在科研与管理研究领域,一个常见的现象是:即便自变量相同,其对因变量的作用强度也可能存在显著差异。这种“时强时弱”的关系背后,往往潜藏着一种关键机制——
调节变量(Moderator)。
一、理解“被影响的影响”:调节效应的核心思想
调节效应(Moderation Effect) 指的是:自变量 X 对因变量 Y 的作用会随着第三个变量 Z 的取值变化而发生改变。换句话说,调节变量并不直接决定结果,而是改变了“X 影响 Y”这一关系本身的强度或方向。
在统计建模中,这种动态关系通过引入“交互项(interaction term)”来体现。例如:
- 当“领导管理(Z)”水平较高时,“工作回报(X)”对“创新绩效(Y)”的促进作用可能更明显;
- 而在“领导管理(Z)”较低的情境下,同样的工作回报带来的激励效果则可能大打折扣。
这类依赖于情境或条件的关系模式,正是典型的调节效应表现。
二、SPSSAU 中的调节效应分析流程
SPSSAU 平台采用标准的多层回归模型逻辑进行调节效应分析,系统自动完成三步建模过程(模型1 → 模型2 → 模型3),逐步检验变量加入后的模型变化情况。
整个分析流程如下所示:
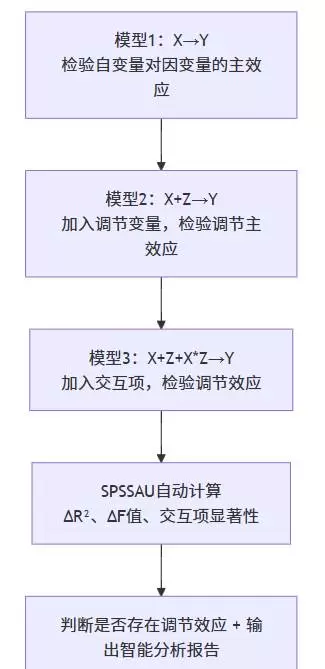
平台会在后台自动执行以下操作:
- 生成交互项(如 X*Z)并进行中心化处理;
- 计算各阶段的 ΔR、ΔF 值;
- 输出交互项的显著性结果和斜率检验报告。
用户无需手动构建公式或创建变量,所有数据预处理均由系统智能完成。
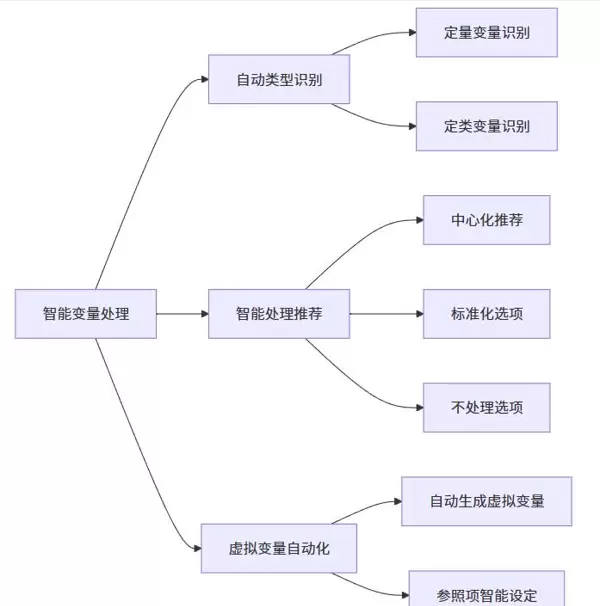
三、变量类型识别与数据处理策略
在开展调节分析前,合理的变量处理是确保结果可靠的前提。SPSSAU 提供了智能化的数据准备模块,支持用户根据实际需求选择“调节类型”和“数据处理方式”。
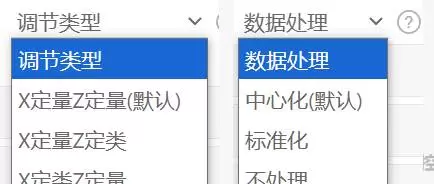
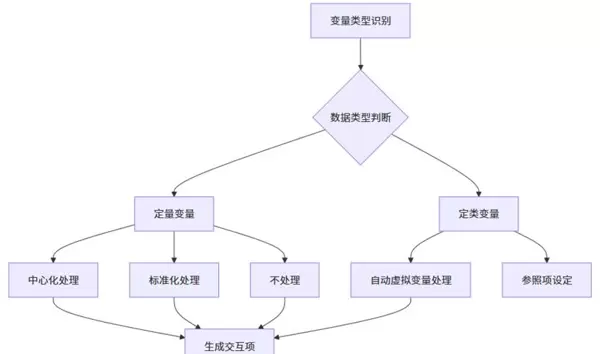
系统能够自动识别变量类别,并推荐最优处理方案。对于连续型变量,默认采用中心化处理,以降低多重共线性风险,提升回归系数解释的清晰度。
| 变量角色 |
示例 |
处理方式 |
理论说明 |
| 因变量 (Y) |
创新绩效 |
不处理 |
作为结果指标,不参与交互项构造。 |
| 自变量 (X) |
工作回报 |
若为定量 → 中心化 |
减少与其他变量间的共线性,增强解释力。 |
| 调节变量 (Z) |
领导管理 |
若为定量 → 中心化 |
有助于主效应与交互效应的独立解读。 |
| 控制变量(若有) |
— |
直接纳入模型 |
用于排除干扰因素对 Y 的直接影响,不影响交互结构。 |
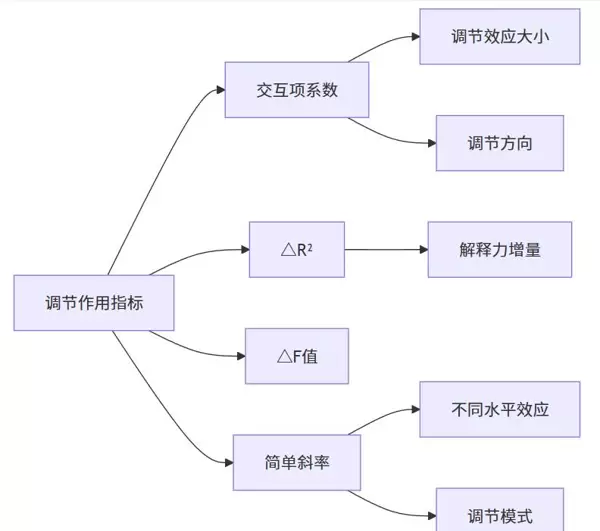
四、关键模型指标解析
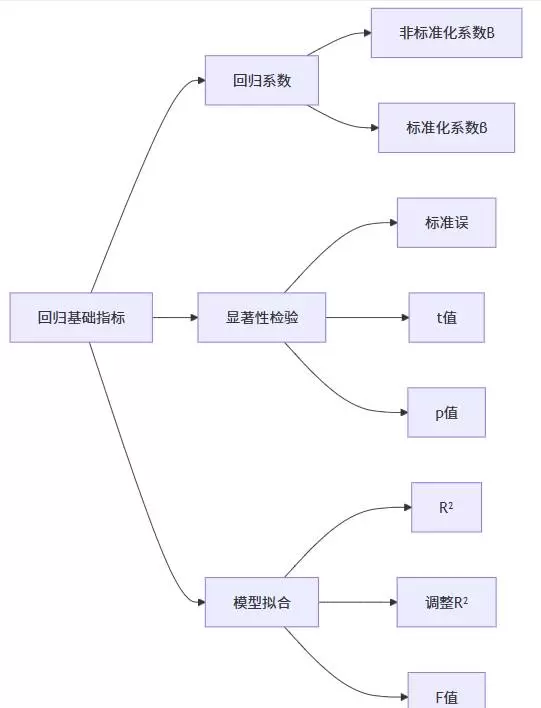
(1)基础回归指标解读
非标准化回归系数反映单位自变量变化带来的因变量实际变动量;标准化系数则消除了量纲差异,便于跨变量比较。
p 值用于判断变量影响是否具有统计显著性,是推断结论的重要依据。整体模型拟合优度(如 R)则衡量模型对数据变异的解释能力。
(2)调节效应专属指标
交互项系数(X*Z)是判断调节是否存在的重要证据,它揭示了 Z 如何改变 X 对 Y 的影响路径。
△R 和 △F 值提供了增量解释力的信息,用以评估加入交互项后模型性能是否显著提升。
当调节效应显著时,简单斜率分析进一步揭示不同 Z 水平下 X→Y 关系的具体形态。
(3)置信区间的意义
置信区间反映了参数估计的精确程度,尤其在样本较小或分布非正态时更具参考价值。Bootstrap 方法生成的置信区间稳定性更高,适用于复杂场景下的稳健推断。
(4)核心指标理论释义
| 指标 |
理论含义 |
说明 |
| R |
模型解释度 |
表示模型可解释的总方差比例,数值越高拟合越好。 |
| 调整 R |
修正后的解释度 |
考虑变量数量的影响,适合不同模型间对比。 |
| F 值 |
模型整体显著性 |
检验当前模型是否显著优于仅含截距的零模型。 |
| ΔR |
解释力度变化 |
判断新增项(如交互项)是否提升了模型解释力。 |
| ΔF |
F 值变化显著性 |
验证 ΔR 是否具有统计意义。 |
| β(标准化系数) |
路径强度 |
体现各预测变量相对影响力大小。 |
| X*Z(交互项) |
调节效应核心 |
若显著,表明 Z 调节了 X 对 Y 的影响斜率。 |
判断准则总结:
- 若模型3中交互项显著 → 存在调节效应;
- 若 ΔR 显著增加 → 加入交互项使模型更优;
- 若交互项不显著 → X 对 Y 的关系稳定,不受 Z 调节。
五、SPSSAU 的智能判断机制
除了提供原始输出表格外,SPSSAU 还集成了“智能分析模块”,基于逻辑树算法自动整合显著性结果与 ΔR 变化,生成结构化文字结论。
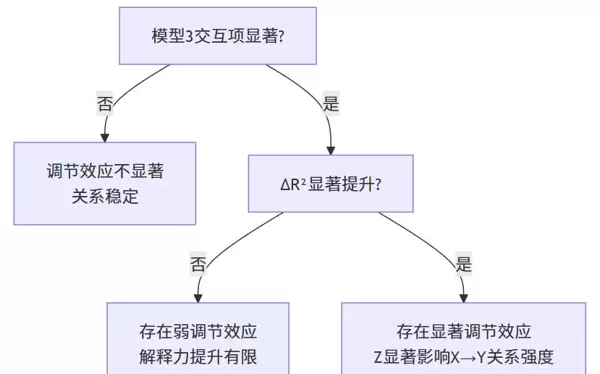
系统将自动输出类似:“交互项显著 → 支持调节效应存在”或“交互项不显著 → 不支持调节作用”等明确判断,并配套可视化图表辅助理解。
六、深入剖析:简单斜率分析的应用
当确认调节效应显著后,SPSSAU 会进一步执行简单斜率分析(simple slope analysis),即分别考察在调节变量 Z 处于高值、低值及均值水平时,X 对 Y 的影响斜率是否存在差异。
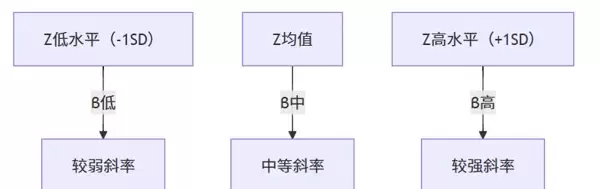
该分析帮助我们回答:在何种条件下 X 的作用更强?何时又趋于微弱?
- 若三条斜率线差异显著 → 表明 Z 确实起到了条件性调节作用;
- 若斜率接近平行 → 说明 Z 对 X→Y 关系的影响有限。
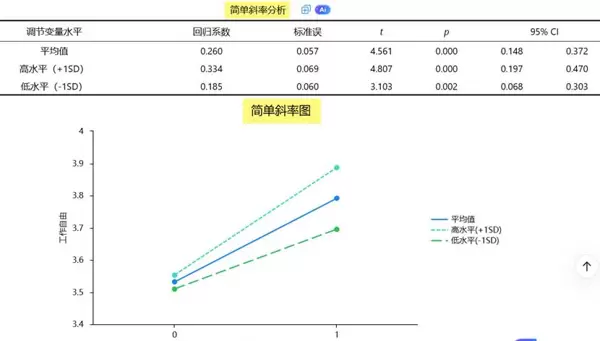
SPSSAU 自动生成“简单斜率表”与对应的“斜率图”,直观展示 X→Y 关系如何随 Z 的变化而演变。
七、构建完整逻辑链条:从变量路径到作用机制
调节效应的本质在于揭示因果路径中的“条件性”。下图概括了变量之间的内在联系:

关联逻辑说明:
- 自变量 X 直接作用于因变量 Y;
- 调节变量 Z 不直接产生结果,但会影响 X 对 Y 作用的强弱,体现出“情境依赖”的特征。
通过这一框架,研究者得以超越简单的线性关系,深入探索影响机制背后的边界条件与适用情境。
交互项(X×Z)作为连接理论与统计分析的核心纽带,在调节效应检验中发挥着关键作用;
SPSSAU 通过整合交互项系数、ΔR变化值以及简单斜率分析,实现对调节效应的多角度联合验证;
当上述三项指标均呈现显著结果时,即可支持“调节变量Z在X对Y的影响过程中起到调节作用”这一研究假设。
八、SPSSAU 在调节作用分析中的技术优势
1. 智能化的变量处理系统
SPSSAU 在变量预处理方面具备突出的技术能力,能够根据数据特征和模型需求自动推荐或执行适当的变量转换策略。
该智能化机制不仅有效降低了用户在操作过程中的技术门槛,同时也保障了分析流程符合统计学规范要求。
2. 完整的调节效应检验流程自动化
SPSSAU 实现了从建模到检验的全流程自动化支持:
- 自动模型构建:系统自动生成包含主效应与交互项的三层回归模型
- 智能效应检验:同步输出交互项显著性结果及模型拟合优度比较(如 ΔR)证据
- 全面的结果报告:涵盖基础描述统计、回归系数、效应量指标等完整分析内容
3. 面向非专业用户的友好结果解读
针对缺乏统计背景的研究者,SPSSAU 提供“智能分析”功能,以通俗语言解释复杂统计输出,帮助用户准确把握调节效应的实际含义,提升结果的理解性与应用价值。
九、调节作用分析的方法学考量
1. 中心化与标准化的选择依据
在进行调节效应建模时,变量的预处理方式应结合具体研究目标合理选择:
中心化的优势包括:
- 降低自变量与交互项之间的多重共线性问题
- 增强回归系数的可解释性
- 特别适用于基于理论假设驱动的实证研究
标准化的适用情境则主要为:
- 当变量间存在明显量纲差异时
- 需要比较不同预测变量相对影响强度的情形
- 涉及跨研究或跨样本的效应对比分析
SPSSAU 支持多种变量处理选项,使研究者可根据实际需求灵活配置。
2. 统计功效的注意事项
由于交互效应的检测通常比主效应需要更高的统计功效,因此调节效应分析往往依赖于较大的样本规模。SPSSAU 在分析过程中会提供详细的样本信息及相关统计指标,辅助研究者判断当前样本是否足以支持稳健的结论推断。
3. 简单斜率分析的深化应用
当调节效应检验结果显著时,进一步开展简单斜率分析有助于揭示调节作用的具体模式。SPSSAU 可自动计算调节变量处于不同水平(如均值、±1标准差)时的条件斜率,并结合可视化图表直观展示调节效应的变化趋势,显著提升了结果解释的清晰度与表达效率。


 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏





