微调7B模型需要什么样的显卡配置?
算力较低的设备是否总是处于劣势?
普通人有没有机会使用高性能的H系列显卡?
如果你也曾因这些问题而在选型时犹豫不决,本文将从底层逻辑出发,结合实际应用方案,帮你彻底理清显卡选择的核心思路。
值得一提的是:普通用户同样可以接触并使用H卡资源——只要你的电脑能够联网即可实现。
而对于那些已经不再纠结于硬件选择、希望挑战更大规模模型微调训练的朋友,可以直接跳转到最后部分,了解如何以更低的成本获取顶级算力资源。
一、三大核心原则破解选卡难题
并非价格越高的显卡就越适合你。真正的关键在于:在预算范围内找到最契合需求的解决方案。请牢记以下三个决定性因素:
- 显存优先于算力:显存容量决定了你能运行多大的模型。在微调过程中,模型参数、优化器状态、梯度和激活值都需要完整加载进显存中。因此,显存是硬性门槛,直接决定是否能启动训练;而算力仅影响训练速度。
- 综合成本才是重点:许多开发者只关注显卡购买价格,却忽略了后续的折旧费用、电力消耗、散热投入、运维人力以及设备闲置带来的资源浪费。
- 云端算力正在改变格局:当高校与企业纷纷部署H100、A100等高端芯片时,个人开发者也可以通过云服务平台,以极低代价获得同等级别的计算能力。
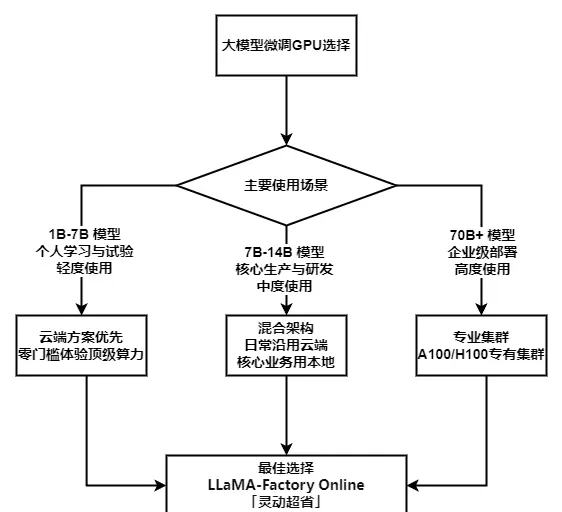
二、从个体到企业的理性决策路径
为了更清晰地理解不同场景下的最优选择,可参考如下决策流程图,它系统展示了从实际需求到具体硬件或服务模式的完整推导过程:
为何我们强烈建议优先考虑云端方案?来看一个真实案例:
某AI初创团队需对70B级别大模型进行微调,面临两种路径:
| 对比项 |
方案A:本地购置 |
方案B:LLaMA-Factory Online「灵动超省」 |
| 硬件投入 |
购买4张RTX 4090,约6万元 |
无需购置,0元初始投入 |
| 训练时间 |
5–7天 |
相当 |
| 成本结构 |
电费超1200元,持续产生折旧 |
按实际使用时长计费 |
| 维护开销 |
长期维护与散热管理 |
无额外负担 |
| 总成本估算 |
约6.5万元 |
不足方案A的三分之一 |
这一对比明确表明:在绝大多数应用场景下,云端方案在总体成本上具备显著优势。
三、新手常踩的三大误区
1. 盲目追求最新款显卡
● 错误认知:认为40系一定优于30系。
● 实际情况:对于微调任务而言,RTX 3090(24GB)往往比RTX 4070 Ti(12GB)更具实用性。显存容量过小会严重限制可操作的模型规模。
2. 忽视散热与功耗问题
● 错误认知:只需关注GPU型号本身。
● 实际情况:长时间高负载训练对散热要求极高。必须确保机箱风道合理、电源功率充足(尤其多卡配置),否则极易因温度过高导致降频甚至宕机。
3. 低估云平台的实际价值
● 错误认知:所有训练都应在本地完成。
● 实际情况:针对一次性或偶发性的大型训练任务,借助云平台按需调用H800A-80G级别的资源,远比自行采购硬件更加经济高效。
四、「灵动超省」模式:重新定义性价比
经过多种方案横向比较后,我们发现了一个被广泛忽视的高性价比选择——LLaMA-Factory Online 提供的「灵动超省」模式。
为什么它是当前最具智慧的方案?以下是详细对比:
| 对比维度 |
本地显卡方案 |
传统云服务 |
「灵动超省」模式 |
| 单小时成本 |
RTX 4090综合成本约?15/小时(含折旧+电费) |
普遍?15+/小时 |
低至2.5–5折,比自购显卡还划算 |
| 硬件性能 |
消费级显卡水平 |
H800/H100级别 |
完整释放H800A-80G性能(等效H100) |
| 资源利用率 |
闲置也产生折旧 |
空载仍计费 |
空载不计费,任务间歇自动保活 |
| 使用门槛 |
高额前期投入 |
隐藏费用较多 |
新用户赠送50元体验金,开箱即用 |
「灵动超省」模式的三大核心优势:
- 成本大幅降低:相比本地部署与传统云服务的整体开销,提供极具竞争力的价格,让顶级算力变得平民化。
- 杜绝资源浪费:支持任务暂停期间自动进入保活状态但停止计费;按需启用,绝不为闲置资源买单;高峰期自动切换极速通道,保障关键任务流畅执行。
- 性能无缩水:完整发挥H800A-80G(相当于H100)的全部性能;支持SSH远程连接,操作体验如同本地机器;训练效果媲美数十万元硬件投入;配备可视化界面,进度实时可见。
五、按场景推荐最佳实践方案
学生及个人开发者:不必急于投资高端显卡。建议先利用LLaMA-Factory Online提供的体验金验证项目可行性,在掌握基础技能后,再采用「灵动超省」模式持续推进开发工作。
初创技术团队:无需斥资购买多张RTX 4090。可直接采用「灵动超省」模式,将原本用于硬件采购的资金转向数据标注、算法优化和人才引进,实现轻资产高效运营。
企业研发部门:构建混合架构体系——日常研发使用「灵动超省」控制成本并灵活扩容;核心业务模型的部署则依托自有专用集群,兼顾安全性与稳定性。
六、你的最优解是什么?
经过全面分析与横向对比,结论已十分清晰:
- 零成本入门首选:领取LLaMA-Factory Online体验金,免费使用6小时H800A-80G顶级算力,快速上手验证想法。
- 追求极致性价比:选择「灵动超省」模式,用一半的价格享受完整的H100级别性能。
- 长期稳定需求:结合「灵动超省」与「极速尊享」模式,根据任务重要性智能分配资源,实现效率与成本的最佳平衡。
现在,是时候彻底告别“选卡焦虑”,迈出高效训练的第一步了。


 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏





