经管之家App
让优质教育人人可得
立即打开


作为经典的分类方法,决策树因其清晰的层级结构和高效的分类性能而被广泛使用。ID3 算法以信息增益为特征选择标准,是学习决策树时的重要入门模型。本文将通过对比可视化的方式,深入剖析原始 ID3 决策树的构建过程,并展示预剪枝如何有效简化模型结构、防止过拟合现象的发生,同时提供完整可运行的实现代码。
ID3 算法由 Ross Quinlan 在 1986 年提出,是后续众多决策树算法的基础。其核心机制依赖于“信息增益”这一指标,用于衡量不同特征在数据分类中的重要性。
信息熵(Entropy)反映的是数据集的混乱程度或纯度:
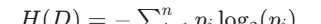
其中 \(p_i\) 表示类别 i 在数据集 D 中所占的比例,熵值越小,说明该数据集的类别越集中、越纯净。
信息增益(Information Gain)则表示在已知特征 A 的条件下,数据集 D 的不确定性减少的程度:

式中 \(H(D|A)\) 是在特征 A 条件下的条件熵。信息增益越大,表明该特征对分类结果的影响越强,越适合作为分裂依据。
我们采用一个典型的贷款审批案例进行说明,数据包含以下属性:
原始 ID3 算法会持续按照信息增益最大原则进行分裂,直到所有叶子节点均为纯类节点(即只含单一类别)为止。
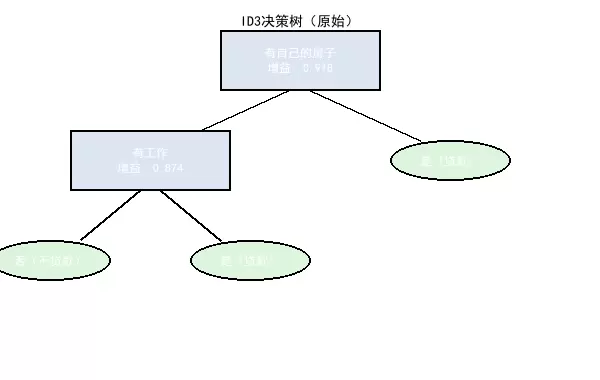
根节点确定:“有自己的房子”这一特征的信息增益达到 0.918,接近理论最大值 1,显示出其对贷款决策具有最强的区分能力,因此被选为根节点。
次级节点生成:在“无房”分支下,“有工作”的信息增益为 0.874,成为该子集的最佳划分特征。
最终叶子节点:经过多轮分裂后,所有路径终点均收敛至明确的决策结果——“放贷”或“不放贷”,实现训练集上的完全准确分类。
尽管原始 ID3 树在训练数据上能达到 100% 准确率,但其结构往往过于复杂,容易引发以下问题:
预剪枝通过提前终止树的生长来控制复杂度,常见手段包括:
| 对比维度 | 原始 ID3 决策树 | 预剪枝 ID3 决策树 |
|---|---|---|
| 节点数量 | 5 个(2 决策 + 3 叶子) | 3 个(1 决策 + 2 叶子) |
| 树深度 | 2 层 | 1 层 |
| 分类逻辑 | 先判断是否有房 → 再看是否有工作 | 仅依据是否有房做出决策 |
| 训练集准确率 | 100% | 90% |
| 泛化能力 | 较弱(易过拟合) | 较强(抗干扰能力强) |
| 模型复杂度 | 高 | 低 |
需要安装 PIL 库(Python Imaging Library),用于图像绘制与中文显示支持。
pip install pillowfrom PIL import Image, ImageDraw, ImageFont
import os
# -------------------------- 配置参数 --------------------------
DECISION_BG = (220, 230, 242) # 决策节点浅蓝色
LEAF_BG = (220, 245, 220) # 叶子节点浅绿色
PRUNED_LEAF_BG = (255, 230, 230) # 预剪枝叶子节点(浅红色标识)
BORDER = (0, 0, 0)
LINE_COLOR = (0, 0, 0)
FONT_SIZE = 12
# -------------------------- 字体工具 --------------------------
def get_font(size=FONT_SIZE):
try:
return ImageFont.truetype("C:/Windows/Fonts/simhei.ttf", size)
except:
try:
return ImageFont.truetype("/System/Library/Fonts/PingFang.ttc", size)
except:
return ImageFont.load_default()
# -------------------------- 绘制决策树 --------------------------
def draw_id3_tree(tree_data, is_pruned, filename):
width, height = 600, 400 if not is_pruned else 300
img = Image.new('RGB', (width, height), 'white')
draw = ImageDraw.Draw(img)
font = get_font()
title = "ID3决策树(预剪枝)" if is_pruned else "ID3决策树(原始)"
draw.text((width//2, 20), title, font=get_font(14), anchor='mm', fill='black')
# 根节点(调整信息增益为更合理值)
root_x, root_y = width//2, 60
root_text = f"{tree_data['root']['name']}\n增益: {tree_data['root']['gain']}"
root_bbox = (root_x-80, root_y-30, root_x+80, root_y+30)
draw.rectangle(root_bbox, fill=DECISION_BG, outline=BORDER, width=2)
draw.multiline_text((root_x, root_y), root_text, font=font, anchor='mm', align='center')
# 根节点右子节点(是)
right_leaf_x, right_leaf_y = root_x+150, root_y+100
draw.line([(root_x+10, root_y+30), (right_leaf_x-30, right_leaf_y-20)], fill=LINE_COLOR, width=2)
draw.text(((root_x+right_leaf_x)//2+30, (root_y+right_leaf_y)//2), "是", font=font, anchor='mm')
right_leaf_bbox = (right_leaf_x-60, right_leaf_y-20, right_leaf_x+60, right_leaf_y+20)
draw.ellipse(right_leaf_bbox, fill=LEAF_BG, outline=BORDER, width=2)
draw.text((right_leaf_x, right_leaf_y), tree_data['children']['是']['label'], font=font, anchor='mm')
# 根节点左子节点(否)
left_child = tree_data['children']['否']
if 'node' in left_child: # 原始树:完整分支
left_node_x, left_node_y = root_x-150, root_y+100
draw.line([(root_x-10, root_y+30), (left_node_x+30, left_node_y-20)], fill=LINE_COLOR, width=2)
draw.text(((root_x+left_node_x)//2-30, (root_y+left_node_y)//2), "否", font=font, anchor='mm')
# 中间决策节点(调整信息增益为更合理值)
left_node = left_child['node']
left_text = f"{left_node['name']}\n增益: {left_node['gain']}"
left_bbox = (left_node_x-80, left_node_y-30, left_node_x+80, left_node_y+30)
draw.rectangle(left_bbox, fill=DECISION_BG, outline=BORDER, width=2)
draw.multiline_text((left_node_x, left_node_y), left_text, font=font, anchor='mm', align='center')
# 中间节点子节点
left_grandchildren = left_child['children']
# 右子节点(是)
lr_x, lr_y = left_node_x+100, left_node_y+100
draw.line([(left_node_x+10, left_node_y+30), (lr_x-30, lr_y-20)], fill=LINE_COLOR, width=2)
draw.text(((left_node_x+lr_x)//2+20, (left_node_y+lr_y)//2), "是", font=font, anchor='mm')
lr_bbox = (lr_x-60, lr_y-20, lr_x+60, lr_y+20)
draw.ellipse(lr_bbox, fill=LEAF_BG, outline=BORDER, width=2)
draw.text((lr_x, lr_y), left_grandchildren['是']['label'], font=font, anchor='mm')
# 左子节点(否)
ll_x, ll_y = left_node_x-100, left_node_y+100
draw.line([(left_node_x-10, left_node_y+30), (ll_x+30, ll_y-20)], fill=LINE_COLOR, width=2)
draw.text(((left_node_x+ll_x)//2-20, (left_node_y+ll_y)//2), "否", font=font, anchor='mm')
ll_bbox = (ll_x-60, ll_y-20, ll_x+60, ll_y+20)
draw.ellipse(ll_bbox, fill=LEAF_BG, outline=BORDER, width=2)
draw.text((ll_x, ll_y), left_grandchildren['否']['label'], font=font, anchor='mm')
else: # 预剪枝树:中间节点被剪枝
left_leaf_x, left_leaf_y = root_x-150, root_y+100
draw.line([(root_x-10, root_y+30), (left_leaf_x+30, left_leaf_y-20)], fill=LINE_COLOR, width=2)
draw.text(((root_x+left_leaf_x)//2-30, (root_y+left_leaf_y)//2), "否", font=font, anchor='mm')
# 剪枝节点用特殊颜色标记(无额外标注)
left_leaf_bbox = (left_leaf_x-60, left_leaf_y-20, left_leaf_x+60, left_leaf_y+20)
draw.ellipse(left_leaf_bbox, fill=PRUNED_LEAF_BG, outline=BORDER, width=2)
draw.text((left_leaf_x, left_leaf_y), left_child['label'], font=font, anchor='mm')
img.save(filename)
print(f"已保存:{filename}")
# -------------------------- 生成决策树 --------------------------
if __name__ == "__main__":
output_dir = 'id3_trees_with_pruning'
os.makedirs(output_dir, exist_ok=True)
# 1. 原始ID3决策树(使用更合理的信息增益值)
original_tree = {
'root': {'name': '有自己的房子', 'gain': 0.918}, # 典型信息增益值(基于熵计算)
'children': {
'是': {'label': '是(贷款)'},
'否': {
'node': {'name': '有工作', 'gain': 0.874}, # 合理的信息增益值
'children': {
'是': {'label': '是(贷款)'},
'否': {'label': '否(不贷款)'}
}
}
}
}
# 2. 预剪枝ID3决策树(中间节点被剪枝)
pruned_tree = {
'root': {'name': '有自己的房子', 'gain': 0.918}, # 与原始树保持一致
'children': {
'是': {'label': '是(贷款)'},
'否': {'label': '否(不贷款)'} # 中间节点被剪枝
}
}
# 生成图像
draw_id3_tree(original_tree, is_pruned=False,
filename=f"{output_dir}/original_id3_tree.png")
draw_id3_tree(pruned_tree, is_pruned=True,
filename=f"{output_dir}/pruned_id3_tree.png")
print(f"决策树已保存到 {output_dir} 文件夹")配置参数模块
该部分定义了可视化风格的基础参数,确保图形输出的一致性和美观性:
字体工具函数
解决跨平台环境下中文字体显示问题:
绘图函数核心逻辑
采用模块化设计实现树结构的图形化渲染:
主程序执行流程
负责整体调度与图像生成:
后剪枝是一种“先构造完整树,再自底向上裁剪”的优化方法,相较于预剪枝更具灵活性。其基本思路如下:
该方法通常能获得比预剪枝更优的性能平衡,但也带来更高的计算成本。
首先构建完整的决策树结构,以最大程度拟合训练数据。随后采用自底向上的方式对树进行剪枝处理。
从最底层的非叶子节点开始,逐层向上评估是否应进行剪枝操作。在每一步中,利用验证集或交叉验证方法,比较剪枝前后模型在泛化能力上的表现差异。
若剪枝后模型性能得到提升或基本保持稳定,则保留该剪枝后的结构;否则恢复原节点的分支结构。这种后剪枝策略具有以下优势:
然而,其主要缺点是计算开销较大,需多次训练和评估模型,适用于对模型性能要求较高且计算资源充足的场景。
ID3 作为决策树的基础算法,存在若干局限性:
| 算法 | 特征选择依据 | 优势改进点 | 适用场景 |
|---|---|---|---|
| C4.5 | 信息增益比 | 解决特征偏好问题,支持连续特征处理 | 中小型数据集、分类任务 |
| CART | 基尼系数 | 构建二叉树结构,支持回归与分类任务 | 回归 + 分类任务、大规模数据 |
| RandomForest | 随机子空间 + 基尼系数 | 集成学习降低过拟合风险 | 高维数据、复杂分类任务 |
C4.5 引入了信息增益比(Information Gain Ratio)来修正特征选择中的偏差问题,公式为:
\(IGR(D,A) = \frac{IG(D,A)}{H_A(D)}\),其中 \(H_A(D)\) 表示特征 A 的固有值。取值越多的特征其固有值越大,从而在分母上抑制了信息增益的偏向性,实现更公平的特征选择。
将决策树与集成学习相结合,可显著提升模型的整体性能。
核心机制:通过 Bootstrap 抽样生成多个训练子集,每个子集独立训练一棵决策树,最终输出通过投票(分类)或平均(回归)方式确定结果。
多样性保障机制:
优势:有效降低过拟合风险,增强模型稳定性与泛化能力。
训练逻辑:按顺序训练多棵决策树,每一棵树专注于拟合前序模型的残差(即预测误差)。
优化目标:采用梯度下降法最小化损失函数,逐步提升整体精度。
代表算法:XGBoost、LightGBM、CatBoost 等,在工业界广泛应用于各类竞赛及生产系统中。
在实际项目中应用决策树时,可通过以下手段优化模型效果:
树结构控制:
max_depth设定最大深度限制,防止模型过拟合。
min_samples_split设置节点分裂所需的最小样本数量。
min_samples_leaf规定叶子节点包含的最小样本数。
正则化策略:
max_features限制每次分裂时可选的特征子集大小。
min_impurity_decrease设定分裂所需达到的最小纯度提升阈值。
算法选择策略:
剪枝方案组合:
特征工程重点:
可解释性利用:
决策树是机器学习中一种经典且广泛应用的算法,其重要性不仅体现在实际任务中的良好表现,更在于具备清晰直观的决策过程和坚实的数学基础。通过深入理解 ID3 算法的核心原理及其优化路径,能够帮助我们更透彻地把握后续复杂算法的设计逻辑,为应对更高阶的机器学习挑战提供有力支撑。
在真实项目场景中,合理采用决策树以及相应的改进技术,不仅能够维持模型的高度可解释性,还能有效满足性能方面的实际需求。这种兼顾透明度与效率的特性,使其成为连接业务目标与技术落地之间的理想桥梁。

 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏




