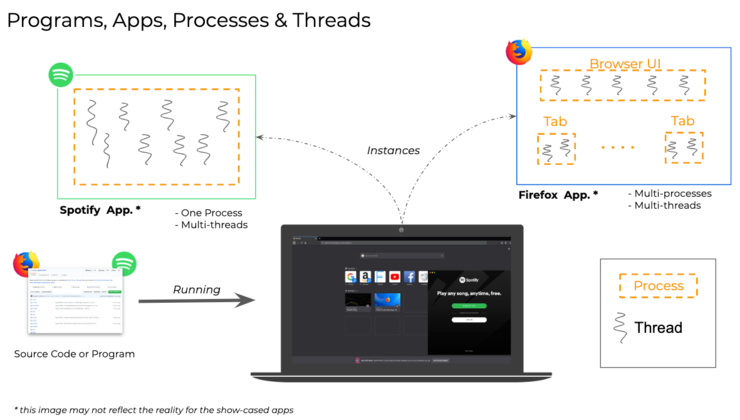
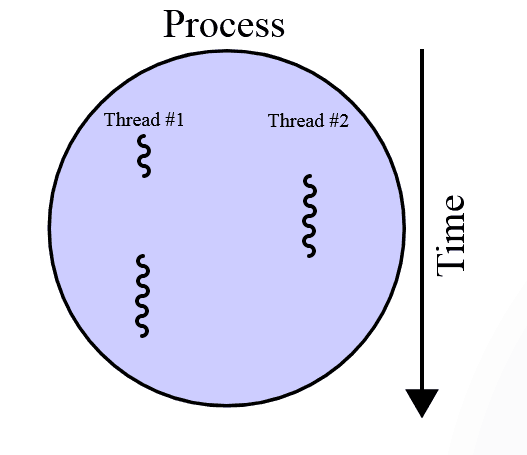
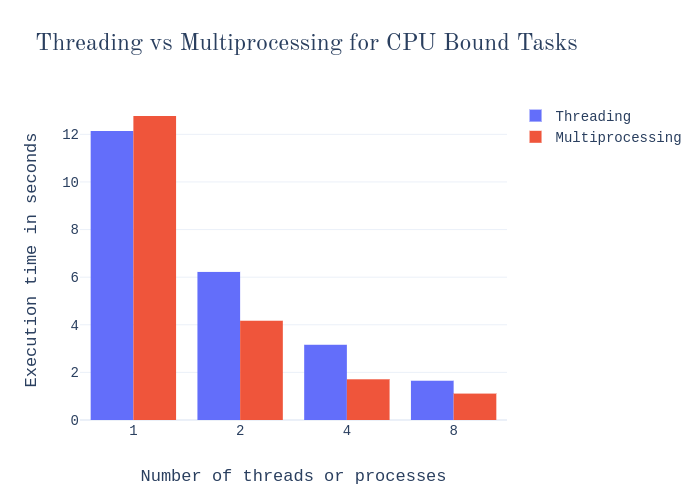
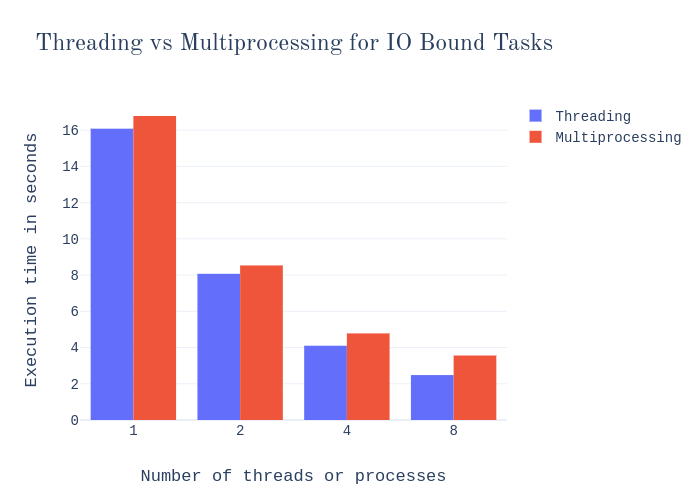
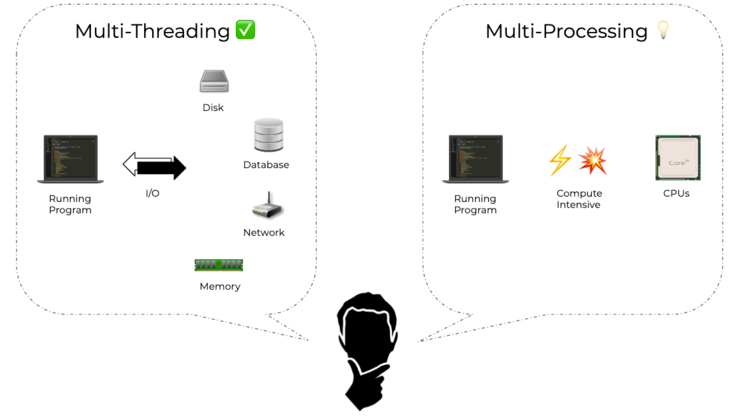
现在你可能会想,「我的数据管道看起来与此有些不同;我有一些任务并不真正适合这个通用框架。」不过,在这里你应该考虑的因素是:
你的任务是否有任何形式的 IO
IO 是否是程序的瓶颈
你的任务是否取决于 CPU 的大量计算
考虑到这些因素,再加上上面的要点,你应该能够做出决定。另外,请记住,你不必在整个程序中使用单一形式的并行,而是应该在程序的不同部分使用不同的并行。
现在我们来看看数据科学家可能面临的两个常见场景,以及如何使用并行计算来加速它们。
场景 1:下载电子邮件
假设你想分析自己创业公司收件箱中的所有电子邮件,并了解其趋势:谁是最频繁的发件人,电子邮件中出现的最常见关键字是什么,一周中的哪一天或一天中的哪一小时收到的电子邮件最多,等等。当然,这个项目的第一步是将电子邮件下载到你的计算机上。
首先,让我们按顺序进行,而不使用任何并行化。下面是要使用的代码,应该非常简单明了。有一个下载电子邮件的功能,它以电子邮件 ID 列表作为输入,并按顺序下载它们。这个函数一次调用 100 个电子邮件的 ID 列表。
import imaplib
import time
IMAP_SERVER = 'imap.gmail.com'
PASSWORD = 'password'
def download_emails(ids):
client = imaplib.IMAP4_SSL(IMAP_SERVER)
client.login(USERNAME, PASSWORD)
client.select
for i in ids:
print(f'Downloading mail id: {i.decode}')
_, data = client.fetch(i, '(RFC822)')
with open(f'emails/{i.decode}.eml', 'wb') as f:
f.write(data[0][1])
client.close
print(f'Downloaded {len(ids)} mails!')
start = time.time
client = imaplib.IMAP4_SSL(IMAP_SERVER)
client.login(USERNAME, PASSWORD)
client.select
_, ids = client.search(None, 'ALL')
ids = ids[0].split
ids = ids[:100]
client.close
download_emails(ids)
print('Time:', time.time - start)
所用时间:35.65300488471985 秒。
现在让我们在这个任务中引入一些并行性来加快速度。在开始编写代码之前,我们必须在线程和多处理之间做出决定。正如你目前所了解到的,当任务的瓶颈是 IO 时,线程是最好的选择。这里的任务显然属于这一类,因为它正在通过 Internet 访问 IMAP 服务器。所以我们要开始使用线程了。
我们将要使用的大部分代码将与我们在顺序案例中使用的代码相同。唯一不同的是,我们将把 100 个电子邮件 ID 的列表分成 10 个较小的块,每个块包含 10 个 ID,然后创建 10 个线程,并使用每个线程的不同块调用 download_emails 函数。我正在使用 python 标准库中的 concurrent.futures.threadpoolexecutor 类进行线程处理。
import imaplib
import time
from concurrent.futures import ThreadPoolExecutor
IMAP_SERVER = 'imap.gmail.com'
PASSWORD = 'password'
def download_emails(ids):
client = imaplib.IMAP4_SSL(IMAP_SERVER)
client.login(USERNAME, PASSWORD)
client.select
for i in ids:
print(f'Downloading mail id: {i.decode}')
_, data = client.fetch(i, '(RFC822)')
with open(f'emails/{i.decode}.eml', 'wb') as f:
f.write(data[0][1])
client.close
start = time.time
client = imaplib.IMAP4_SSL(IMAP_SERVER)
client.login(USERNAME, PASSWORD)
client.select
_, ids = client.search(None, 'ALL')
ids = ids[0].split
ids = ids[:100]
client.close
number_of_chunks = 10
chunk_size = 10
executor = ThreadPoolExecutor(max_workers=number_of_chunks)
futures = []
for i in range(number_of_chunks):
chunk = ids[i*chunk_size:(i+1)*chunk_size]
futures.append(executor.submit(download_emails, chunk))
for future in concurrent.futures.as_completed(futures):
pass
print('Time:', time.time - start)
所用时间:9.841094255447388 秒。
如你所见,线程大大加快了它的速度。
场景 2:使用 scikit learn 进行分类
假设你有一个分类问题,你想使用一个随机森林分类器。由于这是一种标准的、众所周知的机器学习算法,我们不需要重新发明轮子,而只需使用 RandomForestClassifier 即可。
以下代码用于演示。我使用助手函数 sklearn.datasets.make_classification 创建了一个分类数据集,然后在此基础上训练了一个 RandomForestClassifier。另外,我正在计时代码中完成模型拟合核心工作的部分。
from sklearn.ensemble import RandomForestClassifier
from sklearn import datasets
import time
X, y = datasets.make_classification(n_samples=10000, n_features=50, n_informative=20, n_classes=10)
start = time.time
model = RandomForestClassifier(n_estimators=500)
model.fit(X, y)
print('Time:', time.time-start)
任务花费时间:34.17733192443848 秒。


 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏