经管之家App
让优质教育人人可得
立即打开



作为一名专注于时间序列预测的数据科学家,我遇到的异常值与离群点早已数不胜数。无论是需求预测、金融、交通还是销售数据中,那些难以解释的峰值与骤降总是反复出现。
异常处理向来是一个“灰色地带”,极少非黑即白,更多是深层问题的信号。有些异常是真实的业务信号,比如节假日、天气事件、促销活动或流量爆发;另一些则只是数据故障,但二者在初次观察时看起来毫无二致。我们越早检测到数据异常,就能越快采取行动,避免模型性能下降和业务损失。
在处理关键时间序列数据时,异常检测至关重要:移除真实事件会丢失有价值的信号,保留虚假警报则会为训练数据引入噪声。
大多数基于机器学习的检测工具仅依靠Z分数、四分位距(IQR)阈值等静态方法标记峰值,完全缺乏上下文分析。借助AI领域的最新进展,我们有了更优选择——设计一款能对每个案例进行推理的异常处理智能体。该智能体可检测异常行为、核查上下文,并决定是修正数据、保留真实信号,还是标记为人工复核。
本文将分步构建这样一款智能体,它结合简单的统计检测与AI智能体,作为时间序列数据的“第一道防线”,在减少人工干预的同时,保留最关键的业务信号。我们将以新冠疫情(COVID-19)数据为研究对象,基于异常严重程度自主决策,完成异常检测与处理。核心工具与流程包括:
来自disease.sh API的实时流行病学数据;
统计异常检测算法;
异常严重程度分类;
基于GroqCloud驱动的AI智能体,自主决定:
修正异常(Fix the anomaly)
保留异常(Keep the anomaly)
标记异常供人工复核(Flag anomaly for human review)
这便是智能体决策智能,而非单纯的异常检测。
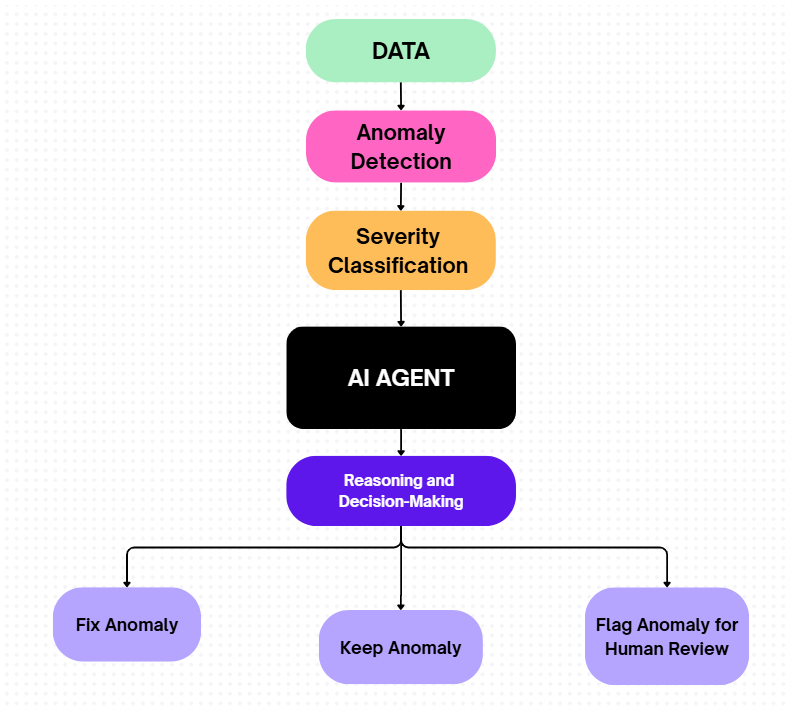
尽管孤立森林等传统机器学习方法专为异常检测设计,但它们缺乏端到端的决策编排能力,无法在生产环境中快速响应异常。我们通过实现AI智能体填补这一空白,将原始异常分数转化为针对实时数据的动态、端到端自主决策。
传统异常检测遵循以下流水线式流程:

依赖静态规则,需手动设置阈值;
单维度检测,仅适用于简单数据;
无上下文推理能力;
决策过程完全依赖人工;
后续行动需手动触发。
AI智能体驱动的异常检测遵循以下流水线式流程:

支持实时数据处理;
多维度分析,可应对复杂数据;
具备上下文推理能力;
自适应、自学习的决策机制;
可自主执行行动。
我们选用真实的新冠疫情(COVID-19)数据进行异常检测,该数据集噪声大、包含明显峰值,且分析结果对公共卫生决策具有实际意义。
核心目标是持续监控新冠疫情数据,发现异常、定义严重程度,并自主决策采取以下行动之一:
标记异常供人工复核;
修正异常数据;
保留异常信号。
本项目通过免费的disease.sh实时API获取数据,该API提供每日确诊病例、死亡病例和康复病例数据。为聚焦核心逻辑,我们仅使用每日确诊病例数这一指标,它是异常检测的理想对象。
数据许可说明:本教程使用的新冠疫情历史病例数据来自disease.sh API,底层数据集(约翰斯·霍普金斯大学系统科学与工程中心COVID-19数据仓库)采用CC BY 4.0许可协议,允许商业使用,但需注明出处。(访问时间:2026年1月22日)
基于AI智能体的新冠疫情数据异常检测系统,核心架构如下(作者配图):
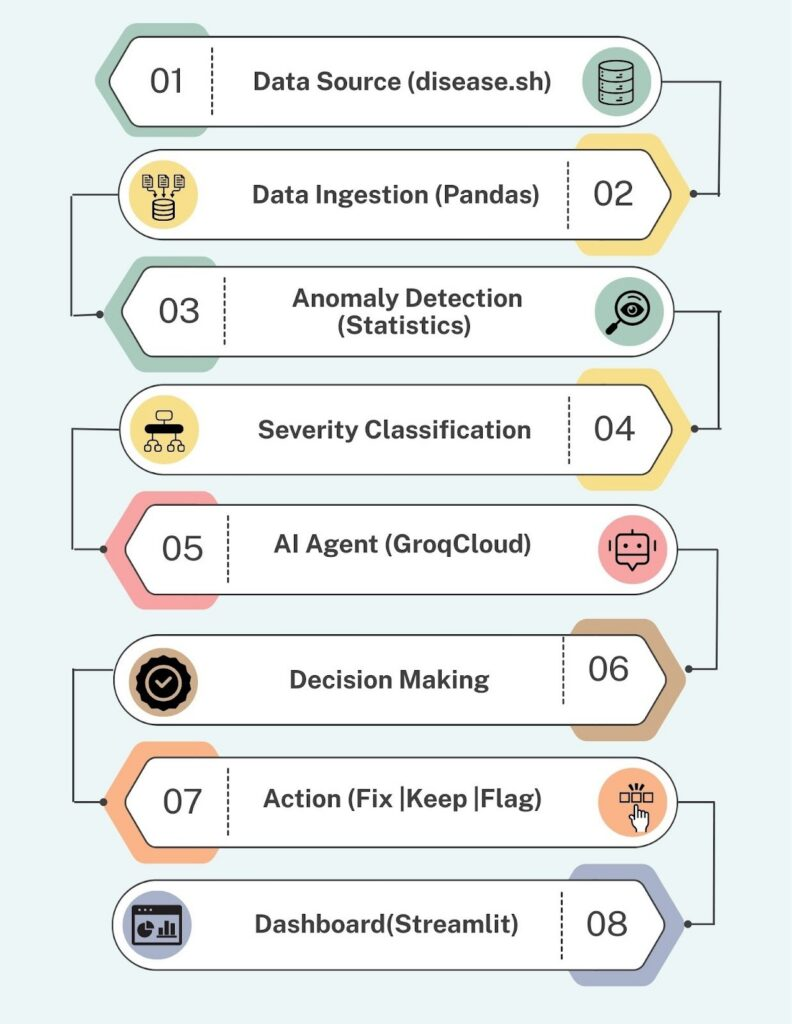
接下来,我们将逐步实现:通过disease.sh加载数据、检测异常、分类严重程度,以及构建能根据异常严重程度推理并采取适当行动的AI智能体。
首先安装phidata、groq、python-dotenv、tabulate和streamlit等核心库:
pip install phidata
pip install groq
pip install python-dotenv # 用于加载.env文件的库
pip install tabulate
pip install streamlit
在IDE中创建项目文件夹,新建.env环境文件,用于存储GROQ_API_KEY:
GROQ_API_KEY="你的Groq API密钥"
构建智能体前,需选择一个噪声足够多(能体现真实异常)且结构清晰(便于推理)的数据源。新冠每日确诊病例数完美符合要求——它包含报告延迟、突发峰值和数据分布突变。为简化演示,我们仅聚焦于单变量时间序列。
通过disease.sh的请求URL加载数据,根据选定国家和时间范围,提取日期与每日确诊病例数,将JSON数据解析为结构化Datafr ame,并格式化日期、按时间排序:
# ---------------------------------------
# 数据采集(disease.sh API)
# ---------------------------------------
import requests
import pandas as pd
def load_live_covid_data(country: str, days: int):
# 构造API请求URL
url = f"https://disease.sh/v3/covid-19/historical/{country}?lastdays={days}"
response = requests.get(url)
# 提取时间线中的病例数据
data = response.json()["timeline"]["cases"]
# 转换为Datafr ame并处理日期格式
df = (
pd.Datafr ame(list(data.items()), columns=["Date", "Cases"])
.assign(Date=lambda d: pd.to_datetime(d["Date"], format="%m/%d/%y"))
.sort_values("Date")
.reset_index(drop=True)
)
return df
我们将通过检测突发峰值和快速增长趋势,识别新冠时间序列数据中的异常行为。确诊病例数通常保持相对稳定,大幅偏离或急剧增长均意味着有意义的异常。
本步骤采用统计方法进行异常检测,并通过二元标记实现确定性、可复现的检测结果。核心计算两个关键指标:
使用Z分数检测突发峰值:若数据点超出Z分数阈值(3倍标准差),则判定为异常。
计算日环比增长率:若增长率超过40%,则标记为异常。
# ---------------------------------------
# 异常检测
# ---------------------------------------
import numpy as np
def detect_anomalies(df):
values = df["Cases"].values
mean, std = values.mean(), values.std()
# 检测峰值异常(Z分数 > 3)
spike_idx = [
i for i, v in enumerate(values)
if abs(v - mean) > 3 * std
]
# 检测增长率异常(日环比增长 > 40%)
growth = np.diff(values) / np.maximum(values[:-1], 1) # 避免除以0
growth_idx = [i + 1 for i, g in enumerate(growth) if g > 0.4]
# 合并两类异常索引
anomalies = set(spike_idx + growth_idx)
# 为Datafr ame添加异常标记列
df["Anomaly"] = ["YES" if i in anomalies else "NO" for i in range(len(df))]
return df
只要数据点满足峰值异常、增长率异常中的任意一个(或两者皆满足),Anomaly列将标记为YES,否则为NO。
并非所有异常的重要性都相同。我们将异常分为CRITICAL(严重)、WARNING(警告)、**MINOR(轻微)**三个等级,为AI智能体的决策提供依据。
分类基于固定滚动窗口和规则化阈值,且仅对已标记为异常的数据生效;非异常数据的Severity(严重程度)、Agent Decision(智能体决策)、Action(行动)列均设为空值。
# ---------------------------------------
# 配置参数
# ---------------------------------------
ROLLING_WINDOW = 7 # 7天滚动窗口
MIN_ABS_INCREASE = 500 # 最小绝对增长阈值
# ---------------------------------------
# 严重程度分类
# ---------------------------------------
def compute_severity(df):
df = df.sort_values("Date").reset_index(drop=True)
# 初始化结果列
df["Severity"] = ""
df["Agent Decision"] = ""
df["Action"] = ""
for i in range(len(df)):
if df.loc[i, "Anomaly"] == "YES":
# 数据不足7天时,暂不分类
if i < ROLLING_WINDOW:
df.loc[i, "Severity"] = ""
continue
# 计算当前值与7天基线的差异
curr = df.loc[i, "Cases"]
baseline = df.loc[i - ROLLING_WINDOW:i - 1, "Cases"].mean() # 7天均值基线
abs_inc = curr - baseline # 绝对增长
growth = abs_inc / max(baseline, 1) # 相对增长率(避免除以0)
# 绝对增长不足500时,忽略(视为无实际影响)
if abs_inc < MIN_ABS_INCREASE:
df.loc[i, "Severity"] = ""
# 相对增长率 >= 100%:严重异常(突发疫情)
elif growth >= 1.0:
df.loc[i, "Severity"] = "CRITICAL"
# 相对增长率 >= 40%:警告异常(持续增长)
elif growth >= 0.4:
df.loc[i, "Severity"] = "WARNING"
# 其他情况:轻微异常
else:
df.loc[i, "Severity"] = "MINOR"
return df
绝对增长(Absolute Growth):设置MIN_ABS_INCREASE = 500,低于该值的变化视为微小波动,避免因高百分比增长(如从1增长到2,增长率100%)产生误报,确保异常反映真实世界影响。
相对增长(Relative Growth):用于检测爆发性趋势:
增长率≥100%:判定为CRITICAL,代表突发疫情;
增长率≥40%:判定为WARNING,代表持续加速,需重点监控;
其余情况:判定为MINOR,代表轻微波动。
完成严重程度分类后,数据即可交由AI智能体进行自主决策与行动。
以下提示词定义了AI智能体的推理逻辑:当检测到异常时,基于结构化上下文和预定义的严重程度,做出确定性决策。为保障自动化安全,智能体被严格限制为仅返回三种明确行动之一。
def build_agent_prompt(obs):
return f"""
你是负责监控新冠疫情数据的AI智能体。
观测到的异常信息:
日期:{obs['date']}
确诊病例数:{obs['cases']}
严重程度:{obs['severity']}
决策规则:
- FIX_ANOMALY:异常由数据噪声、报告波动导致,需修正。
- KEEP_ANOMALY:异常是真实的疫情爆发信号,需保留。
- FLAG_FOR_REVIEW:异常严重或存在歧义,需人工复核。
请仅返回以下三个选项之一,无需额外解释:
FIX_ANOMALY
KEEP_ANOMALY
FLAG_FOR_REVIEW
"""
提示词中明确提供日期、报告病例数、严重程度三个核心数据点,帮助AI智能体做出精准的自主决策。
我们使用GroqCloud构建自主AI智能体,它能根据检测到的异常及其严重程度,进行智能上下文推理,并执行预定义的安全行动。
# ---------------------------------------
# 构建AI智能体
# ---------------------------------------
from phidata.agent import Agent
from phidata.model.groq import Groq
# 定义有效行动集合
VALID_ACTIONS = {"FIX_ANOMALY", "KEEP_ANOMALY", "FLAG_FOR_REVIEW"}
# 初始化AI智能体
agent = Agent(
name="CovidAnomalyAgent", # 智能体名称
model=Groq(id="openai/gpt-oss-120b"), # GroqCloud托管的LLM模型
instructions="""
你是监控新冠疫情实时时间序列数据的AI智能体。
请根据检测到的异常,仅从"FIX_ANOMALY"、"KEEP_ANOMALY"、"FLAG_FOR_REVIEW"中选择一个做出决策。
"""
)
# 辅助函数:构造观测数据
def build_observation(df, idx):
return {
"date": df.loc[idx, "Date"].strftime("%Y-%m-%d"),
"cases": df.loc[idx, "Cases"],
"severity": df.loc[idx, "Severity"]
}
# 遍历数据,让智能体处理异常
for i in range(len(df)):
if df.loc[i, "Anomaly"] == "YES":
# 构造观测值
obs = build_observation(df, i)
# 生成提示词
prompt = build_agent_prompt(obs)
# 运行智能体获取决策
response = agent.run(prompt)
# 解析决策(确保决策有效)
decision = response.messages[-1].content.strip()
decision = decision if decision in VALID_ACTIONS else "FLAG_FOR_REVIEW"
# 执行对应行动
df = agent_action(df, i, decision)
AI智能体仅处理Anomaly = YES的数据点,根据决策执行对应行动:
# ---------------------------------------
# 智能体行动执行器
# ---------------------------------------
def agent_action(df, idx, action):
df.loc[idx, "Agent Decision"] = action
if action == "FIX_ANOMALY":
# 修正异常数据
fix_anomaly(df, idx)
elif action == "KEEP_ANOMALY":
# 保留异常,标记为真实疫情信号
df.loc[idx, "Action"] = "Accepted as a real outbreak signal"
elif action == "FLAG_FOR_REVIEW":
# 标记为人工复核
df.loc[idx, "Action"] = "Flagged for human review"
return df
| 智能体决策(Agent Decision) | 执行行动(Action) |
|---|---|
| FIX_ANOMALY | 由AI智能体自动修正 |
| KEEP_ANOMALY | 保留,视为真实的疫情爆发信号 |
| FLAG_FOR_REVIEW | 标记,提交人工复核 |
核心逻辑:轻微异常(MINOR)由AI自动修正,有效异常(CRITICAL/KEEP)保留,严重异常(CRITICAL)标记为人工复核。
轻微异常通常由报告噪声导致,我们采用局部滚动均值平滑法,基于近期历史数据进行修正:
# ---------------------------------------
# 异常修正
# ---------------------------------------
def fix_anomaly(df, idx):
# 取异常前3天的数据计算均值
window = df.loc[max(0, idx - 3):idx - 1, "Cases"]
if len(window) > 0:
# 用均值替换异常值
df.loc[idx, "Cases"] = int(window.mean())
# 修正后清空严重程度,避免混淆
df.loc[idx, "Severity"] = ""
# 标记行动为“AI智能体自动修正”
df.loc[idx, "Action"] = "Auto-corrected by an AI agent"
该方法通过异常点前3天的病例数均值,平滑临时峰值和数据故障。修正完成后,数据点不再被视为风险点,严重程度会被清空。
统计异常检测与AI智能体处理的完整代码,请查看GitHub仓库:
https://github.com/rautmadhura4/anomaly_detection_agent/tree/main
我们以印度的新冠数据为例,展示不同严重程度异常的检测结果,以及AI智能体的处理方式。
首次实验中,系统检测到轻微异常(MINOR),AI智能体自动完成修正。以下是印度新冠数据的表格快照。
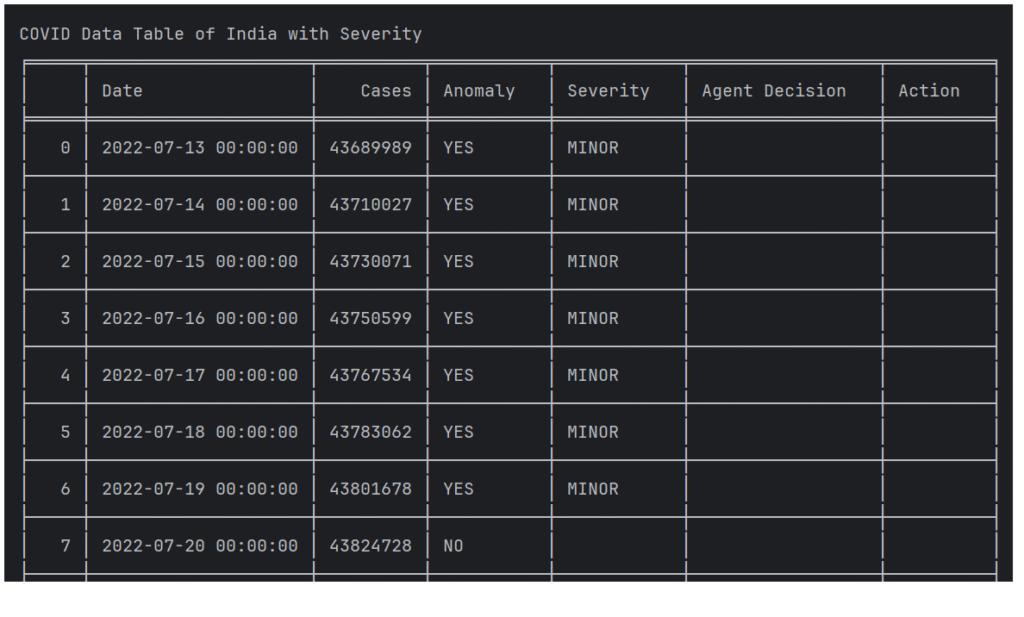
我们还实现了Streamlit仪表盘,用于复核AI智能体的决策与行动。结果显示,所有轻微异常均被成功修正。
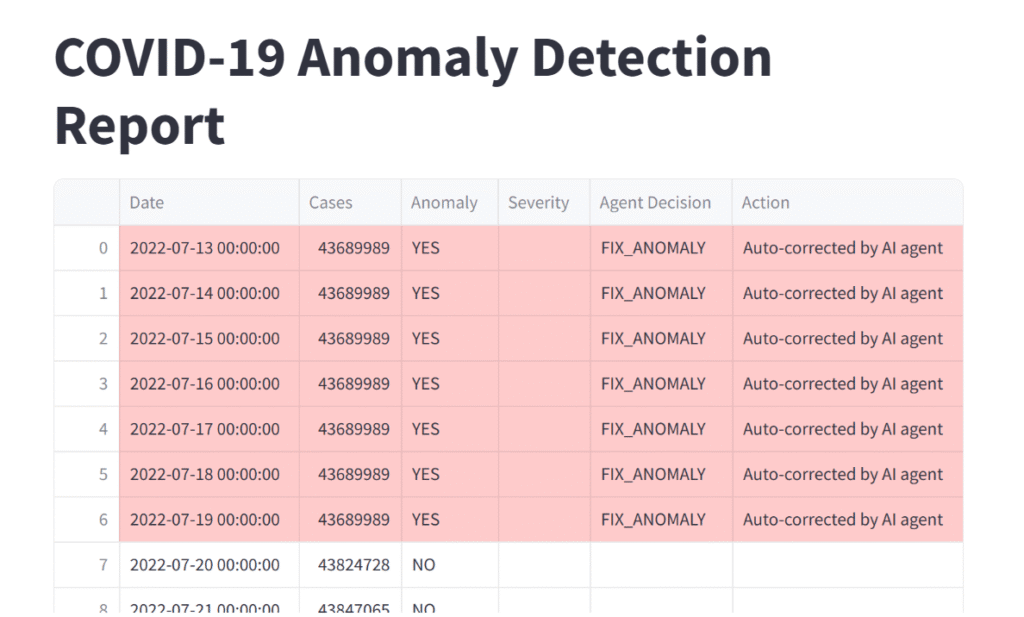
适用场景:异常为局部噪声,而非数据分布的根本性变化。
本场景检测到严重异常(CRITICAL),AI智能体将其标记为人工复核,表格快照如下。
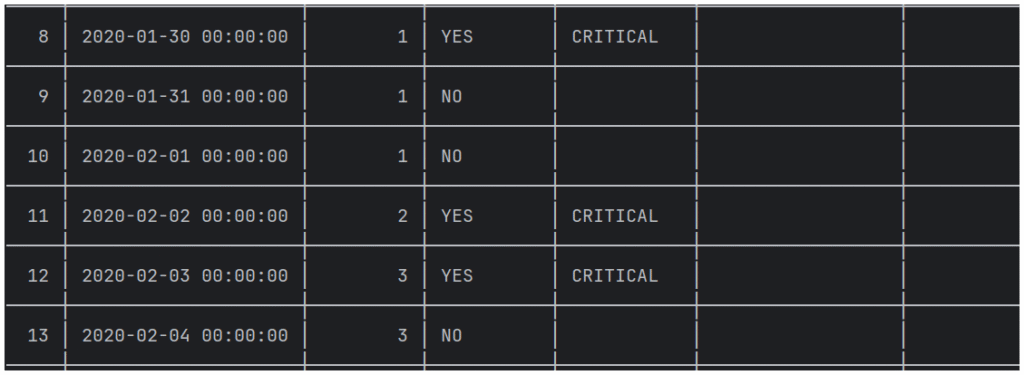
Streamlit仪表盘结果显示,所有严重异常均被正确标记,等待人工介入。
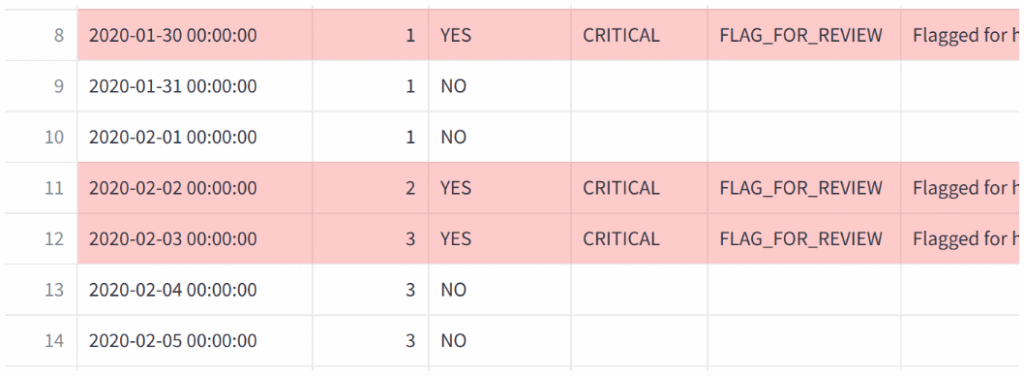
核心价值:严重程度分级避免了对高影响异常的破坏性自动修正。
本场景检测到**警告(WARNING)和严重(CRITICAL)**异常,表格快照如下。
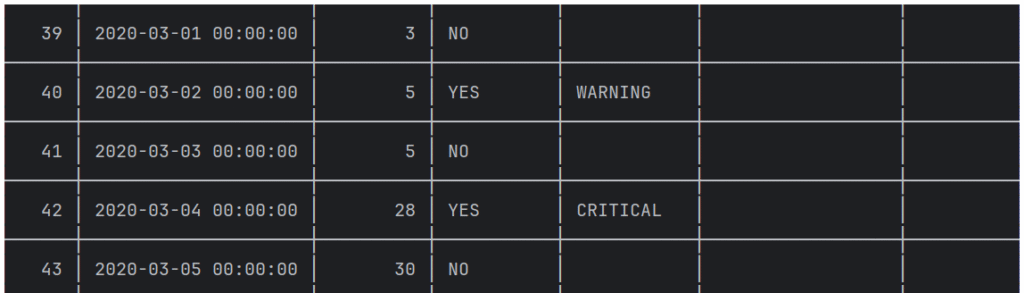
Streamlit仪表盘结果显示:严重异常被标记为人工复核,但警告异常被自动修正。
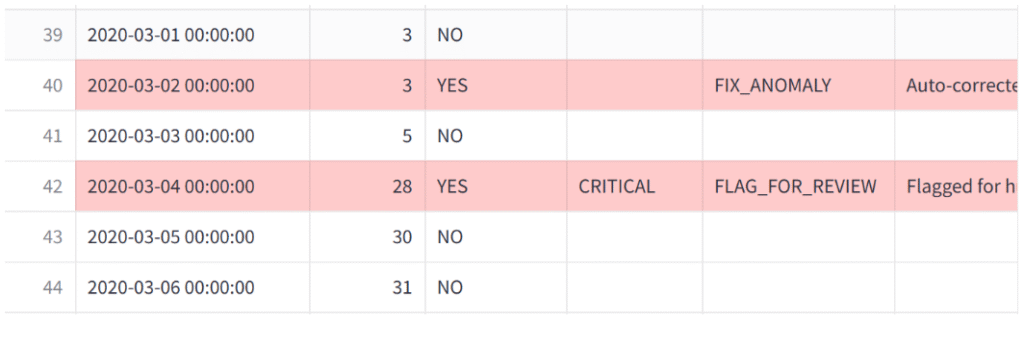
在实际业务中,警告级异常通常应被保留并监控,而非直接修正。这一问题凸显了警告阈值调优的重要性,也说明人工复核在任何场景下都不可或缺。
建议使用完整代码,调整参数后尝试对新冠数据集进行异常检测,验证不同配置的效果。
本项目使用的数据集较为有限,且异常检测基于规则实现。未来,AI智能体的实现可从以下方面优化:
数据维度扩展:目前仅基于确诊病例数决策,未来可整合住院记录、疫苗接种数据等多特征,提升决策准确性。
检测算法升级:将统计检测替换为机器学习驱动的方法(如Transformer、LSTM),识别更复杂的异常模式。
架构升级为多智能体:当前为单智能体架构,未来可实现多智能体协作,提升系统的可扩展性、清晰度和韧性。
加入人工反馈循环:引入人工复核的反馈数据,持续优化智能体的决策逻辑。
更智能的AI智能体赋能了业务级AI——它们通过上下文推理做出决策,主动修正异常,并在必要时上报人工,实现了“可控的自动化”。构建异常检测AI智能体时,需牢记以下实践要点:
采用统计方法完成基础异常检测,结合AI智能体实现上下文决策;
轻微异常(多为报告噪声)可安全自动修正;严重异常绝不能自动修正,需提交领域专家复核,避免压制真实世界信号;
该智能体不可用于异常会直接触发不可逆行动的场景(如医疗急救、金融交易);
统计方法与AI智能体的合理结合,将异常检测从“警报系统”转化为“决策驱动系统”,在保障安全性的同时,大幅降低人工成本。


 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏




