AIU人工智能学院:数据科学、人工智能从业者的在线大学。
数据科学(Python/R/Julia)数据分析、机器学习、深度学习
在职场中,有时候某些场景下,需要大量的人员信息用于分析、汇总、测试,这些人员信息不一定非的需要真实的,一个一个的去想人名、地址、邮箱等然后手动输入?这太麻烦了。
其实在it界,有很多这种工具,可以快速的产生各种测试用的数据来帮助完成相关工作。一个一个的去输入固然可以解决问题,可是100个测试数据可以手工,如果是1000个,1000万条呢?
场景
1、某公司开发了个分析软件,利用大数据分析人的住址、邮箱使用情况,但是苦于没有那么多人员信息。
2、某公司开发了个指纹签到机,需要大量的人员信息用于测试,来显示各种报表,比如迟到柱状图、早退柱状图。
需求
需要大量的人员信息,包括姓名、年龄、住址、邮箱,这些人员信息可以是虚构的,但是数量一定要充足,比如10万,100万甚至1000万条人员信息。
解决方案
使用python的faker库产生测试数据,使用xlwt用于保存产生的数据。如果需要的数据量过大,那么使用数据库保存数据。
具体步骤
1、安装python,以及faker、xlwt库。
安装python,可以去python官网下载最新的windows安装包,我装的是3.7版本。
安装faker、xlwt。在cmd命令行里输入
pip install faker xlwt
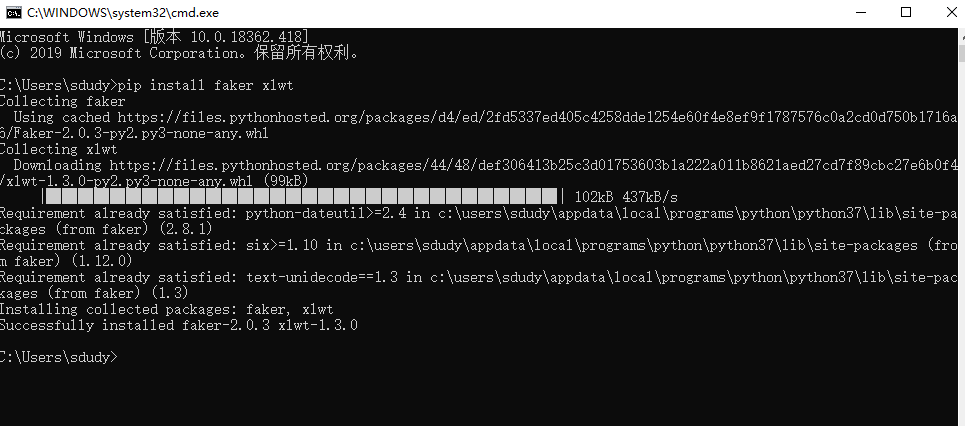
2、测试是否安装成功
输入python
输入from faker import Faker
输入f = Faker
f.name
f.address
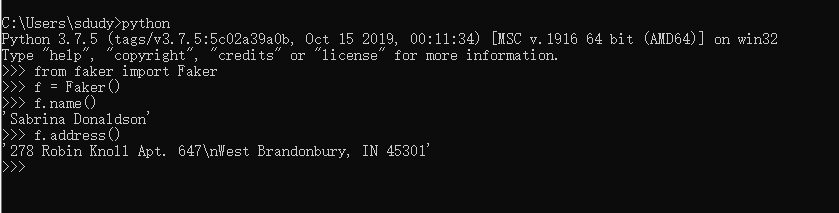
3、批量产生测试数据
我们产生100个姓名+地址出来试一下。
from faker import Faker
f = Faker(locale='zh_CN')
for i in range(1, 1000):
print(f.name)
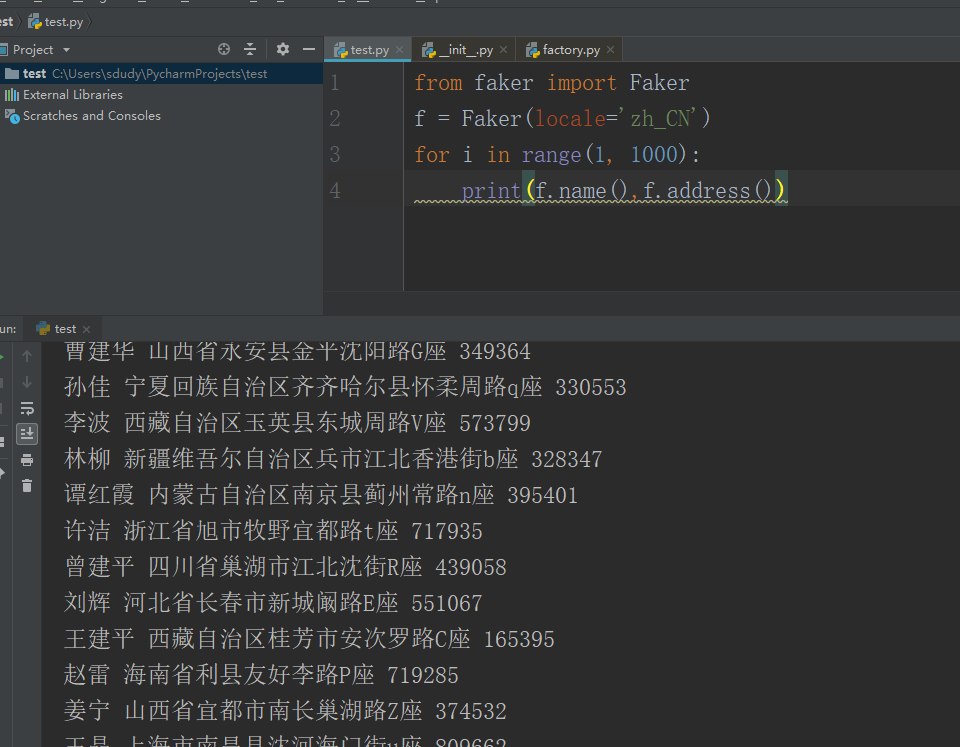
4、正式产生我们需要的数据,比如生成五万条人员信息,包括姓名、家庭住址、出生日期、邮箱信息,生成后保存到excel文件里。
生成五万行相关信息的代码
from faker import Faker
fk = Faker(locale='zh_CN')
for i in range(0,50000):
print(fk.name, fk.address, fk.date, fk.email)

关注“AIU人工智能”公众号,回复“白皮书”获取数据分析、大数据、人工智能行业白皮书及更多精选学习资料!


 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏






