经管之家App
让优质教育人人可得
立即打开


高带宽内存(HBM)作为现代高性能计算系统中的关键技术,正在人工智能、GPU加速以及嵌入式处理领域发挥核心作用。本文为系列第二篇,深入解析HBM的技术原理、3D堆叠架构及其在先进封装中的实现方式。

随着处理器性能的飞速提升,内存带宽的增长却相对滞后,形成了所谓的“内存墙”问题。尤其是在AI和高性能计算(HPC)场景中,海量张量数据需要被快速读取与处理,传统DDR或GDDR内存因总线宽度有限且依赖高频运行,逐渐难以满足需求。
以DDR5为例,其单通道仅16位宽,即便数据速率可达4.8–6.4 GT/s,仍需多颗芯片并联才能实现高带宽;而GDDR6X虽在32位接口上达到近21–22 Gb/s每引脚速率,但随之而来的是复杂的信号完整性设计、散热压力和功耗上升。若要通过GDDR构建512 GB/s以上的带宽系统,布线复杂度将急剧增加。
面对这些挑战,行业转向了一种全新的架构思路——高带宽内存(HBM)。它摒弃了“窄总线+超高频”的路径,转而采用“超宽接口+低频运行”的设计理念。例如,HBM3支持高达1024位的数据位宽,在较低时钟频率下即可实现TB/s级别的传输速率,同时显著降低单位比特能耗,减少电磁干扰,并简化电路均衡设计。
HBM的核心技术基础是基于硅通孔(Through-Silicon Vias, TSV)的3D堆叠DRAM结构。多个DRAM裸片垂直堆叠并通过TSV实现层间互联,整体连接至一个负责调度、刷新和训练的逻辑控制层(logic die)。整个堆栈通过微凸块(microbump)集成于硅中介层(silicon interposer)之上,再与主处理器(如GPU或AI加速器)相连,形成高效的2.5D封装体系。
尽管3D堆叠概念早在2000年代初已在NAND闪存和存算一体研究中出现,但HBM是首个实现大规模商用并由JEDEC标准化的堆叠式DRAM架构。
2013年,HBM1标准正式发布,并于2015年由AMD率先应用于Fiji GPU(Radeon R9 Fury X),首次实现了在2.5D硅中介层上集成HBM模块,提供512 GB/s带宽的同时大幅降低功耗,优于同期GDDR5方案。
2016年,英伟达在其面向AI训练和HPC的Tesla P100加速卡中引入HBM2,标志着该技术向数据中心广泛应用迈出关键一步。此后,三星、SK海力士和美光持续推动HBM迭代,在堆叠层数、TSV密度和能效方面不断优化。
到2019年,HBM2E已实现单引脚速率超过3.2 Gb/s;当前主流的HBM3与HBM3E更是突破6.4 Gb/s,单个堆栈带宽可超过1 TB/s,为超级计算机、AI大模型训练平台及新一代图形处理器提供了强劲支撑。
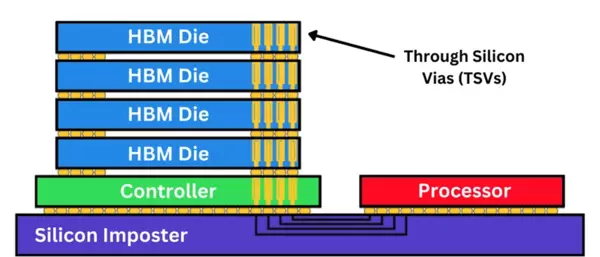
从架构角度看,HBM通过三维堆叠多个DRAM层并与底层逻辑控制器整合,构成一个高度集成的内存单元。每个堆栈通常包含4到12层DRAM芯片,借助TSV实现垂直导通,使得数据可在各层之间高效传输。
这种结构不仅极大提升了单位面积下的存储带宽,还缩短了内存与处理单元之间的物理距离,从而降低了访问延迟和功耗。由于所有连接均通过硅中介层完成,互连密度远高于传统PCB走线,进一步提升了系统的稳定性和效率。
如今,HBM已成为AI推理、机器学习训练及高端HPC集群不可或缺的组成部分。过去受限于内存带宽的计算密集型任务,如今得以充分发挥算力潜能。凭借其3D堆叠、超宽总线和低功耗特性,HBM正逐步成为未来半导体存储架构的发展方向。
高带宽内存(HBM)通过创新的3D堆叠与先进封装技术,有效解决了长期困扰计算系统的“内存墙”难题。无论是GPU、AI加速器还是嵌入式高性能平台,HBM都以其卓越的带宽表现和能效优势,成为推动下一代计算架构演进的关键力量。
每个HBM堆栈由多层DRAM芯片与一个逻辑基底裸片构成,通过微凸块和硅通孔(TSV)实现垂直互连。逻辑裸片集成了I/O接口、内存控制器、ECC(错误校正码)管理单元、刷新逻辑以及电源传输电路。在其上方通常堆叠8到12片经过减薄处理的DRAM芯片,经过精确对准与键合,形成一个三维结构的DRAM模块。
HBM堆栈提供16个独立的64位通道,支持对内存体(bank)进行细粒度访问。在HBM3中,并发能力进一步增强:每个64位通道被划分为两个32位的“伪通道”(pseudo-channel),从而实现命令流与数据流的并行处理。命令总线负责协调各类操作,而数据则通过双倍数据速率(DDR)信令在数据总线上进行传输。
尽管HBM的工作频率相对适中,但其1024位的超宽接口带来了极高的聚合带宽。以HBM3为例,在每引脚6.4 Gb/s的数据速率下,单个堆栈可实现高达819 GB/s的带宽,显著超越传统DDR5或GDDR6内存。新一代HBM3E标准由美光、三星和SK海力士联合开发,已将每引脚速率提升至9.8 Gb/s,使单堆栈带宽接近1 TB/s。这一性能突破成为AI训练、机器学习及高性能计算加速器在数据中心应用中的关键技术支撑。
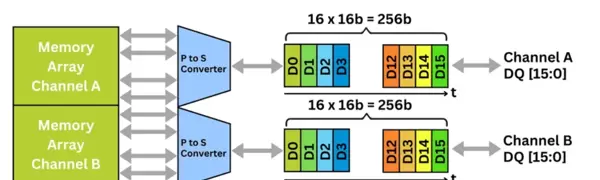
除了高带宽特性外,HBM还内置了片上ECC(错误校正码)、故障修复机制和自适应刷新功能。逻辑裸片具备屏蔽故障存储页面、重新映射有缺陷TSV的能力,并能动态调整时序参数以维持系统可靠性。其采用的解耦时钟架构允许命令总线以数据频率的一半运行,有效降低抖动并提升信号裕量——这对多堆栈、高性能系统的稳定运行至关重要。
由于HBM接口极为宽泛——每个堆栈拥有超过1000个I/O连接——传统的有机基板难以满足布线需求,长走线会引发延迟、信号损耗和串扰问题。为此,HBM采用2.5D先进封装技术,借助硅中介层(silicon interposer)实现高效互连。硅中介层具备精细金属布线层、低寄生电容和高密度TSV阵列,能够充分满足HBM对高带宽、低延迟和高信号完整性的严苛要求。
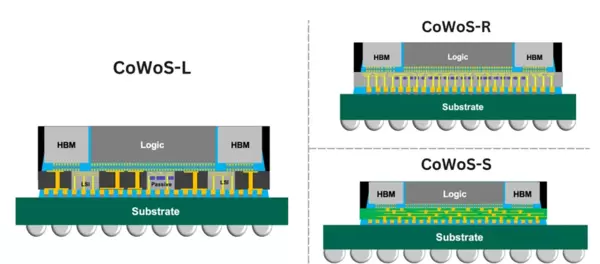
在CoWoS(Chip-on-Wafer-on-Substrate,晶圆上芯片-基板)平台上,HBM堆栈与GPU或CPU裸片共同安装在一个无源硅中介层(passive silicon interposer)上,随后该整体再贴装至有机基板。这种结构大幅缩短了芯片间的互连距离,提升了信号质量,并实现了计算单元与内存之间每秒数太比特(Tb/s)级别的通信带宽。
该技术的主要变体包括:
英特尔(Intel)提出的EMIB(Embedded Multi-Die Interconnect Bridge,嵌入式多裸片互连桥)提供了另一种技术路径。该方案将小型硅桥嵌入有机基板中,并通过微凸块连接相邻裸片。其中,EMIB-T版本还在硅桥内部集成了TSV,进一步优化供电能力和信号完整性。EMIB支持最大达120 × 180 mm的封装尺寸,凸点间距可小于45 μm,使得多芯粒(multi-tile)CPU、FPGA乃至未来的HBM4都能在紧凑空间内实现高效集成。
这些2.5D封装架构体现了逻辑芯片、存储器与互连技术的高度融合,为异构计算平台和高带宽加速器的发展奠定了坚实基础。
HBM技术已历经多代发展,各阶段关键特性如下:
展望未来,HBM5至HBM8的技术路线正在规划中,预计将持续推动带宽、能效与集成密度的提升,进一步支撑下一代人工智能与高性能计算系统的发展需求。
预计未来HBM接口位宽将扩展至4096位甚至16,384位,数据速率有望达到8–32 GT/s。新一代HBM可能集成堆栈内缓存(on-stack cache)、CXL接口,以及嵌入式NAND存储单元,从而形成多功能混合内存模块。
下表汇总了各代HBM的关键技术参数:
| 代际 | 每引脚速率 (Gb/s) | 接口位宽 | 通道数 | 单堆栈带宽 | 容量 |
|---|---|---|---|---|---|
| HBM1 | 1.0 | 1,024 位 | 8 | ~128 GB/s | 4–8 GB |
| HBM2 | 2.0 | 1,024 位 | 8 | 256 GB/s | 最高16 GB |
| HBM2E | 3.2 | 1,024 位 | 8 | 410 GB/s | 最高32 GB |
| HBM3 | 6.4 | 1,024 位 | 16 | 819 GB/s | 最高36 GB |
| HBM3E | 9.8 | 1,024 位 | 16 | ~1 TB/s | 最高36 GB |
| HBM4 | 8.0 | 2,048 位 | 32 | 2 TB/s | 最高64 GB |
HBM技术的发展路径清晰地反映出其向垂直集成、大规模并行架构和能效优化设计的演进趋势。这种转变有效缓解了人工智能、高性能计算及数据中心应用中长期存在的“内存墙”瓶颈,为下一代加速器提供了关键支撑。
在现代计算系统中实现HBM的高效集成,需要电路设计、热管理与先进封装团队的高度协同。不同于传统的GDDR或DDR分立内存,HBM通过与GPU或CPU共同部署于同一2.5D封装基板上,极大缩短了互连距离,显著提升了单位功耗下的内存带宽性能。
目前,CoWoS(Chip-on-Wafer-on-Substrate)仍是AI加速器、HPC处理器和数据中心GPU的主要集成平台。该方案将多个HBM堆栈、主处理器裸片以及其他功能芯粒(如L3缓存、I/O模块或片上网络NoP)集成在一个无源硅中介层之上。
该中介层具备超高密度金属布线能力,支持基于TSV(硅通孔)的垂直互联,并采用精细间距微凸块连接每个HBM堆栈与处理器的内存控制器。由于HBM通常采用1024至2048位的超宽接口,中介层必须在极低串扰和寄生效应条件下布设数千条信号线,对材料性能与制造精度提出严苛要求。
以AMD的MI300系列为例,其集成了多颗HBM3E堆栈与Zen 4 CPU芯粒,依赖“光罩拼接”(reticle stitching)技术来构建超出标准光刻尺寸限制的大型硅中介层——面积可达常规曝光区域的3.5倍。这一工艺突破实现了前所未有的封装规模,使异构芯粒间可达成每秒数太比特(Tb/s)的聚合带宽。
为满足高密度供电与信号传输需求,电源传输网络(PDNs)需在中介层与封装基板层面进行协同优化,为HBM、逻辑核心及PHY电路分配独立电压域。去耦电容被嵌入中介层与基板结构中,用于抑制电压跌落(voltage droop)和噪声干扰,确保在多千兆比特每秒速率下的电源稳定性和信号完整性。
三星、SK海力士和美光等主流存储厂商正与晶圆代工厂紧密协作,确保HBM3E乃至即将发布的HBM4产品在机械结构与电气特性方面完全适配CoWoS封装流程——尤其是在堆叠层数逼近12层、带宽突破1 TB/s的背景下,此类协同愈发关键。
EMIB(Embedded Multi-Die Interconnect Bridge,嵌入式多裸片互连桥)提供了一种区别于全硅中介层的替代方案。它不采用覆盖整个封装区域的硅中介层,而是将小型硅桥嵌入有机基板内部,利用微凸块连接相邻裸片,在保持高I/O密度与低延迟的同时,显著降低整体成本。
增强型EMIB-T引入了TSV结构,提升供电效率并改善电流回流路径连续性,从而支持更大规模的多芯片集成。该技术可容纳光罩尺寸级别的裸片,实现在单一有机封装内整合十余个计算或内存芯粒,并支持数百条高速I/O通道,广泛适用于高性能计算、AI加速器和数据中心级CPU等场景。
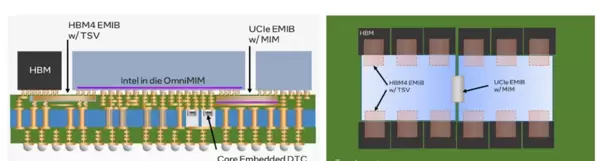
尽管EMIB在布线密度上不及CoWoS-S,但其模块化架构更利于良率控制。对于复杂SoC而言,使用全硅中介层可能导致封装尺寸过大、成本过高,而EMIB则有效缓解了这一问题。据预测,未来的英特尔至强(Intel Xeon)处理器及FPGA产品线将结合EMIB-T与HBM4技术,打造新一代异构计算平台。
高带宽内存(HBM)的核心价值在当前AI加速器、GPU与高性能计算(HPC)架构中体现得尤为突出——在这些系统中,内存带宽已成为决定整体性能的关键瓶颈。以下是几个典型应用实例:
英伟达 H100 与 H200
Hopper架构采用先进的集成设计,将一块面积约为814 mm的GPU裸片与六个16 GB的HBM3内存堆栈共同封装在CoWoS-S中介层上。HBM3以每引脚6.4 Gb/s的数据速率运行,实现高达4.9 TB/s的总带宽。如此高的内存带宽对于支撑AI训练中频繁使用的张量核心至关重要,确保了数据供给的持续性和高效性。
英伟达GH200(Grace Hopper)则进一步提升了系统整合度,将H100 GPU与基于Arm架构的Grace CPU通过高速接口连接。该平台配备六个24 GB的HBM3E堆栈,接口宽度达6144位。相较于标准HBM3,HBM3E带来超过25%的带宽提升。CPU与GPU的深度集成显著降低了计算单元和内存之间的通信延迟,优化整体系统响应速度。
AMD Instinct MI300系列提供了两种高性能变体:

美光科技已推出其36 GB容量、12层堆叠的HBM4样品,在2048位总线上以约7.85 Gb/s的速度运行,实现单模块2 TB/s的带宽——相较HBM3E提升约60%,同时能效提高20%。该产品预计于2026年进入量产阶段,并有望用于英伟达代号为“Vera Rubin”的下一代GPU平台中,助力未来AI计算的发展。
在FPGA及网络设备领域,HBM的应用也逐步扩展。赛灵思(现属AMD)在其Virtex UltraScale+ FPGA中集成了HBM,主要用于网络数据包缓存和实时分析任务,满足高吞吐场景需求。博通的Jericho3-AI网络交换芯片则配备了四组HBM3堆栈,提供强大的深度数据包缓冲能力,增强网络处理性能。
尽管HBM技术快速发展并被广泛采用,但其普及也带来了供应链压力。据路透社报道,SK海力士的HBM产品订单已排至2025年,市场需求预计将以每年约60%的速度增长。由于HBM依赖复杂的先进封装工艺(如CoWoS、EMIB),且需专用产线支持,当前全球产能仍显紧张。台积电新建的“Advanced Backend Fab 6”先进封装厂计划每年提供高达100万片晶圆的封装能力,但面对AI领域爆炸式增长的需求,这一规模可能仍显不足。
供电设计(Power Delivery)
HBM通常具备1024位或2048位宽的I/O接口,工作时会引发巨大的瞬态电流。为此,电源传输网络(PDN)必须在整个工作频段内维持极低阻抗。常见的解决方案包括在中介层与封装基板中构建高密度电源/地平面网格,并集成大容量去耦电容。例如,英特尔EMIB-T技术将金属-绝缘体-金属(MIM)电容直接嵌入硅桥结构中,有效提升供电完整性和稳定性。
热管理(Thermal Management)
堆叠式DRAM紧邻高功耗逻辑芯片,形成高度集中的热源区域。为控制温度,封装常采用蒸汽腔散热、液冷系统或分体式散热盖等方案(如英特尔EMIB-T所用设计)。此外,工程师还需考虑不同材料间的热膨胀系数差异,防止因热应力导致封装翘曲(warpage),影响可靠性。
信号完整性(Signal Integrity)
数千条并行信号线容易引发噪声耦合问题。为抑制串扰和抖动,设计中普遍采用走线长度匹配、差分信号传输、中介层内置端接电阻以及解耦时钟机制。伪通道(pseudo-channels)技术通过减小通道宽度并延长突发传输长度,也有助于改善信号质量与能效表现。
TSV良率(TSV Yield)
每片HBM DRAM包含数百个硅通孔(TSV),制造过程中任何缺陷都可能影响整体良率。为应对这一挑战,HBM引入冗余设计、ECC纠错机制以及页面屏蔽(page retirement)功能,能够在部分TSV失效的情况下仍保证模块正常运行,从而显著提升成品率。
控制器调优(Controller Tuning)
HBM内存控制器需协调多通道访问调度、预取管理及刷新操作。由于HBM支持更长的突发长度,控制器需要配置更深的数据缓冲区。同时,采用自适应刷新算法可动态调整刷新频率,降低功耗开销,提升系统能效。
供应与成本(Supply and Cost)
HBM器件价格昂贵,且受限于先进封装产能,供应周期较长。因此,工程师在项目初期就必须明确量产规划,并考虑认证多家供应商(如SK海力士、三星、美光),以分散风险,保障供应链的稳定性。
总体而言,HBM的设计要求一种系统级的协同优化策略——在功耗、散热、信号完整性与制造良率之间取得平衡,同时兼顾可扩展性与成本控制,以支撑下一代AI、高性能计算(HPC)和数据中心平台的演进。
未来的高带宽内存正从传统的存储角色向智能化、多功能化模块转变,融合计算能力、定制化功能和新型互连标准。
存内计算(PIM)革命
Processing-in-Memory(PIM)技术将计算逻辑直接嵌入DRAM内部,实现数据本地化处理。三星推出的HBM-PIM方案,在每个内存体(memory bank)中集成微型AI引擎,能够直接执行矩阵乘法、卷积运算和激活函数等常见AI任务。这种架构大幅减少了数据在处理器与内存间的搬运次数,显著提升能效比与计算吞吐量。

与传统加速器相比,HBM-PIM 能够将系统性能提升两倍以上,同时降低超过 70% 的能耗。该方案显著减少了 CPU、GPU 与内存之间的数据搬运开销,为面向 AI 训练和推理的高能效存内计算架构奠定了坚实基础。
作为 HBM4 的进一步升级版本,HBM4E 提供可定制的逻辑基底与可配置接口,能够灵活适配专用 AI 芯片及数据中心处理器的多样化需求,满足不同应用场景下的性能与集成要求。
预计于 2029 年推出的 HBM5 将实现 I/O 位宽翻倍至 4096 位,并在堆栈内部集成 L3 缓存。此外,它还将引入 CXL(Compute Express Link)以及类似 LPDDR 的接口,支持内存池化(memory pooling)功能。
为优化电气性能,HBM5 有望采用直接混合键合(direct hybrid bonding)技术替代传统的微凸块(micro-bumps),从而有效降低寄生效应,提升信号完整性与互连密度。
约在 2032 年推出的 HBM6 预计将达到每引脚 16 GT/s 的数据速率,单个堆栈带宽可达 8 TB/s。而后续的 HBM7 和 HBM8 则可能实现 DRAM 与嵌入式 NAND 闪存的深度融合,构建以内存为中心的新型系统架构,提供高达 64 TB/s 的带宽能力——这一水平将充分支撑百亿亿次级(exascale)AI 计算的发展需求。
新兴的 CoWoS-L 架构通过将硅桥嵌入有机中介层中,支持超越光罩尺寸限制的大型封装设计,实现多裸片高效互联与集成。与此同时,研究人员正积极探索“高带宽闪存”(high-bandwidth flash)技术路径,即将 HBM 与 NAND 闪存共同集成于同一中介层之上,使持久化存储更贴近计算单元,从而在未来异构计算系统中弥合内存与存储间的性能鸿沟。
HBM 凭借其超宽接口与三维堆叠结构的独特组合,在众多内存技术中占据领先地位:
DDR 与 LPDDR 具备高容量与成本优势,广泛应用于通用计算场景,如服务器 CPU、移动 SoC 等。然而其接口较窄(仅 16–32 位),速度受限(DDR5 最高约 6.4 GT/s),难以满足当前 AI 模型训练、数据中心推理或高性能计算(HPC)对超高吞吐量的需求。尽管 LPDDR5X 在能效方面有所改进,但仍无法突破带宽瓶颈。
GDDR6 与 GDDR7 将每引脚速率提升至 22–32 Gb/s,显著增强了消费级 GPU 和游戏系统的性能表现。但由于仍依赖 32 位总线,需通过多个芯片并配合复杂 PCB 布线才能达到数百 GB/s 的带宽水平。这种扩展方式增加了板级功耗、信号损耗与设计复杂度,因此主要适用于对空间与散热限制不严苛的显卡与工作站设备。
在封装内缓存内存领域,AMD 的 3D V-Cache 和英特尔的片上 SRAM 等技术可实现极低延迟的数据访问,适合将热点数据部署在计算单元附近。但其容量通常仅几十 MB,难以承担主存角色,更多是作为 HBM 的补充而非替代方案。
HBM 正好处于 GDDR 与片上缓存之间,提供一种兼具中等延迟与极高带宽的解决方案。在 HBM3E 与 HBM4 中,单堆栈容量已可达 36 至 64 GB。借助 1024 至 2048 位的超宽接口与较低工作频率,HBM 能以极高的能效实现 TB/s 级别的数据吞吐。通过将 DRAM 芯片垂直堆叠,并利用硅中介层紧邻 GPU 或 CPU 布局,HBM 显著缩短了信号路径,降低了每比特传输的功耗,同时简化了主板布线。
尽管其制造成本与集成复杂度较高,但对于 AI 加速器、高性能计算系统和数据中心处理器而言,HBM 在每瓦性能方面的卓越表现使其成为不可或缺的核心组件。
人工智能(AI)与机器学习:深度神经网络涉及大量矩阵乘法与卷积运算,HBM 的高度并行通道可高效供给张量核心与 SIMD 单元,显著减少内存停顿现象。例如训练 GPT-4 这类大型语言模型(LLM)时,每秒需处理数 TB 数据,HBM 在此类高吞吐场景中发挥关键作用。
高性能计算(HPC):在计算流体动力学、气象模拟、分子动力学等需要密集向量运算的应用中,HBM 通过为 GPU 集群提供靠近计算单元的高带宽支持,助力实现强扩展性(strong scaling)性能表现。
数据中心加速器:以 AMD MI300A 为例,其将 CPU 与 GPU 内存统一整合于单一封装中,简化编程模型的同时提升了整体效率。HBM 还被广泛用于各类 AI 推理加速器和定制化 ASIC 设计中。
网络与 FPGA 应用:博通的 Jericho3-AI 交换芯片采用 HBM 堆栈作为深度数据包缓冲区,实现确定性延迟与高吞吐能力;FPGA 则利用 HBM 加速数据分析与网络包处理任务,提升实时响应性能。
嵌入式与边缘计算:在资源受限但对能效比敏感的边缘设备中,HBM 也开始获得关注,尤其适用于需要本地高性能推理的小型化 AI 系统。
随着封装技术的进步和成本的逐步降低,高带宽内存(HBM)正加速渗透至工业级人工智能与自动驾驶系统中,在保持适中功耗的同时,提供稳定且确定性的高带宽支持。未来基于 CoWoS-L 和 EMIB-T 的先进封装方案将进一步优化空间利用率,推动芯片向更紧凑、更高集成度的方向演进。
通过融合 3D 堆叠 DRAM、硅通孔(TSV)技术以及 CoWoS、EMIB 等先进封装工艺,HBM 显著提升了 AI 加速器、高性能计算(HPC)、网络设备和嵌入式系统的数据吞吐能力,有效弥合了处理器运算速度与内存访问延迟之间的性能鸿沟,成为下一代计算架构的核心支撑之一。
要成功部署 HBM,系统架构师需与封装工程师及晶圆制造伙伴紧密协作。以下是在 AI、HPC 及数据中心应用中提升性能、可靠性与可制造性的核心实践:
在项目初期即应根据带宽需求、芯片面积限制、成本预算及供应链稳定性,在 CoWoS 的不同变体或 EMIB 技术之间做出权衡选择。所选封装形式将直接影响整体布局规划、电源网络设计以及热管理策略。
采用具备多通道均衡调度能力的内存控制器,确保事务请求均匀分布到各个物理通道及其伪通道上。合理对齐数据结构与通道边界,防止出现局部热点(hotspots),从而提升整体访问效率与寿命一致性。
利用协同仿真工具分析电源传输网络(PDN)的阻抗响应与散热表现,提前识别潜在瓶颈。针对即将普及的 HBM3E 和 HBM4 标准所带来的更高功耗密度,应在设计阶段预留足够的余量以保障长期稳定性。
激活 ECC 错误校验、页面屏蔽(page retirement)以及自适应刷新等内置功能,提升系统容错能力。持续收集错误日志与运行统计信息,有助于及时发现器件老化迹象或异常温区,实现预测性维护。
HBM 与先进封装产能目前仍相对紧张,建议尽早与供应商锁定生产配额。同时考虑引入第二来源(如三星、美光等)进行多元化采购,降低因单一供应风险导致的项目延误。
只有在架构设计、封装选型与供应链策略之间实现早期协同,才能充分释放 HBM 在带宽、能效和可靠性方面的潜力,为未来的 AI 与 HPC 平台奠定坚实基础。
HBM 已从一项前沿实验性技术发展为现代 AI、高性能计算和数据中心加速器不可或缺的关键组件。其依托 3D 堆叠结构、TSV 互连与先进封装工艺,实现了 TB/s 级别的内存带宽和卓越的每瓦性能。尽管在热管理、供电完整性和制造良率方面仍存在挑战,但随着 HBM3E、HBM4 以及存内计算(PIM)等新技术的不断演进,其扩展能力和应用场景正在持续拓展。未来结合混合中介层与计算单元深度集成的设计思路,有望进一步突破数据移动与并行处理的极限。深入掌握 HBM 的工作原理、实现路径与各项设计权衡的技术人员,将在构建下一代高带宽系统中占据主导地位。
HBM 如何满足生成式 AI 的计算需求?
A:生成式 AI 模型通常涉及大规模参数读取与频繁的数据交换,HBM 凭借其超高带宽和低延迟特性,能够快速供给海量权重与激活数据,显著缓解训练与推理过程中的内存瓶颈,尤其适用于多节点分布式场景下的高效协同。
为何高带宽对 AI 与 HPC 架构如此关键?
A:AI 与高性能计算任务高度依赖于数据流的连续供给。高带宽内存可大幅提升 CPU/GPU 与内存之间的数据传输速率,确保加速器始终处于满负荷运行状态,避免因“内存墙”问题导致算力闲置,维持高吞吐作业的持续性。
HBM 在内存容量方面相较 DDR 或 GDDR 有何优势?
A:得益于垂直堆叠的 DRAM 层结构,HBM 能在极小封装面积内集成多层存储单元,轻松实现数十 GB 至 TB 级别的内存配置,特别适合需要大内存池的 AI 训练、科学模拟和实时数据分析场景。
HBM 的内存接口设计有哪些独特之处?
A:HBM 采用 1024 位甚至 2048 位的超宽接口,支持多 Gbps 的单针脚速率下进行并行传输。这种设计无需依赖极高频率即可达成高吞吐,不仅降低了信号完整性难度,也简化了布线复杂度,并提升了整体能效比。
HBM 与传统 DDR 内存在数据速率上的差异体现在哪里?
A:当前 HBM 单引脚速率可达 6.4–9.8 Gbps,已超越 DDR5 的 6.4 GT/s 水平。更重要的是,HBM 通过 3D 堆叠与宽接口的组合,在总带宽、延迟控制和单位带宽功耗方面全面领先传统平面式内存架构。
在高性能计算领域,哪些内存技术被视为 HBM 的竞争者?
A:主要替代方案包括 GDDR6、DDR5 和新兴的 LPDDR5X。虽然 GDDR 在成本方面具有一定优势,且广泛用于消费级 GPU,但在高端 AI 加速器所需的超高带宽、大容量扩展和能效优化方面,唯有 HBM 能够全面满足严苛要求。

 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏




