def process_response(response): # Scenario 1: Standard Dictionary Response if isinstance(response, dict): status = response.get("status")
if status == 200: # We have to be careful that 'data' actually exists data = response.get("data", {}) results = data.get("result", []) print(f"Success! Processed {len(results)} files.") return results
elif status == 500: error_msg = response.get("error", "Unknown Error") print(f"Failed with error: {error_msg}") return None
else: print("Unknown status code received.") return None
# Scenario 2: The Legacy List Response elif isinstance(response, list): print(f"Received legacy list with {len(response)} jobs.") return response
def process_response_modern(response): match response: # Case 1: Success (Matches specific keys AND values) case {"status": 200, "data": {"result": results}}: print(f"Success! Processed {len(results)} files.") return results
# Case 2: Error (Captures the error message and retry time) case {"status": 500, "error": msg, "retry_after": time}: print(f"Failed: {msg}. Retrying in {time}s...") return None
# Case 3: Legacy List (Matches any list of integers) case [first, *rest]: print(f"Received legacy list starting with ID: {first}") return response
# Case 4: Catch-all (The 'else' equivalent) case _: print("Invalid response format.") return None
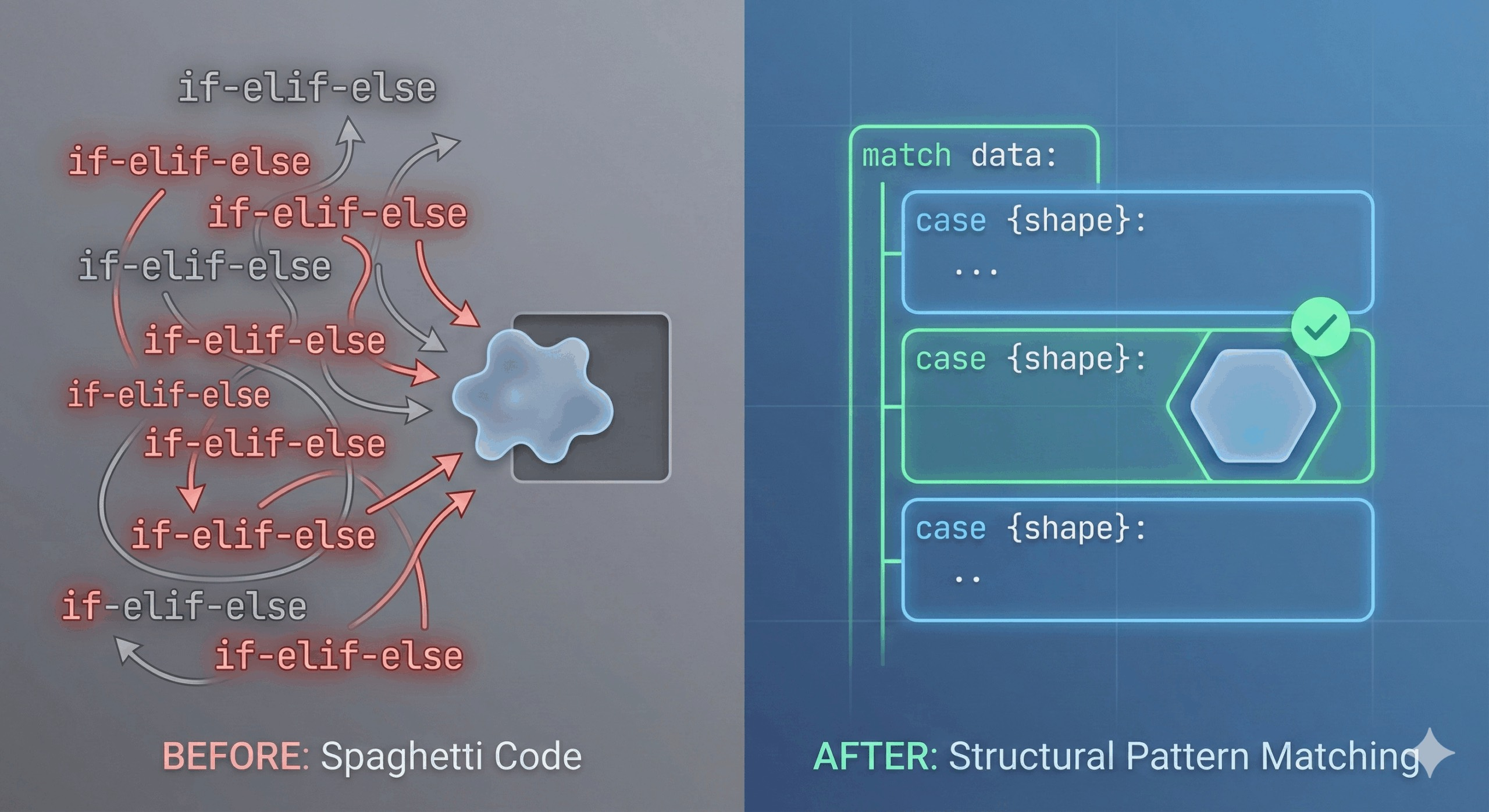
注意它比这条线短了几行,但这并不是唯一的优势。
为什么结构模式匹配如此棒
我至少能想到三个理由说明结构模式匹配能改善上述情况。matchcase
1. 隐式变量解包
注意案例1中发生的事情:
case {"status": 200, "data": {"result": results}}:


 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏