加权迭代最小二乘IRLS属于稳健回归方法,常用于样本较少的回归,IRLS属于M-Estimators,IRLS介绍如下:注意步骤,完整了解加权迭代最小二乘IRLS和软件操作!先看First文献,再看Second文献!
First,IRLS and M-Estimators Introduction based on R/Splus
重要文献如下!!!
The method of iteratively reweighted least squares (IRLS) is used to solve certain optimization problems with objective functions of the form:

By an iterative method in which each step involves solving a weighted least squares problem of the form: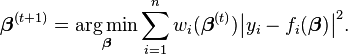
IRLS is used to find the maximum likelihood estimates of a generalized linear model, and in robust regression to find an M-estimator, as a way of mitigating the influence of outliers in an otherwise normally-distributed data set. For example, by minimizing the least absolute error rather than the least square error.
Second,IRLS Introduction based on MATLAB with two types(IRLS在MATLAB中具有两个版本:第一个版本是一般的M-Estimators的IRLS,另外一个版本是属于最优化算法的版本:基于范数和Homotopy参数选择的IRLS)
b = robustfit(X,y) returns a p-by-1 vector b of coefficient estimates for a robustmultilinear regression of the responses in yon the predictors in X. X is an n-by-p matrix of ppredictors at each of n observations. y is an n-by-1 vector of observed responses. By default, the algorithm uses iteratively reweighted least squares (IRLS) with a bisquare weighting function.
Note : By default, robustfit adds a first column of 1s to X, corresponding to a constant term in the model. Do not enter a column of 1s directly into X. You can change the default behavior of robustfit using the input const, below. Robustfit treats NaNs in X or y as missing values, and removes them. b = robustfit(X,y,wfun,tune)specifies a weighting function wfun. tune is a tuning constant that is divided into the residual vectorbefore computing weights. The weighting function wfun can be any one of thefollowing strings:

If tune is unspecified, the default value in the table is used. Default tuningconstants give coefficient estimates that are approximately 95% as statistically efficient as the ordinary least-squaresestimates, provided the response has a normal distribution with no outliers.Decreasing the tuning constant increases the downweight assigned to largeresiduals; increasing the tuning constant decreases the downweight assigned tolarge residuals.
Thevalue r in the weight functions is: r= resid/(tune*s*sqrt(1-h)). Where resid is the vector of residuals from theprevious iteration, h is the vectorof leverage values from a least-squares fit, and s is an estimate of the standard deviation of the error term givenby s = MAD/0.6745. Here MAD is the median absolute deviation of the residualsfrom their median. The constant 0.6745 makes the estimate unbiased for thenormal distribution. If there are p columns in X, the smallest pabsolute deviations are excluded when computing the median.
You can write your own weight function. The function must take a vector of scaledresiduals as input and produce a vector of weights as output. In this case, wfunis specified using a function handle @ (as in @myfun), and the inputtune is required.
b = robustfit(X,y,wfun,tune,const)controls whether or not the model will include a constant term. const is'on' to include the constant term (the default), or 'off' to omit it. When constis 'on', robustfit adds a first column of 1s to X. When const is 'off',robustfit does not alter X.
[b,stats] = robustfit(...) returns the structure stats, whose fieldscontain diagnostic statistics from the regression. The fields of stats are:
ols_s — Sigma estimate (RMSE) from ordinary least squares
robust_s — Robust estimate of sigma
mad_s — Estimate of sigma computed using the median absolute deviation ofthe residuals from their median; used for scaling residuals during iterativefitting
s — Final estimate of sigma, the larger of robust_s and a weighted averageof ols_s and robust_s
resid — Residual
rstud — Studentized residual (see regress for more information)
se — Standard error of coefficient estimates
covb — Estimated covariance matrix for coefficient estimates
coeffcorr — Estimated correlation of coefficient estimates
t — Ratio of b to se p — p-values for t
w — Vector of weights forrobust fit R — R factor in QRdecomposition of X
dfe — Degrees of freedom forerror h — Vector of leveragevalues for least-squares fit
M-Estimators的IRLS MATLAB介绍可以参见书籍:
本帖隐藏的内容
张德丰的
Matlab概率与数理统计分析
MATLAB统计分析与应用:40个案例分析
而基于范数和Homotopy参数选择的IRLS重要文献如下!以下三、四文献有重要的MATLAB代码,大家自己参考!!!按照顺序一步一步看!
Third,IRLS Introduction based on Eviews(如图)Eviews的操作这个大家自己摸索,我没有试过

选择RobustLS 的 M-Estimation
在选项里面就可以找到加权函数的类型选项了
诸如(Huber Bisquare)



 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页


 收藏
收藏













