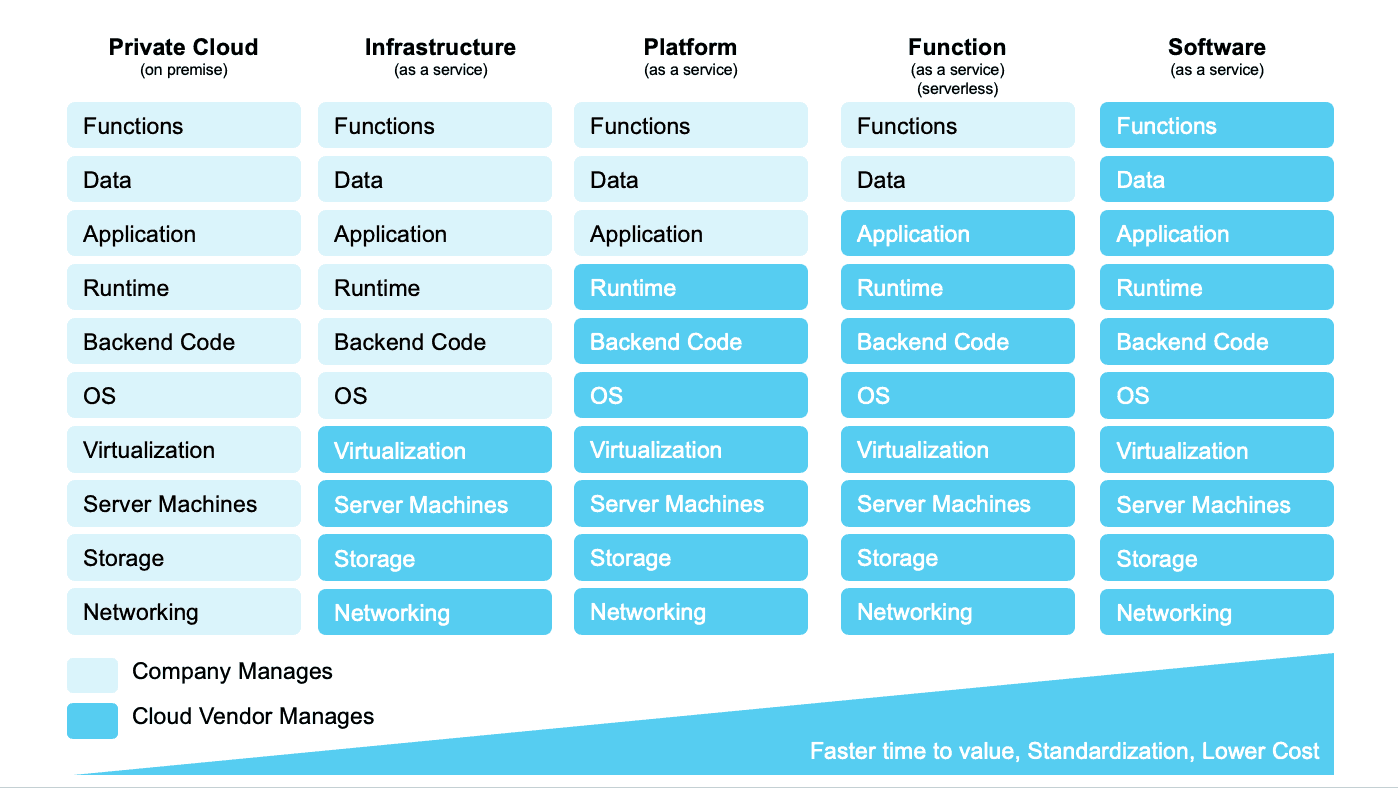
Understanding Cloud Vendor offerings and big data systems can be very confusing. The same service may have multiple names across Cloud Vendors and, to complicate things even more, each Cloud Vendor has multiple services that provide similar functionality. However, the Cloud Vendors big data offerings align to a common architecture and set of workflows.
Each big data offering is set up to receive high volumes of data to be stored and processed for real-time and batch analytics as well as more complex ML/AI modeling. In order to provide clarity amidst the chaos, we provide a two-level taxonomy. The first-level includes five stages that sit between data sources and data consumers: CAPTURE, STORE, TRANSFORM, PUBLISH, and CONSUME. The second-level taxonomy includes multiple service offerings for each stage to provide a consistent language for aligning Cloud Vendor solutions.
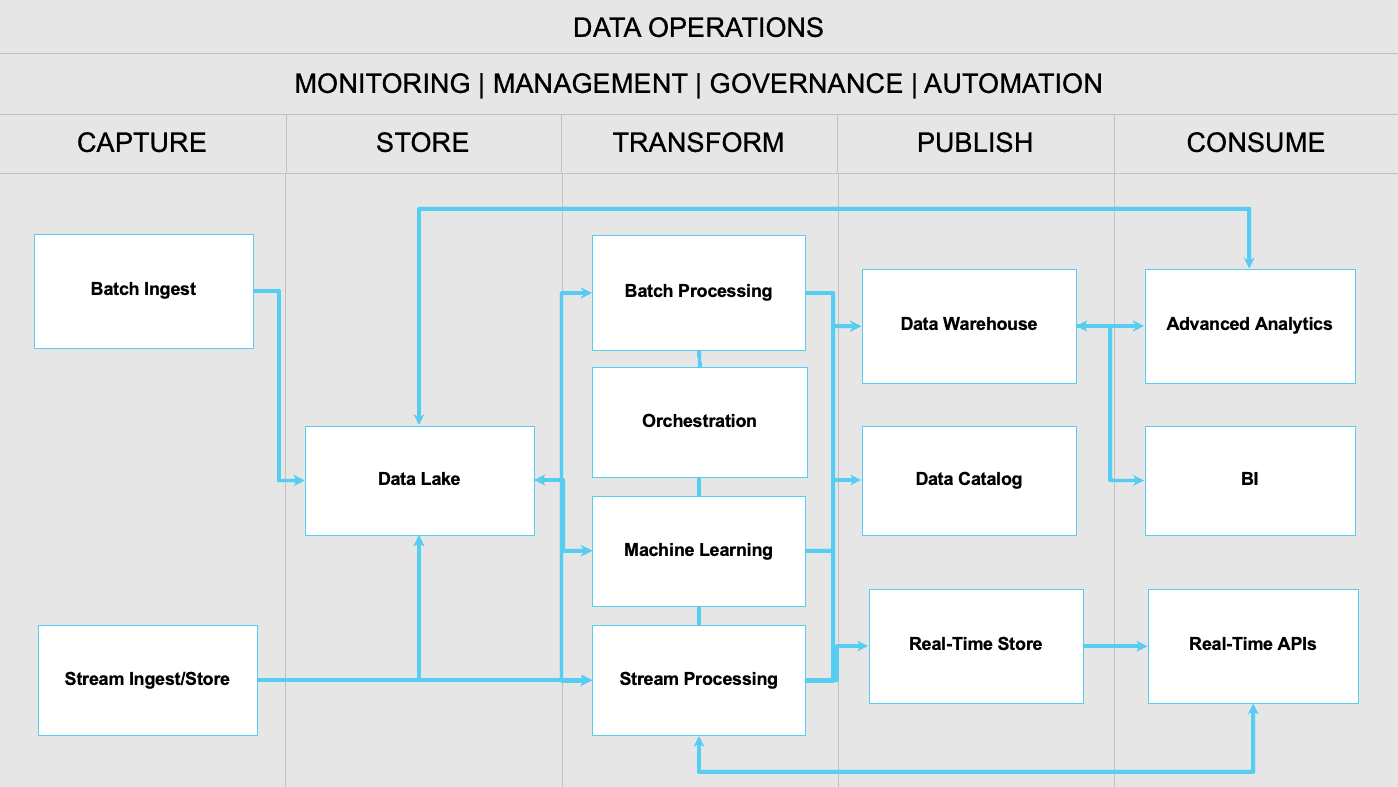
The following sections provide details for each stage and the related service offerings.
CAPTURE
Persistent and resilient data CAPTURE is the first step in any big data system. Cloud Vendors and the community also describe data CAPTURE as ingest, extract, collect, or more generally as data movement. Data CAPTURE includes ingestion of both batch and streaming data. Streaming event data becomes more valuable by being blended with transactional data from internal business applications like SAP, Siebel, Salesforce, and Marketo. Business application data usually resides within a proprietary data model and needs to be brought into the big data system as changes/transactions occur.
Cloud Vendors provide many tools for bringing large batches of data into their platforms. This includes database migration/replication, processing of transactional changes, and physical transfer devices when data volumes are too big to send efficiently over the internet. Batch data transfer is common for moving on-premise data sources and bringing in data from internal business applications, both SaaS and on-premise. Batch data can be run once as part of an application migration or in near real-time as transactional updates are made in business systems.
The focus of many big data Pipeline implementations is the capture of real-time data streaming in as an application clickstream, product usage events, application logs, and IoT sensor events. To properly capture streaming data requires configuration on the edge device or application. For, example, collecting clickstream from a mobile or web application requires events to be instrumented and sent back to an endpoint listening for the events. This is similar with IoT devices, which may also perform some data processing on the edge device prior to sending it back to an end point.
STORE
For big data systems the STORE stage focuses on the concept of a data lake, a single location where structured, semi-structured, unstructured data and objects are stored together. The data lake is also a place to store the output from extract, transform, load (ETL) and ML pipelines running in the TRANSFORM stage. Vendors focus on scalability and resilience over read/write performance. To increase data access and analytics performance, data should be highly aggregated in the data lake or organized and placed into higher performance data warehouses, massively parallel processing (MPP) databases, or key-value stores as described in the PUBLISH stage. In addition, some data streams have such high event volume, or the data are only relevant at the time of capture, that the data stream may be processed without ever entering the data lake.
Cloud Vendors have recently put more focus on the concept of the data lake, by adding functionality to their object stores and creating a much tighter integration with TRANSFORM and CONSUME service offerings. For example, Azure created Data Lake Storage on top of the existing Object Store with additional services for end to end analytics pipelines. Also, AWS now provides Data Lake Formation to make it easier to set up a data lake on their core object store S3.
TRANSFORM
The heart of any big data implementation is the ability to create data pipelines in order to clean, prepare, and TRANSFORM complex multi-modal data into valuable information. Data TRANSFORM is also described as preparing, massaging, processing, organizing, and analyzing among other things. The TRANSFORM stage is where value is created and, as a result, Cloud Vendors, start-ups, and traditional database and ETL vendors provide many tools. The TRANSFORM stage has three main data pipeline offerings including Batch Processing, Machine Learning, and Stream Processing. In addition, we include the Orchestration offering because complex data pipelines require tools to stage, schedule, and monitor deployments.
Batch TRANSFORM uses traditional extract, TRANSFORM, and load techniques that have been around for decades and are the purview of traditional RDBMS and ETL vendors. However, with the increase in data volumes and velocity, TRANSFORM now commonly comes after extraction and loading into the data lake. This is referred to as extract, load, and transform or ELT. Batch TRANSFORM uses Apache Spark or Hadoop to distribute compute across multiple nodes to process and aggregate large volumes of data.
ML/AI uses many of the same Batch Processing tools and techniques for data preparation and for the development and training of predictive models. Machine Learning also takes advantage numerous libraries and packages to help optimize data science workflows and provide pre-built algorithms. Big data systems also provide tools to query continuous data streams in near real-time. Some data has immediate value that would be lost waiting for a batch process to run. For example, predictive models for fraud detection or alerts based on data from an IoT sensor. In addition, streaming data is commonly processed, and portions are loaded into a data lake.
Cloud Vendor offerings for TRANSFORM are evolving quickly and it can be difficult to understand which tools to use. All three Cloud Vendors have versions of Spark/Hadoop that scale on their IaaS compute nodes. However, all three now provide serverless offerings that make it much simpler to build and deploy data pipelines for batch, ML and streaming workflows. For example, AWS EMR, GCP Cloud Data Proc, and Azure Databricks provide Spark/Hadoop that scale by adding additional compute resources. However, they also offer the serverless AWS Glue, GCP Data Flow, and Azure Data Factory which abstract away the need to manage compute nodes and orchestration tools. In addition, they now all provide end-to-end tools to build, train, and deploy machine learning models quickly. This includes data preparation, algorithm development, model training algorithm, and deployment tuning and optimization.
PUBLISH


 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏