### 空间杜宾模型(Spatial Durbin Model, SDM)原理
#### 基础概念与公式表示
在空间计量经济学中,SDM是一种全面考虑自变量和因变量的空间溢出效应的模型。其核心在于识别并估计空间依赖性对研究现象的影响。
SDM的基本形式如下:
\[y = \beta X + \rho W y + \theta WX + u\]
其中,
- \(y\) 是n×1的因变量向量;
- \(X\) 是n×k的自变量矩阵,\(k\)为自变量数量;
- \(W\) 代表空间权重矩阵,描述了各观测点之间的空间关系(如地理位置上的邻近度);
- \(\beta\)、\(\theta\) 和 \(\rho\) 分别是对应的回归系数向量或标量;
- \(WX\) 是n×k的自变量的空间滞后项矩阵;
- \(Wy\) 表示因变量的空间滞后影响,即周围观测点对当前观测点的直接空间溢出效应;
- \(u\) 为误差项。
#### 空间权重矩阵
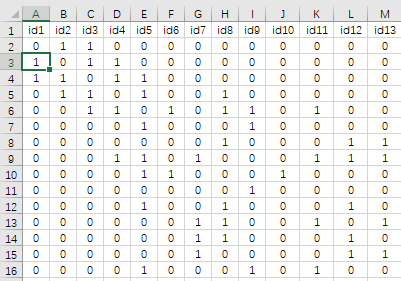
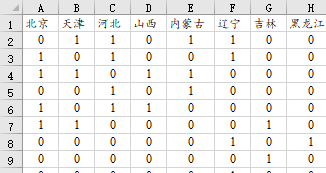
\(W\)是SDM中的关键元素之一。在上文提及的案例中,\(W\)通过二值(0或1)表示社区之间是否相邻,从而刻画了空间上的邻接关系。这种定义的空间权重矩阵称为“罗宾逊”类型,其中1代表两个区域是直接相邻的,而0则表示不相邻。
### 案例实操分析:美国哥伦布市犯罪率与房价、家庭收入的关系
#### 数据背景
假设我们正在研究美国哥伦布市49个社区中犯罪率(crime)、房价(hoval)和家庭收入(income)之间的关系,特别关注这些变量的空间溢出效应。
#### 分析步骤
1. **数据准备**:收集包含各社区的犯罪率、房价、家庭收入等信息的数据集。同时确保拥有描述社区间空间邻接性的矩阵\(W\)。
2. **模型设定**:基于SDM原理,构建模型以探索自变量(包括其空间滞后效应)对因变量(犯罪率)的影响。
3. **参数估计与解释**:
- 利用软件包如R的`spdep`或Python的`pysal`进行模型拟合。
- 解释回归系数\(\beta\)、\(\theta\)和\(\rho\)的意义,特别是空间溢出效应的大小。
4. **假设检验与诊断**:检查残差是否符合随机分布假定,验证模型设定的有效性。
5. **结果解读**:根据参数估计值分析房价(hoval)和家庭收入(income)对犯罪率的影响,并考虑其空间溢出效应如何在哥伦布市社区中传播。
#### 模型输出与结论
假设分析后发现\(\rho > 0\),表明高犯罪率的社区会通过某种机制影响邻近低犯罪率区域,导致其犯罪率上升。同样地,如果\(\beta\)和\(\theta\)显著负值,则说明房价和家庭收入提高对降低本地及周边地区的犯罪有积极空间溢出效应。
### 结论
SDM模型能够有效地捕捉变量间复杂的空间相关性,并为理解区域经济现象提供更全面的视角。对于哥伦布市案例,通过SDM分析可以揭示社区之间相互影响的模式,帮助政策制定者更好地设计干预策略以减少犯罪和促进社会经济福祉。
此文本由CAIE学术大模型生成,添加下方二维码,优先体验功能试用


 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏