职场知识图谱
EDI为何如此聪明?一方面,EDI拥有精准的自然语言理解和对话能力;另一方面,利用深度学习和社交网络融合等前沿技术,EDI为每个用户构建了一张关于他们的职场知识图谱。本文首先介绍如何构建用户的职场信息图谱,这是EDI个人助理的“大脑”,后续文章将介绍如何赋予EDI自然语言理解和对话能力,让它能为主人愉快地工作,欢迎有兴趣的读者继续关注。
“The more it has, the more it’s him.” 在英剧《黑镜》第二季第一集当中,女主人公通过和机器人对话的方式怀念自己逝去的男友。借助大数据的力量,这个机器人能够从主人公男友的社交网络甚至私人邮件中抽取和整合他的个人信息、关系网络和语言习惯,构建属于这位男生的个性化知识图谱,从而实现对他惟妙惟肖的模仿——如上图台词所说,系统抓取到的信息越多,机器人模仿的语言行为就越和他本人相似。
若说《黑镜》里的机器人是基于关于用户的全方位知识图谱,那么,本文要介绍的EDI 则专注于用户的一个侧面,即用户的职场知识图谱。
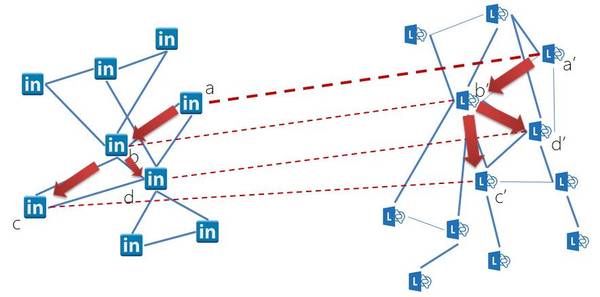
在一个机构里,我们把员工的职场知识图谱叫做EDI Graph(Enterprise Deep Intelligence Graph),图谱内的信息包括员工的部门、技能、项目、文档、时间、会议室和办公室等,其中每条信息又有各自丰富的属性,信息与信息之间也存在丰富的关联;这些信息的来源主要分为企业内部数据和互联网数据两部分,其中,企业内部数据主要包括内部网页、文档、会议记录、员工基本资料等数据,互联网数据则主要包括维基百科、学术论文、LinkedIn等公开数据。如何将来自公司内部、社交网络、Web等不同来源的异构数据进行梳理和融合、构成一张完整的职场知识图谱,这是构建EDI Graph的关键技术。只要有了图谱,就能构建EDI Bot,让这个昵称为EDI的机器人拥有“大脑”,能进行理解和分析,了解每个员工的专长以及从事的工作内容,成为员工贴心的个人助理。
信息融合
“EDI, where is BJW1?”
对于同一件事,人们往往会有不同的表达,这是人与机器的一大不同。举例:“BJW1”是英文“北京微软西1号楼“的简称,但人们在不同情境下可能还有其他表达方式,比如“BJW-1”、“Beijing West 1”、“Microsoft Tower 1,Beijing,China”以及“微软1号楼”等,这些表达上的差异无法用简单的字符串匹配或缩写匹配的方式来完成相似度的计算。那么,EDI该如何知晓它们所指的其实是同一个地点呢?
“Hi EDI, schedule a meeting with David now.”
得到不同表达的相似度之后,如何精准对应也是一门学问。例如,只要给个人助理EDI发送一条非常简洁的信息“帮我和David订个会议室”,EDI就能帮助员工准确预订好会议室。然而只要打开微软员工目录,就会发现名为David的员工大约有两千名,EDI如何分辨他们并从中确定要和用户开会那个David究竟是哪一个呢?要知道,这两千位名为David的员工,有些位于同一部门,甚至职务也都相同,这时,单单通过机器翻译得到的属性相似度,可能无法做出正确的对应。
精确匹配的突破口在于不同David的职场知识图谱,其网络结构也是不同的,我们使用协同训练(Co-Training)的方法,迭代地进行图结构信息的匹配。在每一轮迭代中,首先利用当前已匹配的实体对,更新神经网络翻译模型,并利用更新后的模型完成属性间的相似度计算;同时,根据当前已匹配节点计算待匹配节点的公共相邻节点对,通过结合属性匹配和图结构,可以得到新的匹配集合,如此迭代直到收敛。


 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏