RAG(Retrieval-Augmented Generation,检索增强生成)是一种特定的技术框架,其主要目标是通过检索外部知识库来提升大模型生成内容的准确性、时效性和可追溯性。
该技术的核心流程包括:首先从外部知识源(如文档、数据库等)检索与用户需求相关的信息,然后将这些“检索结果 + 用户需求”共同输入给大模型进行处理。
在RAG框架下,检索是实现生成目的的手段,它为生成提供了必要的外部知识支持,确保生成的内容既准确又有依据。
解决大模型知识过期、幻觉问题
1.1 核心原理
检索阶段:当用户提出问题后,系统会从预先设定的外部知识库中迅速找到与问题高度相关的部分信息。
增强生成阶段:接着,将检索到的信息作为参考材料,连同用户的问题一同输入到大模型中,使模型能够结合这些参考材料和自身的知识库,生成更为精确且有根据的回答。
1.2 核心价值
- 解决大模型知识过时问题:无需重新训练模型,仅需更新外部知识库,即可使模型获得最新信息。
- 提高答案的准确性和可追溯性:基于具体参考资料生成的答案减少了模型产生虚构信息的可能性,并能标明答案来源。
- 减少训练成本:相较于调整大模型,更新知识库更加经济高效,特别适用于中小企业或需要频繁更新知识的场合。
1.3 典型应用场景
- 企业内部知识库查询:例如,员工可以查询公司的报销流程等。
- 智能客户服务:根据最新的产品信息和售后政策回答客户疑问。
- 专业领域咨询:结合行业文献和法律法规提供专业的回应。
- 个人知识管理:整合个人笔记和学习资料,快速生成总结。
1.4 关键组成部分
- 外部知识库:用于存放待检索的原始信息,支持多种格式如文档、表格、PDF 和网页等。
- 检索引擎:负责快速匹配用户的问题与知识库中的内容,通常采用向量检索或关键词检索等技术。
- 大模型:基于检索结果生成自然语言回复,例如 GPT、LLaMA 或文心一言等。
- 数据处理模块:将原始知识库内容转换成适合检索的形式,如分割文档段落、创建向量嵌入等。
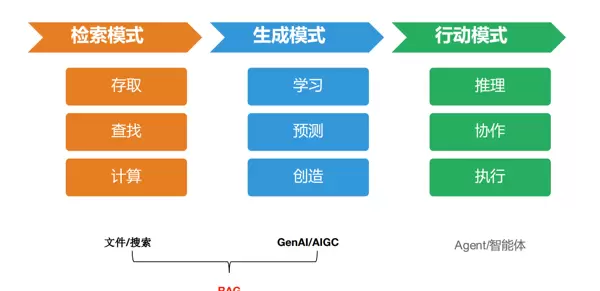
此图对 AI 技术能力进行了层次划分与关联性的可视化展示,明确了三种不同的技术模式及其与 RAG 的关系:
- 检索模式(橙色模块):涉及信息的存储、查找和计算,适用于文件管理和数据库操作等场景。
- 生成模式(蓝色模块):关注学习、预测和创造,应用于文本生成、内容创作等领域。
- 行动模式(绿色模块):侧重推理、协作和执行,例如 AI 辅助决策、多智能体合作等。
RAG 的定位被描述为“文件/搜索 + GenAI/AIGC”的组合,即利用检索模式从外部知识库获取信息,再由生成模式的大模型根据这些信息生成高质量的内容。
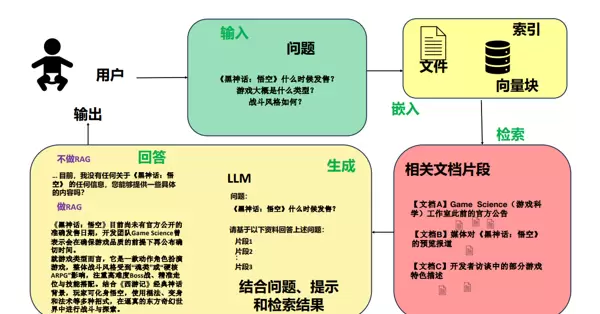
以《黑神话:悟空》为例,这张图展示了 RAG 的整个工作流程。当用户询问游戏的发布日期、类型及战斗风格等问题时,系统会从包含官方公告和媒体评论等信息的知识库中检索相关内容,随后大模型会结合这些信息生成答案。这种做法有效地克服了大模型因知识过时而无法准确回答问题的局限性,提高了回答的质量和可靠性。
“检索外部知识+大模型生成”
从另一个角度来说:
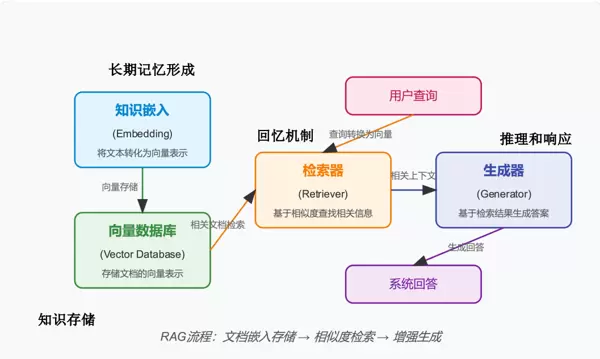
这张图从知识存储、回忆机制和推理响应三个方面解析了 RAG 的技术实现过程。其中,知识存储环节通过将文本转换为向量表示并存入向量数据库,实现了外部知识的长期保存,类似于人脑将信息储存在长期记忆中。
回忆机制(检索环节)
在用户查询时,首先将查询转化为向量,然后使用“检索器”基于相似度从向量数据库中检索相关的文档片段。这一过程类似于人们根据问题从记忆中提取相关信息。
推理和响应(生成环节)
“生成器”会利用检索到的相关上下文来生成最终的系统回答,这就好比人类基于已有的记忆进行思考并得出结论。
整个 RAG 流程可以概括为:
“文档嵌入存储→相似度检索→增强生成”
RAG 流程详解
下图结合文字,从模块分工和流程步骤两个方面进行了说明:
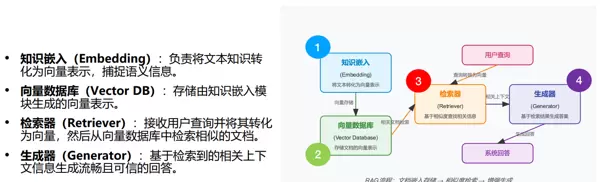
模块分工
- 知识嵌入(Embedding):将文本知识转换为向量,以捕捉语义信息,例如,“《黑神话:悟空》的发售时间”会被转换成计算机能够理解的向量形式。
- 向量数据库(Vector DB):专门用于存储这些向量,相当于一个“语义级别”的知识库,例如,所有游戏相关文档的向量都会被存储在这里。
- 检索器(Retriever):当用户询问“游戏类型是什么”时,检索器会先将问题转换为向量,然后在向量数据库中寻找最相似的文档片段,比如从媒体报告或开发者访谈的向量中匹配相关内容。
- 生成器(Generator):获取检索到的文档片段后,生成器像人类结合资料撰写答案一样,生成既流畅又准确的系统回答,例如,说明该游戏属于动作角色扮演游戏。
流程步骤
- 通过知识嵌入将文档转换为向量,并存储到向量数据库中(知识存储阶段);
- 用户发起查询后,检索器将查询转换为向量,并从向量数据库中查找相似文档(回忆机制);
- 生成器结合这些文档生成回答(推理响应);
- 最终输出系统回答。
整个流程包括“文档嵌入存储→相似度检索→增强生成”,各个模块各司其职,使 RAG 能够高效地结合外部知识和大模型的生成能力,解决大模型知识过期、回答无依据的问题。
RAG 核心步骤
2.1 索引
下图展示了 RAG 中索引构建的完整流程,即将外部知识转化为可检索的“向量索引”的过程,分为四个核心环节:
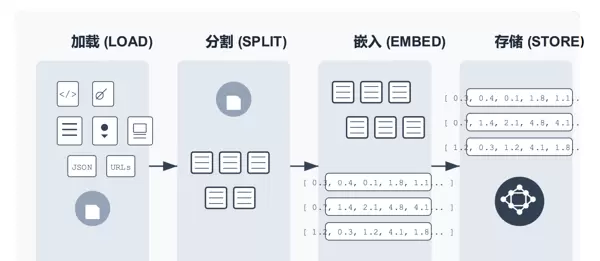
- 加载(LOAD):导入各种知识源,支持多种类型,如代码(
<//>
)、文档(文件图标)、文本(列表图标)、JSON 数据、网页 URL 等,将分散的知识“收集”起来。
- 分割(SPLIT):将导入的知识分割成小段,以便于精确检索,例如,按照段落或语义单元进行分割,就像将一本书拆分为章节和小节,便于后续处理。
- 嵌入(EMBED):使用嵌入模型将每个文本片段转换为向量。这些向量能够捕捉文本的语义信息,例如,“游戏发售时间”和“上线日期”虽然表述不同,但语义相似,因此它们的向量也会非常接近。
- 存储(STORE):将向量存储到向量数据库中,形成“向量索引”。当用户提问时,系统会将问题转换为向量,并在该数据库中迅速找到语义最相似的向量对应的文本片段,实现精准检索。
简而言之,RAG 的“索引”过程通过一系列操作,将人类可理解的文本知识转化为计算机能够快速检索的“向量知识库”,为后续的“检索增强生成”奠定基础。
“加载→分割→嵌入→存储”
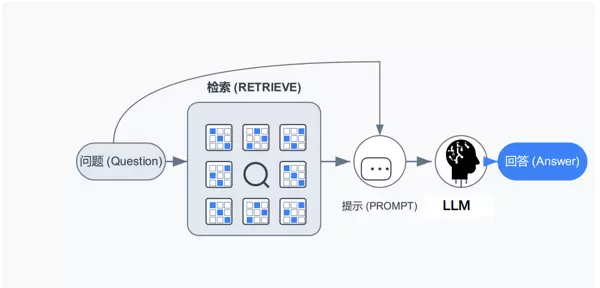
2.2 检索和生成
用户提出问题后,首先进入检索(RETRIEVE)环节,即从存储的知识片段中基于语义相似度找到与问题相关的内容。接下来,这些检索结果会与问题一起组成提示(PROMPT),输入给大模型(LLM)。最后,大模型基于提示生成回答(Answer)。这张图揭示了 RAG“通过检索外部知识增强生成”的本质:通过检索环节为大模型提供精确的外部信息,使得生成的回答更加准确、有据可依,解决了大模型知识过期或产生幻觉的问题。


 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏





