速定位模型在实际应用中的薄弱环节。不仅反映出整体通过率的差距(Claude Sonnet 3.5:100%,Llama 3.2:50%),更揭示了二者在语言规范性、专业知识运用以及答案完整性等方面的深层差异。
这种系统化的评估流程使我们能够直观地识别各模型的优势与短板,为后续的模型选型与调优提供了有力支持。
结论
本次实践成功利用自动化评估工具,将传统依赖人工的主观评价转化为可重复、可量化的客观指标。通过预设测试集与标准化评分体系,全面衡量了大语言模型的实际表现。同时,依托亚马逊云科技强大的生成式 AI 能力,整个评估框架展现出良好的灵活性与扩展潜力。
该自动化评估方式不仅大幅提升了评估效率,降低了人力成本,也为企业在部署和优化大语言模型过程中提供了科学、可靠的决策依据。这也印证了开篇观点:在生成式 AI 技术迅猛发展的今天,建立一套系统化、自动化的评估机制,是保障模型质量与落地效果的关键所在。
注:上述涉及的亚马逊云科技生成式人工智能服务目前仅在海外区域提供。亚马逊云科技中国旨在帮助用户了解行业前沿技术,并为其拓展国际业务提供参考信息。
参考链接
https://arxiv.org/pdf/2307.03109
https://github.com/promptfoo/promptfoo
https://github.com/tsaol/finetuning-on-aws/tree/main/model-evaluation


 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏





