流式计算
一、Facebook Puma
简介:实时数据流分析
二、Twitter Rainbird
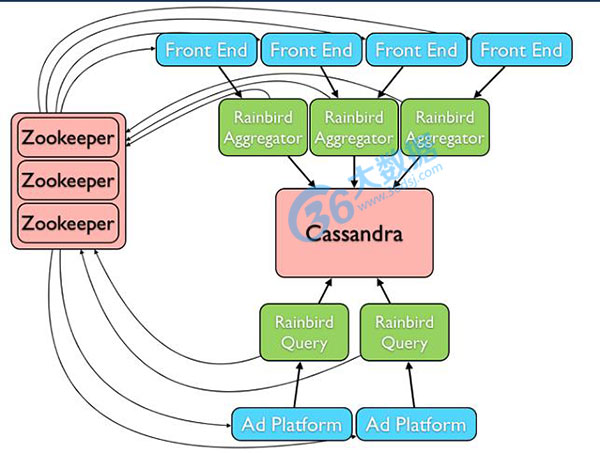
简介:Rainbird一款基于Zookeeper, Cassandra, Scribe, Thrift的分布式实时统计系统,这些基础组件的基本功能如下:
❶ Zookeeper,Hadoop子项目中的一款分布式协调系统,用于控制分布式系统中各个组件中的一致性。
❷Cassandra,NoSQL中一款非常出色的产品,集合了Dynamo和Bigtable特性的分布式存储系统,用于存储需要进行统计的数据,统计数据,并且提供客户端进行统计数据的查询。(需要使用分布式Counter补丁CASSANDRA-1072)
❸ Scribe,Facebook开源的一款分布式日志收集系统,用于在系统中将各个需要统计的数据源收集到Cassandra中。
❹ Thrift,Facebook开源的一款跨语言C/S网络通信框架,开发人员基于这个框架可以轻易地开发C/S应用。
用 处
Rainbird可以用于实时数据的统计:
❶统计网站中每一个页面,域名的点击次数
❷内部系统的运行监控(统计被监控服务器的运行状态)
❸记录最大值和最小值
三、Yahoo S4
简介:S4(Simple Scalable Streaming System)最初是Yahoo!为提高搜索广告有效点击率的问题而开发的一个平台,通过统计分析用户对广告的点击率,排除相关度低的广告,提升点击率。目前该项目刚启动不久,所以也可以理解为是他们提出的一个分布式流计算(Distributed Stream Computing)的模型。
S4的设计目标是:
·提供一种简单的编程接口来处理数据流
·设计一个可以在普通硬件之上可扩展的高可用集群。
·通过在每个处理节点使用本地内存,避免磁盘I/O瓶颈达到最小化延迟
·使用一个去中心的,对等架构;所有节点提供相同的功能和职责。没有担负特殊责任的中心节点。这大大简化了部署和维护。
·使用可插拔的架构,使设计尽可能的即通用又可定制化。
·友好的设计理念,易于编程,具有灵活的弹性
四、Twitter Storm
简介:Storm是Twitter开源的一个类似于Hadoop的实时数据处理框架,它原来是由BackType开发,后BackType被Twitter收购,将Storm作为Twitter的实时数据分析系统。
实时数据处理的应用场景很广泛,例如商品推荐,广告投放,它能根据当前情景上下文(用户偏好,地理位置,已发生的查询和点击等)来估计用户点击的可能性并实时做出调整。
storm的三大作用领域:
1.信息流处理(Stream Processing)
Storm可以用来实时处理新数据和更新数据库,兼具容错性和可扩展性,它 可以用来处理源源不断的消息,并将处理之后的结果保存到持久化介质中。
2.连续计算(Continuous Computation)
Storm可以进行连续查询并把结果即时反馈给客户,比如将Twitter上的热门话题发送到客户端。
3.分布式远程过程调用(Distributed RPC)
除此之外,Storm也被广泛用于以下方面:
迭代计算
一、Apache Hama
简介:Apache Hama是一个纯BSP(Bulk Synchronous Parallel)计算框架,模仿了Google的Pregel。用来处理大规模的科学计算,特别是矩阵和图计算。
❶建立在Hadoop上的分布式并行计算模型。
❷基于 Map/Reduce 和 Bulk Synchronous 的实现框架。
❸运行环境需要关联 Zookeeper、HBase、HDFS 组件。
Hama中有2个主要的模型:
– 矩阵计算(Matrix package)
– 面向图计算(Graph package)
二、Apache Giraph
简介:Apache Giraph是一个可伸缩的分布式迭代图处理系统,灵感来自BSP(bulk synchronous parallel)和Google的Pregel,与它们 区别于则是是开源、基于 Hadoop 的架构等。
Giraph处理平台适用于运行大规模的逻辑计算,比如页面排行、共享链接、基于个性化排行等。Giraph专注于社交图计算,被Facebook作为其Open Graph工具的核心,几分钟内处理数万亿次用户及其行为之间的连接。
三、HaLoop
简介:迭代的MapReduce,HaLoop——适用于迭代计算的Hadoop 。
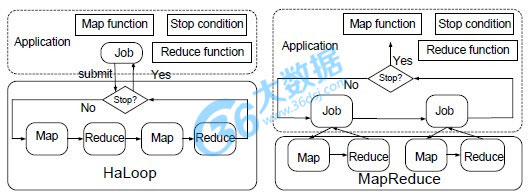
Hadoop与HaLoop的不同
与Hadoop比较的四点改变:
1.提供了一套新的编程接口,更加适用于迭代计算;
HaLoop给迭代计算一个抽象的递归公式:

2.HaLoop的master进行job内的循环控制,直到迭代计算结束;
3.Task Scheduler也进行了修改,使得任务能够尽量满足data locality
4.slave nodes对数据进行cache并index索引,索引也以文件的形式保存在本地磁盘。
四、Twister
简介:Twister, 迭代式MapReduce框架,Twister是由一个印度人开发的,其架构如下:
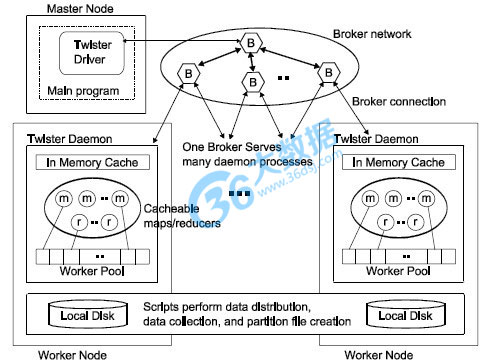
在Twister中,大文件不会自动被切割成一个一个block,因而用户需提前把文件分成一个一个小文件,以供每个task处理。在map阶段,经过map()处理完的结果被放在分布式内存中,然后通过一个broker network(NaradaBroking系统)将数据push给各个reduce task(Twister假设内存足够大,中间数据可以全部放在内存中);
在reduce阶段,所有reduce task产生的结果通过一个combine操作进行归并,此时,用户可以进行条件判定, 确定迭代是否结束。combine后的数据直接被送给map task,开始新一轮的迭代。为了提高容错性,Twister每隔一段时间会将map task和reduce task产生的结果写到磁盘上,这样,一旦某个task失败,它可以从最近的备份中获取输入,重新计算。
为了避免每次迭代重新创建task,Twister维护了一个task pool,每次需要task时直接从pool中取。在Twister中,所有消息和数据都是通过broker network传递的,该broker network是一个独立的模块,目前支持NaradaBroking和ActiveMQ。
(来源:小象学院)


 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏





