摘要
在利用在线强化学习(RL)优化高性能机器人策略的过程中,通常会遇到噪声干扰和低效的信号梯度等问题。悉尼大学与 NVIDIA 共同开发了一种进化策略(ES)——《Harnessing Bounded-Support Evolution Strategies for Policy Refinement》,作为策略梯度的一种替代方案。该方法通过有界对偶三角扰动实现局部探索,适用于策略精炼场景。文中提出了三角分布进化策略(TD-ES),结合有界三角噪声与中心秩有限差分估计器,实现了稳定且可并行的无梯度更新。采用“PPO 预训练 + TD-ES 精炼”的双阶段流程,不仅保持了早期的数据效率,还实现了后期性能的稳健提升。在多个机器人操作任务中,TD-ES 相较于 PPO 成功率提高了 26.5%,且大幅降低了方差,提供了一条简洁高效的策略精炼途径。
一、为何“高手”机器人也会失误?
强化学习(RL)使机器人能够自主试错学习新技能,无需工程师逐一编程指导。例如,PPO 等主流方法就像是为机器人配备了一位“严苛的教练”,促使它们迅速掌握基本动作,如抓取、移动等,初期进步显著。
然而,当机器人达到“准高手”水平——例如插钉成功率超过 50%,继续提升难度增加。主要障碍在于“梯度噪声”:简而言之,PPO 依赖“梯度”来决定下一步如何调整动作,但在高水平阶段,这一“调整信号”变得既弱又混乱,类似无法清晰听到教练指令。此外,参数的微小变动可能导致性能大幅波动(即“高方差”),使得机器人训练过程中变得不稳定,甚至在原本能够完成的任务上偶尔失败。
在实际应用中,机器人哪怕取得微小的进步也价值巨大:工业生产线上,插钉成功率从 70% 提升至 90%,可以显著减少返工;仓库机器人更加稳定地开启抽屉,有助于防止货物损坏。因此,此时需要一个“精修”工具,而非从头开始的“教练”。
二、TD-ES 的核心理念:精准微调,避免盲目尝试
进化策略(ES)是解决上述问题的有效手段——它不需要复杂的梯度计算,而是通过“优胜劣汰”的原则进行优化:对当前策略施加轻微扰动,保留表现良好的部分,剔除表现不佳的部分,类似于生物进化过程中的逐步迭代。
然而,传统的 ES 存在一个缺点:扰动过于“随意”。这种随机性的参数调整往往偏离现有的良好策略,不仅无效,还可能导致性能波动。例如,高斯 ES 就像是在广阔的海洋中撒网捕鱼,虽然覆盖范围广泛,但实际上大部分努力都徒劳无功(如图 1 上半部分所示)。
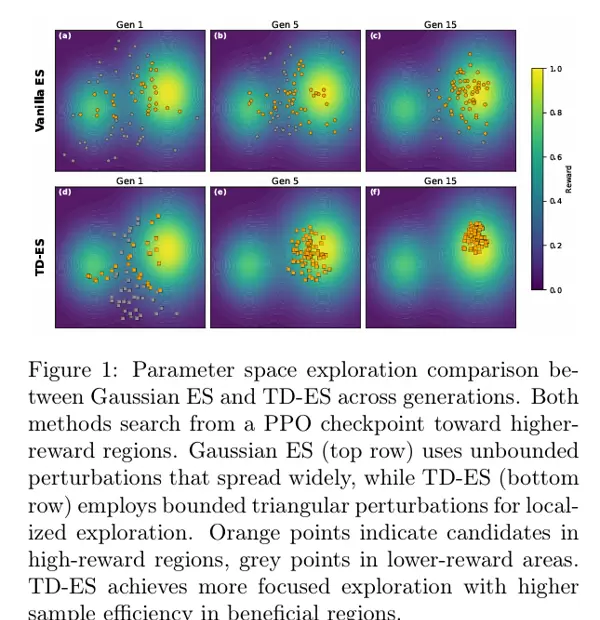
TD-ES 的创新之处在于为 ES 增加了一个“约束条件”——有界三角分布扰动:
- 限定范围:将参数调整限制在一个固定范围内,例如只能在当前值的 ±0.01 内变动,避免不必要的“盲目尝试”;
- 精准调整:三角分布的特点是“中间概率高,两侧概率低”,这意味着大多数调整都是小幅精确调整,只有少量较大的尝试,确保调整既稳定又不失探索性。
这就好比对一位高手进行技艺上的细微打磨:不必重新学习基础技能,只需在细节上不断优化——握工具的力度稍作调整、动作幅度略微改变,通过小步迭代实现质的飞跃。
三、TD-ES 如何工作?两阶段流程,简便高效
TD-ES 的理论并不复杂,其核心在于“先打好基础,再进行精修”的两阶段流程,易于工程师实施:
- 第一阶段:PPO 打基础,快速培养“准高手”
首先使用 PPO 对机器人进行“基础训练”,使其快速掌握关键技能,如插钉准确率、抽屉开启成功率等,达到 40%-60% 的成功率。此阶段强调“快速”和“稳定”,无需过分关注细节,旨在确保机器人能够胜任基本任务。
- 第二阶段:TD-ES 精修,塑造“顶级高手”
当 PPO 的提升速度放缓(即“边际效益递减”)时,切换到 TD-ES。TD-ES 的工作原理非常直观,如同对机器人进行“微调按摩”:
- 采样扰动:从三角分布中抽取一批“小幅度调整”,对现有良好策略进行微小改动,生成成对的候选策略(例如,A 策略上调一点,A' 策略下调一点,这称为“对偶采样”);
- 实战测试:让这些候选策略执行实际任务(如插钉、开抽屉),记录哪些调整带来了更好的表现;
- 择优更新:保留表现优秀的调整,将其整合到当前策略中,同时逐渐缩小调整范围,使策略更加稳定。
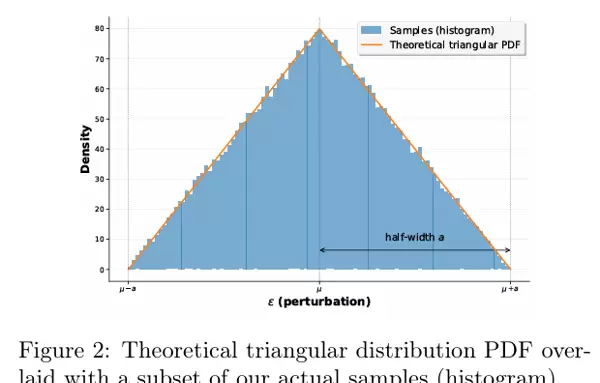
其中,“三角分布”和“有界支持”是关键:“三角分布”使调整更倾向于“小步前进”,“有界支持”则防止“大步失误”,二者结合,既确保机器人不偏离基础技能,又能持续提升(如图 2 所示,三角分布的样本集中于中部,避免极端扰动)。
更值得一提的是,TD-ES 不需要复杂的计算,所有候选策略都可以并行测试——例如,可以让 10 个经过微调的策略同时进行插钉任务,选择最佳者,效率极高,不影响实际部署。
四、实验验证:TD-ES 实力几何?
为了检验效果,研究人员使用 7 自由度的 Franka Panda 机械臂,进行了三项极具实用性的任务测试:立方体拾取(Lift-Cube)、抽屉开启(Open-Drawer)、插钉(Peg-Insert),以评估 TD-ES 是否能有效解决“高手失误”的问题。
总体表现:显著提高的成功率与大幅降低的方差
总体而言,TD-ES 在成功率方面远远超过了纯 PPO 和传统高斯 ES:
- 纯 PPO 的总体成功率为 67.2%,且波动较大;
- 高斯 ES 的表现稍好,成功率达到 73.7%,但稳定性仍不足;
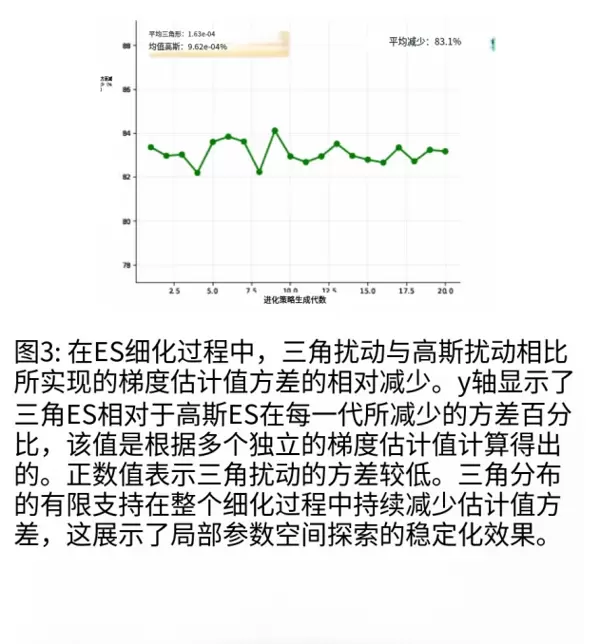
- TD-ES 的成功率达到了 85.0%,相比 PPO 提升了 26.5%,并且其波动非常小(见图 3,TD-ES 的方差远低于其他两种方法)。
单个任务分析:难度越大,TD-ES 表现越突出
在不同的任务中,TD-ES 的优势更加明显:
- 打开抽屉(Open-Drawer):这项任务主要考察稳定性,纯 PPO 的成功率为 67.0%,且波动较大(方差 31.4%),而 TD-ES 的成功率高达 97.8%,方差仅为 1.9%,几乎每次都能成功;
- 插钉(Peg-Insertion):这是一个高精度任务,孔与钉之间的间隙仅为 0.114mm,纯 PPO 的成功率为 53.8%,而 TD-ES 的成功率提升至 72.3%,并且很少出现偏斜或卡住的情况;
- 举升立方体(Lift-Cube):相对简单的任务,TD-ES 也将成功率从 75.2% 提升到了 80.6%,稳定性同样有所提高。

 图 4:机器人操纵任务示意图
图 4:机器人操纵任务示意图
(a) Lift-Cube 任务,需要将立方体抬升至目标位置;
(b) Open-Drawer 任务,需抓住把手并将抽屉拉开至少 30cm;
(c) Peg-Insertion 任务,超精密操作,孔与钉的间隙仅 0.114mm,稍有偏差即失败。
关键对比:“有界支持” 是稳定的基石
为了验证 TD-ES 的优异表现并非“运气使然”,研究者进行了消融实验,将 TD-ES 中的三角分布替换为传统的高斯分布(其他条件保持不变)。结果显示,高斯 ES 的成功率为 73.7%,而 TD-ES 则达到了 85.0%。这表明,TD-ES 的核心优势在于“有界支持”和“三角分布”,而非参数调整或其他技术。
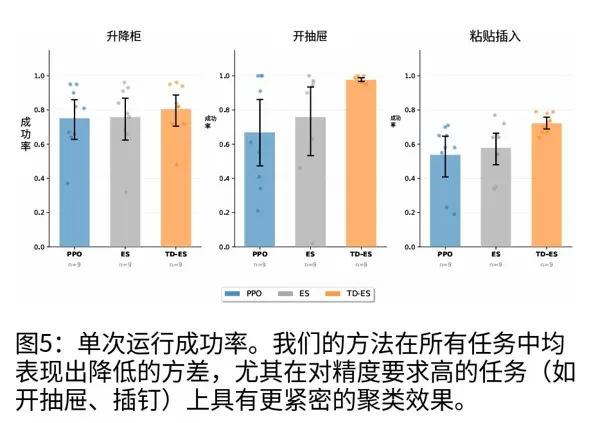
更重要的是,TD-ES 的性能极其稳定。如图 5 所示,在插钉任务中,纯 PPO 的成功率波动较大,而 TD-ES 大部分实验均集中在高成功率区间;在 80% 成功率的阈值下,TD-ES 有一半的实验能够达标,而 PPO 仅有 20%。这意味着,TD-ES 可以确保机器人在实际应用场景中的可靠性,避免偶尔的失误。
TD-ES 的价值:不仅仅是提升成功率
TD-ES 的强大之处不仅在于提高了成功率,还在于其易用性:
- 简单易部署:无需修改 PPO 的基本框架,只需在后期增加一个精炼步骤,工程师无需从零开始开发;
- 计算成本低:并行测试效率高,单台 GPU 即可运行,无需大型集群;
- 适用范围广:无论是工业装配中的插钉、抓取,还是仓储机器人中的抽屉操作,任何需要“精准微调”的任务均可使用。
未来,研究者计划探索更多的有界分布(如 Beta 分布、梯形分布),以便更好地适应机器人的执行器约束;同时,他们还将努力提高预训练的稳定性,进一步优化 TD-ES 的精炼效果。
总结:为机器人铺设一条通往高手的道路
TD-ES 的核心理念非常简单:当机器人已经具备一定的能力时,无需进行大幅度的调整,而是通过“小步、精准、有边界”的微调来逐步优化细节。TD-ES 用三角分布替换了传统的高斯分布,并通过两阶段流程平衡了效率和稳定性,最终实现了显著提高的成功率和大幅降低的方差。
对于实际应用而言,TD-ES 就像是对机器人技能的“抛光处理”——无需更换生产线或重新编程,只需添加一个精炼步骤,即可显著提升机器人的表现,使其更加稳定和可靠。这或许是未来机器人技能优化的方向:不追求复杂的理论,而是注重简单、实用、易于实施的方法。
END


 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏





