AIU人工智能学院:数据科学、人工智能从业者的在线大学。
数据科学(Python/R/Julia)数据分析、机器学习、深度学习
将交叉验证的结果可视化通常有助于理解模型泛化能力对所搜索参数的依赖关系,由于运行网格搜索的计算成本高,所以通常从相对比较稀疏且较小的网格开始搜索,然后检查交叉网格搜索的结果,可能也会扩展搜索范围。
网格搜索的结果可以在cv_result_属性中找到,他是一个字典,其中保存了搜索的所有内容,这里面包含了许多网格搜索的细节,将其转化为pandas数据后更加方便查看。具体代码如下(该代码是接着上一节的代码进行的):
import pandas as pd
from IPython.display import display
#转换为DataFrame数据框
results = pd.DataFrame(grid_search.cv_results_)
#显示前10行
display(results.head(n=10))
上述代码运行后其结果如下:
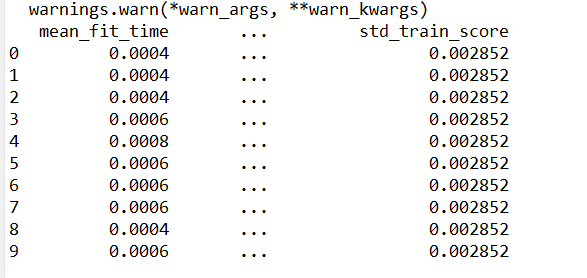
使用pandas显示网格搜索的属性结果
results中每一行对应一种特定的参数设置,对于每种参数设置,交叉验证所有划分的结果都记录了下来,所有划分的平均值和标准差也记录了下来。
由于我们搜索的是一个二维参数网格(C和gamma),所以最适合用热图可视化(我们首先提取平均验证分数,然后改变分数组的形状,坐标分别对应C和gamma):
scores = np.array(results.mean_test_score).reshape(6, 6)
#对交叉验证平均分组作图
mglearn.tools.heatmap(scores, xlabel='gamma', xticklabels=param_grid['gamma'],
ylabel='C', yticklabels=param_grid['C'], cmap="viridis")
运行结果如图:
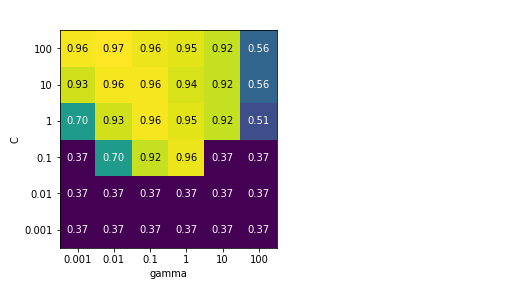
热图中的每个点对应于一次交叉验证以及一种特定的参数设置,颜色表示交叉验证的精度(浅色代表高精度,深色代表低精度)。由图可以看出,SVC对参数的设置非常ming敏感,对于许多参数设置,精度都在0.4左右;而对于其他参数设置,精度为0.96.
我们可以得出以下几点结论:首先,我们调节的参数对于获取良好的性能非常重要,示例中的两个参数(C和gamma)都很重要,通过调节他可以将精度从0.37提升到0.97,;其次,我们选择的参数范围中也可以看到输出发生了显著变化,同样重要的是,参数的范围足够大,每个参数的最佳取值不能位于图像的边界上。
下面我们来看看几组由于选择范围不合适得到的不理想的结果:
fig, axes = plt.subplots(1, 3, figsize=(13, 5))
param_grid_linear = {'C': np.linspace(1,2,6), 'gamma': np.linspace(1,2,6)}
param_grid_one_log = {'C': np.linspace(1,2,6), 'gamma': np.linspace(0,2,6)}
param_grid_range = {'C': np.linspace(0.1,3,6), 'gamma': np.linspace(0.01,2,6)}
for param_grid, ax in zip([param_grid_linear, param_grid_one_log, param_grid_range],
axes):
grid_search = GridSearchCV(SVC, param_grid, cv=5)
grid_search.fit(x_train, y_train)
scores = grid_search.cv_results_['mean_test_score'].reshape(6, 6)
#对交叉验证平均分数作图
scores_image = mglearn.tools.heatmap(scores, xlabel='gamma', ylabel='C',
xticklabels=param_grid['gamma'],
yticklabels=param_grid['C'],cmap="viridis", ax=ax)
plt.colorbar(scores_image, ax=axes.tolist)
运行后结果如下:
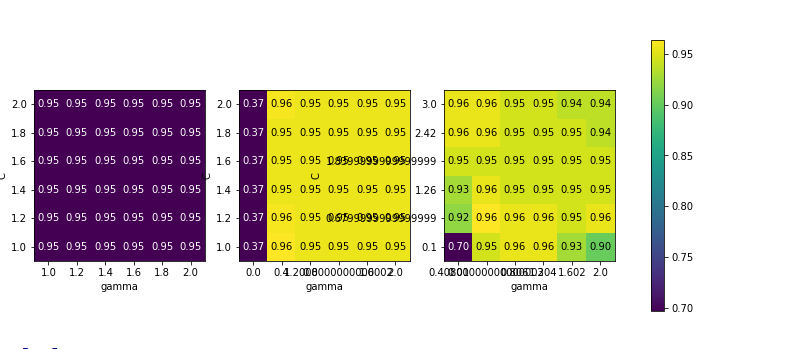
网格搜索的热图可视化
运行结果中第一张图没有任何变化,整个参数网格的颜色相同,在这种情况下,一般是由于参数C和gamma不正确的缩放以及不正确的范围导致的,但如果对不同的参数设置都看不到精度的变化,也可能是因为这个参数根本不重要。通常最好的方式是在开始设置极端值。
第二张图显示的是垂直条模式,表示只有gamma设置对精度有影响,可能意味着gamma参数的搜索范围是我们所关心的,而C参数可能并不重要。
第三张图中C和gamma对应精度均有变化,表示两个参数都比较重要。
基于交叉验证分数来调节参数网格是非常好的,也是探索不同参数的重要性的好方法,但是,不应该在最终测试集上测试不同的参数范围,只有确切知道了想要使用的模型,才能对测试集进行评估。

关注“AIU人工智能”公众号,回复“白皮书”获取数据分析、大数据、人工智能行业白皮书及更多精选学习资料!


 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏





