经管之家App
让优质教育人人可得
立即打开


The first part of this 2 part series expands upon a now-classic neural network blog post and demonstration, guiding the reader through the foundational building blocks of a simple neural network.
By Paul Singman, Freelance Data Scientist.
For those who do not get the reference in the title: Wedding Crashers.
For those trying to deepen their understanding of neural nets, IAmTrask’s “A Neural Network in 11 lines of Python” is a staple piece. While it does a good job–a great job even–of helping people understand neural nets better, it still takes significant effort on the reader’s part to truly follow along.
My goal is to do more of the work for you and make it even easier. (Note: You still have to exert mental effort if you actually want to learn this stuff, no one can replace that process for you.) However I will try to make it as easy as possible. How will I do that? Primarily by taking his code and printing things, printing all the things. And renaming some of the variables to clearer names. I’ll do that too.
Link to my code: what I call the Annotated 11 line Neural Network.
First, let’s take a look at the inputs for out neural network, and the output we are trying to train it to predict:
+--------+---------+ | Inputs | Outputs | +--------+---------+ | 0,0,1 | 0 | | 0,1,1 | 0 | | 1,0,1 | 1 | | 1,1,1 | 1 | +--------+---------+Those are our inputs. As Mr. Trask points out in his article, notice the first column of the input data corresponds perfectly to the output. This does make this “classification task” trivial since there’s a perfect correlation between one of the inputs and the output, but that doesn’t mean we can’t learn from this example. It just means we should expect the weight corresponding to the first input column to be very large at the end of training. We’ll have to wait and see what the weights on the other inputs end up being.
In Mr. trask’s 1-layer NN, the weights are held in the variable syn0 (synapse 0). Read about the brain to learn why he calls them synapses. I’m going to refer to them as the weights, however. Notice that we initialize the weights with random numbers that are supposed to have mean 0.
Let’s take a look at the initial values of the weights:
weights: [[ 0.39293837 ] [-0.42772133] [-0.54629709]]We see that they, in fact, do not have a mean of zero. Oh well, c’est la vie, the average won’t come out to be exactly zero every time.
Generating Our First Predictions
Let’s view the output of the NN variable-by-variable, iteration-by-iteration. We start with iteration #0.
---------ITERATION #0------------- inputs: [[0 0 1] [0 1 1] [1 0 1] [1 1 1]]Those are our inputs, same as from the chart above. They represent four training examples.
The first calculation we perform is the dot product of the inputs and the weights. I’m a crazy person (did I mention that?) so I’m going to follow along and perform this calculation by hand.
We’ve got a 4×3 matrix (the inputs) and a 3×1 matrix (the weights), so the result of the matrix multiplication will be a 4×1 matrix.
We have:
(0 * .3929) + (0 * -.4277) + (1 * -.5463) = -.5463 (0 * .3929) + (1 * -.4277) + (1 * -.5463) = -.9740 (1 * .3929) + (0 * -.4277) + (1 * -.5463) = -.1534 (1 * .3929) + (1 * -.4277) + (1 * -.5463) = -.5811I’m sorry I can’t create fancy graphics to show why those are the calculations you perform for this dot product. If you’re actually following along with this article, I trust you’ll figure it out. Read about matrix multiplication if you need more background.
Okay! We’ve got a 4×1 matrix of dot product results and if you’re like me, you probably have no idea why we got to where we’ve gotten, and where we’re going with this. Have patience for a couple more steps and I promise I’ll guide us to a reasonable “mini-result” and explain what just happened.
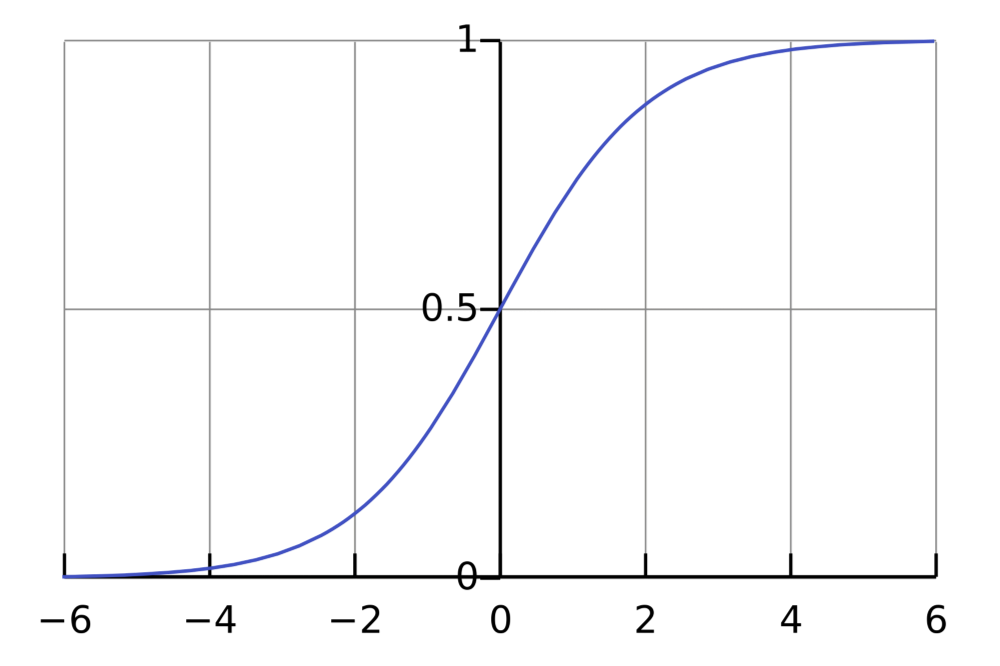
The next step according to the code is to send the four values through the sigmoid function. The purpose of this is to convert the raw numbers into probabilities (values between 0 and 1). This is the same step logistic regression takes to provide its classification probabilities.
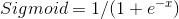
Element-wise, as it’s called in the world of matrix operations, we apply to the sigmoid function to each of the four results we got from the matrix multiplication*. Large values should be transformed close to 1. Large negative values should be transformed to something close to 0. And numbers in between should take on a value in between 0 and 1!
*I’m using the terms matrix multiplication and dot product interchangeably here.
Although I calculated the results of applying the sigmoid function “manually” in Excel, I’ll defer to the code results for this one:
dot product results: [[-0.54629709] [-0.97401842] [-0.15335872] [-0.58108005]] probability predictions (sigmoid): [[ 0.36672394] [ 0.27408027] [ 0.46173529] [ 0.35868411]]So we take the results of the dot product (of the initial inputs and weights) and send them through the sigmoid function. The result is the “mini-result” I promised earlier and represents the model’s first predictions.
To be overly explicit, if you take the first dot product result, -.5463 and input it as the ‘x’ in the sigmoid function, the output is 0.3667.
This means that the neural network’s first “guesses” are that the first input has a 36.67% chance of being a 1. The second input has a 27% chance, the third a 46.17% chance, and the final and fourth input a 35.86% chance.
All of our dot product results were negative, so it makes sense that all of our predictions were under 50% (a dot product result of 0 would correspond to a 50% prediction, meaning the model has absolutely no idea whether to guess 0 or 1).
To provide some context, the sigmoid is far from the only function we could use to transform the dot product into probabilities, though it is the one with the nicest mathematical properties, namely that it is differentiable and its derivative, as we’ll see later, is mind-numbingly simple.

Calculator Error and Updating Weights
We’ve generated our first predictions. Some were right, some were wrong. Where do we go from here? As I like to say, we didn’t get this far just to get this far. We push forward.
The next step is to see how wrong our predictions were. Before your mind thinks of crazy, complicated ways to do that, I’ll tell you the (simple) answer. Subtraction.
y: [[0] [0] [1] [1]] l1_error: [[-0.36672394] [-0.27408027] [ 0.53826471] [ 0.64131589]]The equation to get l1_error is y – probability predictions. So for the first value it is: 0 – .3667 = -.3667. Simple, right?
Unfortunately, it’s going to get a little more complicated from here. But I’ll tell you upfront what our goals are so what we do makes a little more sense.
What we’re trying to do is update the weights so that the next time we make predictions, there is less error.
The first step for this is weighting the l1_error by how confident we were in our guess. Predictions close to 0 or 1 will have small update weights, and predictions closer to 0.5 will get updated more heavily. The mechanism we use to come up with these weights is the derivative of the sigmoid.
sigmoid derivative (update weight): [[ 0.23223749] [ 0.19896028] [ 0.24853581] [ 0.21876263]]Since all of our l1 predictions were relatively unconfident, the update weights are relatively large. The most confident prediction was that the second training example was not a one (only a 19.89% chance of being a one), so notice that it has the smallest update weight.
The next step is to multiply the l1_errors by these weights, which gives us the following result that Mr Trask calls the l1_delta:
l1 delta (weighted error): [[-0.08516705] [-0.05453109] [ 0.13377806] [ 0.14752178]]Now we’ve reached the final step. We are ready to update the weights. Or at least I am.
We update the weights by adding the dot product of the input values and the l1_deltas.
Let’s go through this matrix multiplication manually like we did before.
The input values are a 4×3 matrix. The l1_deltas are a 4×1 matrix. In order to take the dot product, we need the No. of columns in the first matrix to equal the No. rows in the second. To make that happen, we take the transpose of the input matrix, making it a 3×4 matrix.
Original inputs: [[0 0 1] [0 1 1] [1 0 1] [1 1 1]]We’re multiplying a 3×4 matrix by a 4×1, so we should end up with a 3×1 matrix. This makes sense since we have 3 weights we need to update. Let’s begin the calculations:
(0 * -.085) + (0 * -.055) + (1 * .134) + (1 * .148) = 0.282(0 * -.085) + (1 * -.055) + (0 * .134) + (1 * .148) = 0.093(1 * -.085) + (1 * -.055) + (1 * .134) + (1 * .148) = 0.142Okay! The first row must correspond to the update to the first weight, the second row to the second weight, etc. Unsurprisingly, the first weight (corresponding to the first column of inputs that is perfectly correlated with the output) gets updated the most, but let’s better understand why that is.
The first two l1 deltas are negative and the second two are positive. This is because the first two training examples have a true value of 0, and even though our guess was that they were more likely 0 than 1, we weren’t 100% sure. The more we move that guess towards 0, the better the guess will be. The converse logic holds true for the third and fourth inputs which have a true value of 1.
So what this operation does, in a very elegant way, is reward the weights by how accurate their corresponding input column is to the output. There is a penalty applied to a weight if an input contains a 1 when the true value is 0. Inputs that correctly have a 0 don’t get penalized because 0 * the penalty is 0.
pre-update weights: [[ 0.39293837] [-0.42772133] [-0.54629709]] post-update weights: [[ 0.67423821] [-0.33473064] [-0.40469539]]With this process, we go from the original weights to the updated weights. With these updated weights we start the process over again, but stay tuned for next time where we’ll see what happens in the second iteration!
View my handy Jupyter Notebook here.
Bio: Paul Singman is a freelance data scientist in NYC. Some of his favorite projects are building prediction models for Airbnb listings and Oscars winners (but not both). For more info check out his Linkedinor reach him via the miracle of email: paulesingman AT gmail DOT com.
Original. Reposted with permission.
Related:
 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏




