经管之家App
让优质教育人人可得
立即打开


在开发基于大语言模型(LLM)的应用时,常会遇到一个棘手问题:尽管模型能够生成语法通顺、语义合理的自然语言内容,但在需要结构化数据输出的场景下却表现不稳定。即使明确指示返回JSON格式,结果仍可能出现字段遗漏、类型错误或格式不规范等情况。这类非标准的“脏数据”一旦流入下游系统,轻则造成功能异常,重则引发严重的数据污染风险。
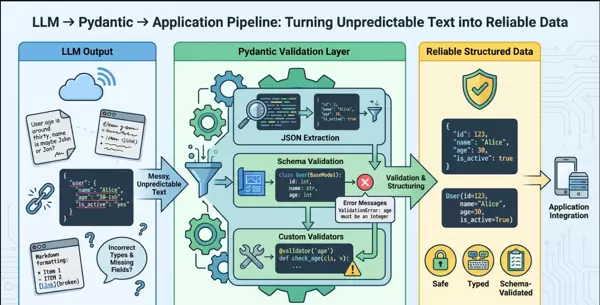
面对上述问题,Pydantic作为Python生态中最成熟的数据建模与验证工具,提供了一套高效解决方案。它不仅能定义清晰的数据契约,还能在运行时进行强制校验,成为连接LLM灵活性与系统稳定性的关键桥梁。
通过简单的类定义即可描述期望的数据结构,例如声明一个包含名称、价格和发布状态的商品模型。该模型可自动用于序列化与反序列化操作,并确保字段符合预设规则。
from pydantic import BaseModel, EmailStr, field_validator
from typing import Optional
from datetime import datetime
class UserProfile(BaseModel):
"""用户信息模型 - 基础验证示例"""
username: str # 必填字段
email: EmailStr # 邮箱格式自动验证
age: Optional[int] = None # 可选字段
created_at: datetime = Field(default_factory=datetime.now) # 默认值
@field_validator('username')
@classmethod
def validate_username(cls, v):
"""用户名自定义验证"""
if len(v) < 3:
raise ValueError('用户名至少3个字符')
if not v.isalnum():
raise ValueError('用户名只能包含字母和数字')
return v
# 测试验证
try:
user = UserProfile(
username="test123",
email="user@example.com",
age=25
)
print(f"验证通过: {user.model_dump()}")
except Exception as e:
print(f"验证失败: {e}")实践中发现,LLM在尝试输出结构化内容时常出现以下问题:
pricce代替price)import json
import re
from typing import Dict, Any
from pydantic import ValidationError
def clean_llm_response(response: str) -> Dict[str, Any]:
"""
清理LLM混乱输出的实用函数
处理场景:
1. JSON被Markdown代码块包裹
2. 包含解释性文字
3. 多个JSON片段
4. 尾部逗号等格式问题
"""
# 移除Markdown代码块标记
response = re.sub(r'```json\s*|\s*```', '', response)
# 提取第一个JSON对象
json_match = re.search(r'\{[\s\S]*?\}(?=\s*\}|\s*$)', response)
if not json_match:
raise ValueError("无法从响应中提取JSON")
json_str = json_match.group()
# 修复常见JSON格式问题
json_str = re.sub(r',\s*}', '}', json_str) # 尾部逗号
json_str = re.sub(r',\s*]', ']', json_str) # 数组尾部逗号
try:
return json.loads(json_str)
except json.JSONDecodeError as e:
# 尝试使用更宽松的解析
try:
# 使用ast.literal_eval作为备选方案
import ast
return ast.literal_eval(json_str)
except:
raise ValueError(f"JSON解析失败: {e}")
class LLMResponseHandler:
"""LLM响应处理专用类"""
@staticmethod
def safe_parse(model_class, llm_output: str, max_retries: int = 2):
"""
安全解析LLM输出,支持重试机制
Args:
model_class: Pydantic模型类
llm_output: LLM原始输出
max_retries: 最大重试次数
"""
last_error = None
for attempt in range(max_retries):
try:
# 清理和提取
cleaned_data = clean_llm_response(llm_output)
# 验证
instance = model_class(**cleaned_data)
# 验证成功
print(f"第{attempt + 1}次尝试成功")
return instance
except (ValueError, ValidationError) as e:
last_error = str(e)
print(f"第{attempt + 1}次尝试失败: {last_error}")
if attempt == max_retries - 1:
# 最后一次尝试失败
raise ValueError(f"经过{max_retries}次尝试仍无法解析: {last_error}")
return None假设需从一段电商产品介绍文本中抽取标题、价格、库存状态等关键属性。通过设计对应的Pydantic模型,在模型解析阶段即可捕获并修正大部分格式偏差,确保最终输出一致可用。
from pydantic import BaseModel, Field, validator
from typing import List, Optional
from decimal import Decimal
class ProductSpec(BaseModel):
"""商品规格"""
key: str = Field(..., min_length=1, description="规格名称")
value: str = Field(..., min_length=1, description="规格值")
unit: Optional[str] = None
class ProductReview(BaseModel):
"""商品评价"""
reviewer: str
rating: float = Field(..., ge=0, le=5, description="评分0-5分")
content: str
helpful_count: int = Field(default=0, ge=0)
is_verified: bool = False
class EcommerceProduct(BaseModel):
"""电商商品完整模型"""
product_id: str = Field(..., pattern=r'^PROD-\d{6}$')
name: str = Field(..., min_length=2, max_length=200)
category: str
price: Decimal = Field(..., gt=0)
original_price: Optional[Decimal] = None
stock: int = Field(..., ge=0)
specifications: List[ProductSpec] = Field(default_factory=list)
reviews: List[ProductReview] = Field(default_factory=list)
tags: List[str] = Field(default_factory=list)
# 计算字段
@property
def discount_rate(self) -> Optional[float]:
"""计算折扣率"""
if self.original_price and self.original_price > 0:
return float(1 - self.price / self.original_price)
return None
# 跨字段验证
@validator('original_price')
def validate_original_price(cls, v, values):
"""验证原价必须高于现价"""
if v is not None and 'price' in values:
if v <= values['price']:
raise ValueError('原价必须高于现价')
return v
@validator('reviews')
def validate_reviews_consistency(cls, v, values):
"""验证评价数据一致性"""
if v:
avg_rating = sum(r.rating for r in v) / len(v)
# 可以在此处添加更多业务逻辑验证
return v
# 使用示例
llm_product_output = """
这是一款智能手机的商品信息:
商品ID:PROD-202401
名称:旗舰智能手机X200
分类:电子产品/手机
价格:3999.00
原价:4599.00
库存:150
规格:
- 屏幕:6.7英寸,OLED
- 内存:12GB
- 存储:256GB
- 电池:5000mAh
标签:["旗舰机", "5G手机", "拍照手机"]
评价:
1. 用户:张三,评分:4.5,内容:拍照效果很棒,已验证购买
2. 用户:李四,评分:4.0,内容:电池续航满意
"""
# 解析验证过程
try:
# 首先将LLM输出转换为结构化的字典
# 这里简化处理,实际需要更复杂的解析
product_data = {
"product_id": "PROD-202401",
"name": "旗舰智能手机X200",
"category": "电子产品/手机",
"price": Decimal("3999.00"),
"original_price": Decimal("4599.00"),
"stock": 150,
"specifications": [
{"key": "屏幕", "value": "6.7英寸", "unit": "OLED"},
{"key": "内存", "value": "12", "unit": "GB"},
{"key": "存储", "value": "256", "unit": "GB"},
{"key": "电池", "value": "5000", "unit": "mAh"}
],
"reviews": [
{"reviewer": "张三", "rating": 4.5, "content": "拍照效果很棒", "is_verified": True},
{"reviewer": "李四", "rating": 4.0, "content": "电池续航满意"}
],
"tags": ["旗舰机", "5G手机", "拍照手机"]
}
product = EcommerceProduct(**product_data)
print(f"商品验证通过: {product.name}")
print(f"折扣率: {product.discount_rate:.1%}")
except ValidationError as e:
print(f"商品数据验证失败: {e}")
# 可以在这里记录错误,用于优化提示词利用LangChain提供的PydanticOutputParser和StructuredOutputParser,可以将Pydantic模型嵌入到链式调用流程中。结合提示工程引导模型按指定Schema输出,再由Pydantic执行最终验证,形成闭环控制。
from langchain_openai import ChatOpenAI
from langchain.output_parsers import PydanticOutputParser
from langchain.prompts import ChatPromptTemplate, HumanMessagePromptTemplate
from typing import Type, TypeVar
T = TypeVar('T', bound=BaseModel)
class StructuredLLMExtractor:
"""结构化LLM提取器 - 生产环境可用"""
def __init__(self, model: str = "gpt-4o-mini"):
self.llm = ChatOpenAI(
model=model,
temperature=0.1, # 较低的temperature提高确定性
max_tokens=2000
)
def extract_with_validation(
self,
text: str,
model_class: Type[T],
system_prompt: str = None,
max_retries: int = 3
) -> T:
"""
带验证的LLM信息提取
Args:
text: 待提取的文本
model_class: Pydantic模型类
system_prompt: 自定义系统提示
max_retries: 最大重试次数
"""
# 创建解析器
parser = PydanticOutputParser(pydantic_object=model_class)
# 构建提示模板
if system_prompt is None:
system_prompt = """你是一个专业的数据提取助手。
请从用户提供的文本中准确提取结构化信息。
严格按照要求的格式返回数据,不要添加任何解释性文字。"""
prompt = ChatPromptTemplate.from_messages([
("system", system_prompt),
("human", "请从以下文本中提取信息:\n\n{text}\n\n{format_instructions}")
])
# 构建处理链
chain = prompt | self.llm | parser
# 带重试的执行
last_error = None
for attempt in range(max_retries):
try:
result = chain.invoke({
"text": text,
"format_instructions": parser.get_format_instructions()
})
return result
except Exception as e:
last_error = str(e)
print(f"第{attempt + 1}次提取失败: {last_error}")
if attempt < max_retries - 1:
# 构建包含错误反馈的新提示
feedback_prompt = f"""
上次提取失败,错误信息:{last_error}
请重新分析文本并确保数据格式正确。
文本内容:{text}
"""
try:
result = self.llm.invoke([
HumanMessagePromptTemplate.from_template(
f"{system_prompt}\n\n{feedback_prompt}"
)
])
# 尝试解析响应
parsed = parser.parse(result.content)
return parsed
except Exception as retry_error:
last_error = str(retry_error)
continue
else:
raise ValueError(f"经过{max_retries}次尝试后仍失败: {last_error}")对于包含数组、嵌套对象的复杂数据结构(如商品规格表、SKU列表),可通过定义嵌套模型实现逐层校验。即使原始输出存在轻微格式偏移,也能借助类型转换机制恢复正确结构。
from pydantic import BaseModel, RootModel
from typing import Dict, List
class ResumeExperience(BaseModel):
"""工作经历"""
company: str
position: str
start_date: str
end_date: Optional[str] = None
responsibilities: List[str]
achievements: Optional[List[str]] = None
class ResumeEducation(BaseModel):
"""教育背景"""
school: str
degree: str
major: str
graduation_year: int
class ResumeSkill(BaseModel):
"""技能"""
name: str
level: str = Field(..., pattern=r"^(初级|中级|高级|专家)$")
years: Optional[int] = None
class Resume(BaseModel):
"""完整简历"""
name: str
email: str
phone: Optional[str] = None
summary: Optional[str] = None
experiences: List[ResumeExperience]
education: List[ResumeEducation]
skills: List[ResumeSkill]
# 业务逻辑验证
@validator('experiences')
def validate_experience_dates(cls, v):
"""验证工作经历时间线"""
for i, exp in enumerate(v):
if exp.end_date and exp.start_date > exp.end_date:
raise ValueError(f"第{i+1}段工作经历:开始时间不能晚于结束时间")
return v
class BatchResumeExtractor:
"""批量简历提取器"""
def __init__(self):
self.extractor = StructuredLLMExtractor()
def batch_extract(self, texts: List[str]) -> List[Resume]:
"""批量提取简历信息"""
results = []
for i, text in enumerate(texts, 1):
try:
print(f"处理第{i}份简历...")
resume = self.extractor.extract_with_validation(
text=text,
model_class=Resume,
system_prompt="你是一个专业的HR助手,从简历文本中提取结构化信息。"
)
results.append(resume)
print(f"第{i}份简历提取成功")
except Exception as e:
print(f"第{i}份简历提取失败: {e}")
# 记录失败,但不中断整个批处理
continue
return results
# 使用场景:批量处理简历文本
resume_texts = [
# 简历1文本
"张三,5年Java开发经验...",
# 简历2文本
"李四,前端工程师,React专家...",
# 更多简历...
]
extractor = BatchResumeExtractor()
resumes = extractor.batch_extract(resume_texts)
print(f"成功提取{len(resumes)}份简历信息")除了内置校验规则外,还可通过@validator装饰器添加业务层面的约束条件,例如限定价格必须大于零、校验日期区间合理性等。同时支持跨字段联合验证,增强数据完整性保障。
from pydantic import BaseModel, validator, root_validator
import re
class AdvancedValidator(BaseModel):
"""高级验证技巧示例"""
# 使用正则表达式验证
phone: str
@validator('phone')
def validate_phone_format(cls, v):
"""验证手机号格式"""
pattern = r'^1[3-9]\d{9}$'
if not re.match(pattern, v):
raise ValueError('手机号格式不正确')
return v
# 根验证器 - 验证字段间关系
price: float
discount: float
@root_validator
def validate_price_discount(cls, values):
"""验证价格和折扣的逻辑关系"""
price = values.get('price')
discount = values.get('discount')
if price and discount:
if discount > price * 0.8: # 折扣不能超过8折
raise ValueError('折扣幅度过大')
if discount < 0:
raise ValueError('折扣不能为负数')
return values
# 条件性验证
has_coupon: bool = False
coupon_code: Optional[str] = None
@validator('coupon_code')
def validate_coupon(cls, v, values):
"""如果有优惠券,必须提供优惠码"""
if values.get('has_coupon') and not v:
raise ValueError('使用优惠券时必须提供优惠码')
return vfrom functools import lru_cache
@lru_cache(maxsize=128)
def get_cached_parser(model_class):
"""缓存解析器实例,避免重复创建"""
return PydanticOutputParser(pydantic_object=model_class)import asyncio
from typing import List
async def async_batch_extract(texts: List[str], model_class) -> List:
"""异步批量提取"""
tasks = []
for text in texts:
task = asyncio.create_task(
async_extract_single(text, model_class)
)
tasks.append(task)
results = await asyncio.gather(*tasks, return_exceptions=True)
return results将验证失败情况按类型归类,如格式错误、必填缺失、类型不符、范围越界等,有助于后续分析根本原因,并针对性优化提示词或调整模型配置。
from enum import Enum
from typing import Dict, Any
class ValidationErrorType(Enum):
"""验证错误分类"""
MISSING_FIELD = "缺少必填字段"
TYPE_MISMATCH = "类型不匹配"
FORMAT_ERROR = "格式错误"
LOGIC_ERROR = "逻辑错误"
CUSTOM_VALIDATION = "自定义验证失败"
class ValidationMetrics:
"""验证指标收集"""
def __init__(self):
self.total_attempts = 0
self.success_count = 0
self.error_counts = {error_type: 0 for error_type in ValidationErrorType}
def record_attempt(self, success: bool, error_type: ValidationErrorType = None):
"""记录验证尝试"""
self.total_attempts += 1
if success:
self.success_count += 1
elif error_type:
self.error_counts[error_type] += 1
def get_success_rate(self) -> float:
"""计算成功率"""
if self.total_attempts == 0:
return 0.0
return self.success_count / self.total_attempts
def generate_report(self) -> Dict[str, Any]:
"""生成验证报告"""
return {
"total_attempts": self.total_attempts,
"success_count": self.success_count,
"success_rate": self.get_success_rate(),
"error_distribution": self.error_counts
}# 示例:验证失败告警
if validation_failure_rate > 0.1: # 失败率超过10%
send_alert("LLM输出验证失败率异常升高")随着大模型自身结构化输出能力的不断增强(如支持JSON Mode、Function Calling等),原始输出的准确性将持续提升。然而,无论技术如何进步,外部验证环节依然不可或缺。Pydantic所提供的不仅是技术工具,更体现了一种“契约优先”的工程理念——即在系统协作中,明确约定优于隐式推断。
始终牢记原则:信任但要验证(Trust but Verify)。对于LLM输出而言,这一信条尤为关键。唯有建立完善的验证体系,才能在充分发挥模型智能潜力的同时,保障系统的长期稳定运行。
在实际项目中,不少开发者倾向于过度信赖LLM的“理解能力”,忽视了最基本的数据校验步骤。这种做法如同建造高楼却不打地基——初期进展迅速,但随着时间推移,系统脆弱性逐渐暴露,维护成本急剧上升。Pydantic正是我们在与大模型协同工作时不可或缺的“安全护栏”:既允许创新自由发挥,又确保整体方向不偏离轨道。

 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏




