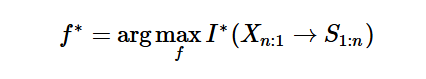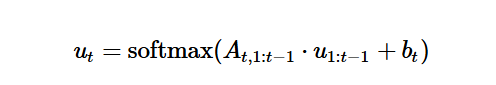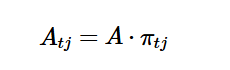这是信息论的奠基性论文。该主要论文明确地将其提出的“语义信息论”定位为香农工作的直接扩展,将基本单位从“比特”转变为“词元”,使其成为主要的灵感来源。
C. Shannon, “A mathematical theory of communication,” Bell System Technical Journal, vol. 27, no. 7, pp. 379-423, Oct. 1948.
注意力就是你所需要的一切
本文介绍了Transformer架构,它是主论文中分析的核心模型。作者提出的理论框架用于推导和解释Transformer的性能,使得这项引用对于连接理论与实践至关重要。
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” in Proc. 31st NIPS ’17, Long Beach, CA, USA, 4-9 Dec. 2017.
因果关系、反馈和有向信息
此引用至关重要,因为它引入了“定向信息”的概念,这是作者用于开发大型语言模型新度量的核心数学工具。所提出的“定向率失真函数”和“语义信息流”都是Massey工作的直接应用。
J. Massey, “Causality, feedback and directed information,” in Proc. IEEE ISIT ’90, Waikiki, HI, USA, Nov. 1990.
因果关系检验:个人观点
格兰杰因果关系是论文所基于的三个基础理论之一,如摘要中所述。论文得出结论,大型语言模型的训练过程近似于人类水平的格兰杰因果关系,这为大型语言模型所学到的能力提供了一个关键的理论解释。
C. Granger, “Testing for causality: A personal viewpoint,” Journal of Economic Dynamics and Control, vol. 2, no. 1, pp. 329-352, Jan. 1980.


 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏