经管之家App
让优质教育人人可得
立即打开


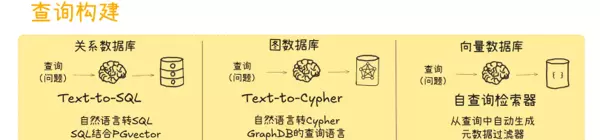
 该内容系统梳理了“自然语言转数据库操作(NL2DB)”从传统方法到前沿 Agent 方案的四代技术发展脉络,涵盖各阶段的技术架构、核心机制与典型特征,清晰展现其迭代逻辑。
该内容系统梳理了“自然语言转数据库操作(NL2DB)”从传统方法到前沿 Agent 方案的四代技术发展脉络,涵盖各阶段的技术架构、核心机制与典型特征,清晰展现其迭代逻辑。
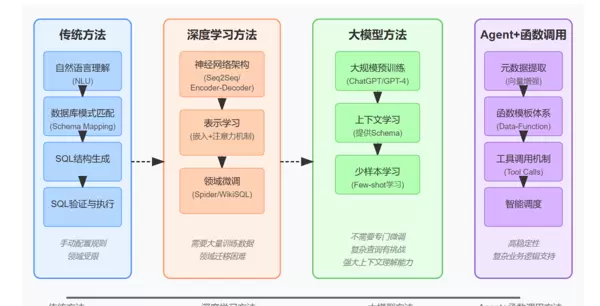
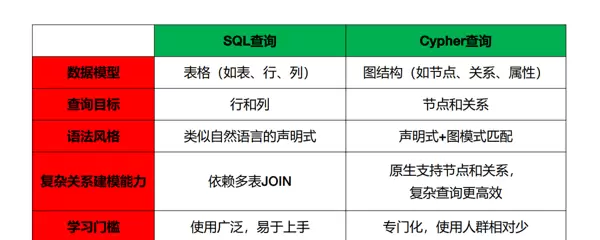
自然语言理解(NLU)→数据库模式匹配(Schema Mapping)→SQL结构生成→SQL验证与执行ORDER BY ... DESC 操作。
主要特点:实现简单、成本低,但适用范围狭窄,具有明显的**领域局限性**——一旦更换数据库结构或业务场景,需重新编写大量规则。
神经网络架构(Seq2Seq/Encoder-Decoder)→表示学习(嵌入+注意力)→领域微调(用Spider/WikiSQL数据集)大规模预训练(ChatGPT/GPT-4)→上下文学习(给数据库Schema)→少样本学习(给少量示例)元数据提取(向量增强)→函数模板体系→工具调用机制→智能调度 此部分详细描述了一个完整的 NL2SQL 系统如何将用户输入的自然语言问题转化为可执行的 SQL 查询,并返回结构化结果。整个流程遵循“知识准备→上下文检索→SQL生成→执行反馈”的闭环逻辑。
此部分详细描述了一个完整的 NL2SQL 系统如何将用户输入的自然语言问题转化为可执行的 SQL 查询,并返回结构化结果。整个流程遵循“知识准备→上下文检索→SQL生成→执行反馈”的闭环逻辑。
CREATE TABLESELECT SUM(amount) FROM orders WHERE month='2025-11'status
Vanna 是一个遵循 MIT 许可证的开源 Python 框架,专为实现自然语言到 SQL 的转换而设计,属于典型的 RAG(检索增强生成)架构。其主要作用是将用户的日常语言自动转化为可执行的 SQL 查询语句,从而显著降低数据库操作的技术门槛。借助该工具,产品经理、运营人员等非技术背景的用户无需掌握复杂的 SQL 语法,也能轻松完成数据查询并获取所需结果。
Chat2DB 是一款融合 AI 能力的通用智能 SQL 客户端与数据分析报告工具。它支持多数据库连接,能够帮助用户更高效地编写 SQL 语句、管理数据库结构、探索数据内容,并自动生成可视化报告,提升整体数据交互效率。
DB-GPT 是一个专注于数据库交互的 AI 框架,具备强大的自然语言理解能力,可用于数据库查询优化和语义解析。相关资源可通过以下链接访问:
在处理用户输入的自然语言请求前,系统需预先构建图数据库的“元知识”库,类似于 TextToSQL 中的 Schema 描述体系。该知识库存储了图结构的核心定义信息,主要包括:
Self-query Retriever(自查询检索器)是一种用于 RAG 应用场景中的智能化检索组件,常见于 LangChain 等框架中。它利用大语言模型(LLM)对用户输入的自然语言进行深度解析,从中提取出两部分内容:一是用于语义匹配的核心查询意图,二是潜在的元数据过滤条件(如时间范围、类别标签、评分阈值等)。随后结合向量数据库的语义检索能力,实现高精度的内容召回。
整个流程高度自动化,依赖 LLM 的理解能力和向量数据库的存储机制,具体步骤如下:
查询翻译是指通过提示工程(Prompt Engineering)手段,对用户输入的问题进行语义重构与优化。当原始查询存在表述模糊、含有噪声、信息不完整或未能全面覆盖目标检索维度时,需要采用重写、分解、澄清和扩展等多种策略对其进行改进,以提升后续检索阶段的准确率与覆盖率。

作为 RAG、TextToSQL 和 TextToCypher 等任务中的关键环节,查询重写旨在解决原始问题中存在的模糊性、歧义、信息缺失或表达不精确等问题。通过设计合理的 Prompt 指令引导大语言模型(LLM)对原始查询进行优化,使其更符合下游检索或代码生成模块的需求,从而提高整体系统的输出质量。例如,将“最近卖得好的产品”重写为“过去30天内销量排名前10的商品”,使语义更加明确。

面对多意图、跨领域或逻辑链条较长的复杂查询,直接处理容易导致信息遗漏或生成错误结果。查询分解技术借助大模型的能力,将这类复合型问题拆分为若干个独立、清晰且可执行的子问题,分别处理后再整合答案。
典型应用场景包括:
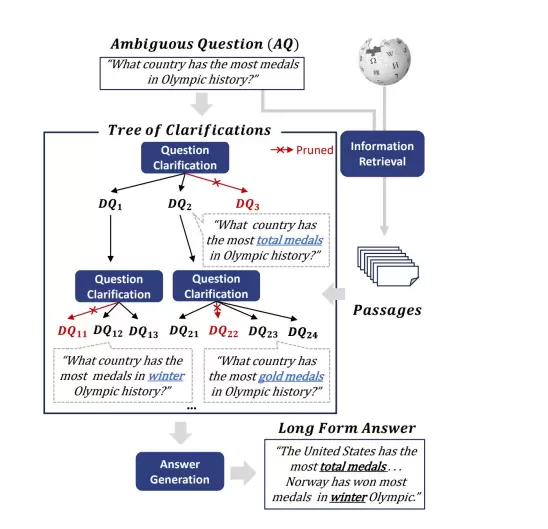
该方法通过递归方式构建“问题澄清树”,不断追问和补充上下文,逐步厘清用户的真实需求。尤其适用于初始提问过于宽泛或信息不足的情况,通过多轮交互动态完善查询条件,确保最终生成的查询语句能准确反映用户期望。
查询澄清是处理模糊、歧义或信息不完整查询的关键流程,广泛应用于 RAG、TextToSQL 等场景。该过程通过大模型(LLM)主动向用户发起追问,逐步补全缺失信息、消除语义歧义,最终将“不明确的自然语言查询”转化为“可执行的精准指令”。
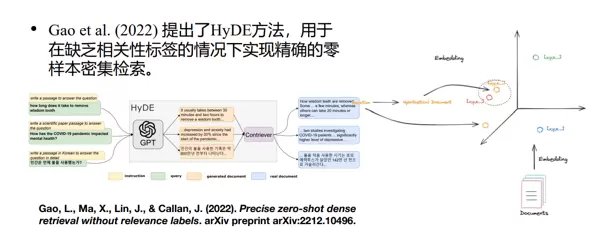
Gao et al. (2022) 提出的 HyDE 方法,旨在在缺乏相关性标注数据的情况下,实现高精度的零样本密集检索。该方法通过生成“假设性回答文档”来增强查询表示,从而提升后续检索阶段的相关性匹配能力。
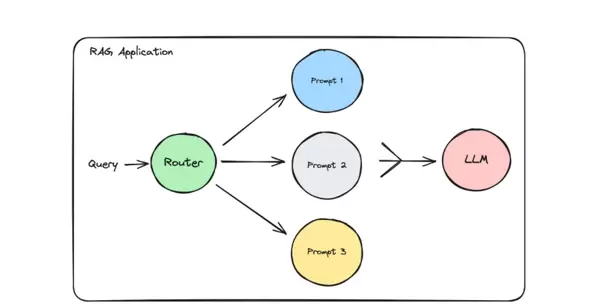
作为 RAG、TextToSQL/TextToCypher 等复杂系统的调度核心,查询路由根据用户输入的内容特征、意图和业务背景,智能地将其分发至最合适的处理单元,例如不同的知识库、检索器、数据源或生成模块。通过“分类分发、各司其职”的策略,避免统一处理带来的效率低下与结果偏差,显著提升系统响应速度与准确性。
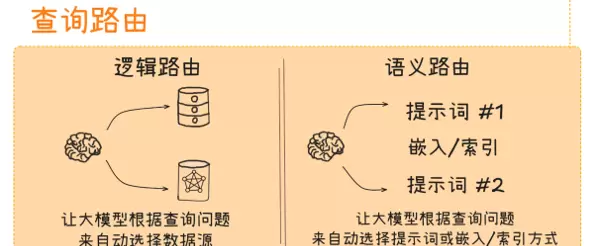
逻辑路由是一种基于预设明确规则进行查询分发的“硬性导航”机制。它依赖关键词匹配、条件判断(如 if-else 结构)等确定性逻辑,将查询定向到指定处理模块。这些规则由工程师结合业务需求、数据分布及各模块功能手动构建,具备强可解释性和高确定性。
规则制定聚焦于查询中“可量化的表面特征”,无需深入理解语义内容,常见维度包括:
| 规则ID | 匹配条件 | 路由目标 |
|---|---|---|
| R1 | 包含“销量”“销售额”“订单数”,并含有时间范围(如“2025年Q3”“近30天”) | 电商SQL生成器(对接订单库) |
| R2 | 包含“产品名称”“型号”“功能”,无统计类需求 | 产品知识库向量检索器 |
| R3 | 包含“售后”“退款”“保修” | 售后工单系统检索器 |
| R4 | 以上均未匹配 | 通用LLM对话模块 |
路由实例:
| 优势 | 局限 |
|---|---|
| 响应速度快,通常可在毫秒级完成规则匹配 | 规则维护成本高,业务变化需频繁调整规则库 |
| 可解释性强,每一步路由均有清晰依据 | 难以应对模糊或未定义场景,无匹配即失效 |
| 无需调用LLM,运行成本低 | 多个规则冲突时,优先级管理复杂 |
| 准确性高,规则明确减少主观误差 | 仅依赖表层特征,无法理解深层语义,易误判 |
语义路由是一种基于查询深层语义意图的“柔性导航”方式,利用大语言模型(LLM)或嵌入模型(Embedding Model)理解用户提问的本质含义,而非仅仅匹配关键词字符串。其核心理念是“理解意图而非字符匹配”,特别适用于复杂、模糊或多意图交织的查询分发任务。
语义路由依赖两大核心技术:“语义意图识别”与“向量相似度计算”。主要实现路径包括:
相似度计算:通过生成查询向量,并与各模块对应的向量进行比对,计算其语义相似程度;
路由决策:依据相似度结果,选取最高得分或超过预设阈值的模块作为目标处理单元;
兜底处理:当所有模块的相似度均未达到设定阈值时,请求转入默认模块,或启动问题澄清流程以获取更明确的用户意图。
| 模块名称 | 语义描述(用于生成嵌入向量) |
|---|---|
| 医疗知识库 | 涵盖疾病症状、治疗建议、药物使用说明和健康科普等内容,适用于患者咨询与医学知识普及场景。 |
| 金融数据分析模块 | 支持股票、基金、理财产品等金融产品的收益查询、数据解读与风险分析,连接专业金融数据库及外部API接口。 |
| 生活服务模块 | 提供出行规划、旅游推荐、餐饮信息、购物指南等日常生活相关服务,支持查询、推荐与预约功能。 |
| 通用闲聊模块 | 应对无具体业务指向的对话内容,如情绪交流、话题探讨、趣味互动等非任务型会话场景。 |
用户输入:“2025年Q3哪些基金收益率较高” → 系统将其转化为查询嵌入向量;
相似度对比结果显示:与“金融数据分析模块”的语义匹配度为0.92,显著高于其他模块(医疗:0.15,生活:0.23,闲聊:0.08);
基于该结果,系统将请求路由至金融数据分析模块,并调用后端数据库返回相应的收益分析数据。
用户提问:“苹果的相关数据”——若仅依赖关键词匹配,易产生歧义(可能指科技品牌或水果);
采用语义路由机制,结合历史上下文判断倾向:此前讨论“手机销量”则导向电商模块;若前文涉及“水果价格”,则进入生活服务模块;
在缺乏上下文线索的情况下,系统将发起澄清询问:“你指的是苹果公司产品还是水果苹果?”以确认真实意图。
| 优势 | 局限 |
|---|---|
| 能够理解深层次语义,有效应对模糊或多层意图的复杂查询 | 依赖大语言模型或嵌入模型,带来额外成本(如API调用、计算资源消耗) |
| 维护简便,新增或调整模块只需更新其语义描述文本 | 响应速度低于规则驱动的逻辑路由方式,因需执行向量编码与相似度运算 |
| 支持多意图识别与跨领域问题处理,扩展性强 | 可解释性较差,难以直观展示为何选择某一特定模块 |
| 适应业务快速迭代,新增功能模块仅需补充对应语义定义 | 路由准确性高度依赖模块语义描述的质量,描述不当可能导致误分发 |

 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏




