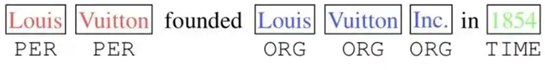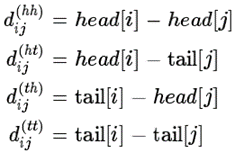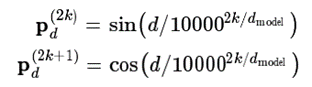1 背景 「命名实体识别」(Named entity recognition,NER)在很多 NLP 下游任务中扮演着重要角色,与英文 NER 相比,中文 NER 往往更加困难,因为其涉及到词语的切分(分词)。「Lattice 结构」被证明能够更好地利用词语信息,避免分词中的错误传播。
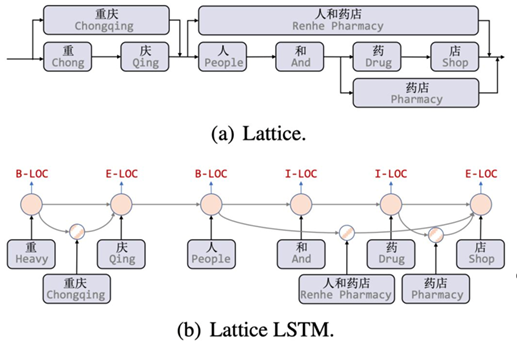
如下图 (a) 所示,我们可以通过词表来得到一个句子中的潜在词语,形成一张有向无环图,其中每个节点表示一个字符或是一个潜在词语。Lattice 包括了一个由句子中的字符与潜在词语组成的序列,其并不完全依序排列,词语的首尾字符决定了其的位置(会与字符平行)。Lattice 中的部分词语对于 NER 来说相当重要,以下图为例,「人和药店」一词可以用来区分地理实体「重庆」与组织实体「重庆人」
Lattice LSTM引入了word 结构,对于当前的字符,融合以该字符结束的所有word信息,如「店」融合了「人和药店」和「药店」的信息。对于每一个字符,Lattice LSTM采取注意力机制去融合个数可变的word cell单元,虽然Lattice LSTM有效提升了NER性能,但也存在一些缺点:
信息损失:每个字符只能获取以它为结尾的词汇信息。如对于「药」,并无法获得「人和药店」信息;
由于RNN特性,采取BiLSTM时其前向和后向的词汇信息不能共享。Lattice LSTM并没有利用前一时刻的记忆向量 ,即不保留对词汇信息的持续记忆;
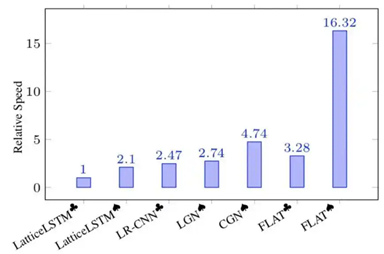
计算性能低下,不能batch并行化:究其原因主要是每个字符之间的增加word cell数目不一致;
可迁移性差:只适配于LSTM,不具备向其他网络迁移的特性;
为解决计算效率低下、引入词汇信息有损的这两个问题,FLAT基于Transformer结构进行了两大改进:
改进1:Flat-Lattice Transformer,无损引入词汇信息
改进2:相对位置编码,让Transformer适用NER任务
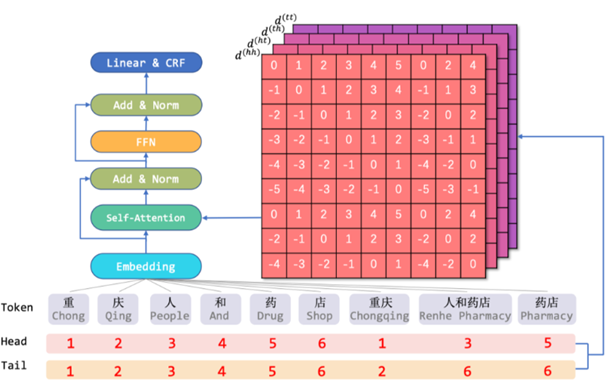
2 FLAT 2.1 将 Lattice 转化为平面结构 基于词汇表从字符得到Lattice 结构后,可以将其展成平面。Flat-lattice 可以被定义为一系列「片段」(span)的集合,每个片段对应一个 「token」、一个 「head」 与一个 「tail」,其中 token 是一个字符或词语,head 与 tail 定义该 token 的首字符与尾字符的在原始序列中的位置索引。对于字符来说,head 与 tail 是相同的。
我们可以通过一个简单的算法来将 flat-lattice 恢复到原始的结构:首先选择 head 与 tail 相同的 token,恢复字符序列;然后对于其他 token 基于 head 与 tail 构建跳跃路径。
2.2 片段的相对位置编码 从Figure 1(c)可以看出FLAT使用了两个位置编码(head position encoding 和 tail position encoding), 那么是否可以采用绝对位置编码呢?同样来自邱锡鹏老师组的论文TENER: Adapting Transformer Encoder for Named Entity Recognition给出答案:原生Transformer中的绝对位置编码并不直接适用于NER任务。TENER论文发现:对于NER任务来说,位置和方向信息十分重要。如下图所示,在Inc.前的单词更可能的实体类型是ORG,在in后的单词更可能为时间或地点。而对于方向性的感知有助于单词识别其邻居是否构成一个连续的实体Span。可见,对于距离和方向性的感知对于Transformer应用于NER任务至关重要。
但是,原生Transformer的绝对位置编码本身缺乏方向性。向量点积(inner dot)的交换性使得self-attention在方向性上有信息损失,仔细分析,BiLSTM在NER任务上的成功,一个关键就是BiLSTM能够区分其上下文信息的方向性,来自左边还是右边。而对于Transformer,其区分上下文信息的方向性是困难的。要想解决Transformer对于NER任务表现不佳的问题,必须提升Transformer的位置感知和方向感知。因此,FLAT采取XLNet论文中提出相对位置编码计算attention score,2个span之间有3种关系:相交、包含、独立。假定head和tail表示span头部和尾部位置,这些关系取决于heads和tails值。文章中使用dense vector来对他们之间的关系进行建模。
这两个span最终的相对位置编码是上述4个距离的简单非线性变换:
2.3 实验结果
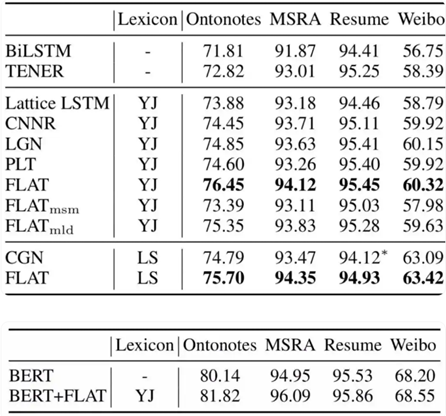
引入词汇信息的方法,都相较于baseline模型BiLSTM+CRF有较大提升。可见引入词汇信息可以有效提升中文NER性能。
采用相同词表(词向量)时,FLAT好于其他词汇增强方法;
FLAT如果mask字符与词汇间的attention,性能下降明显,这表明FLAT有利于捕捉长距离依赖;
3 总结 近年来,针对中文NER如何更好地引入词汇信息,无论是Dynamic Architecture还是Adaptive Embedding,这些方法的出发点无外于两个关键点:
如何更充分的利用词汇信息、最大程度避免词汇信息损失;
如何设计更为兼容词汇的Architecture,加快推断速度;
FLAT就是对上述两个关键点的集中体现:FLAT不去设计或改变原生编码结构,设计巧妙的位置向量就融合了词汇信息,既做到了信息无损,也大大加快了推断速度。
推荐学习书籍 《CDA一级教材 》适合CDA一级考生备考,也适合业务及数据分析 岗位的从业者提升自我。完整电子版已上线CDA网校,累计已有10万+在读~ !


 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏